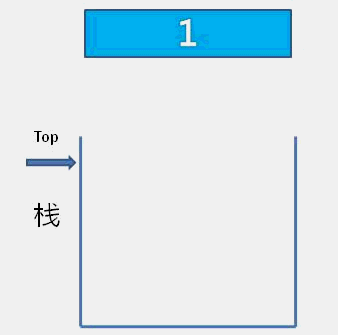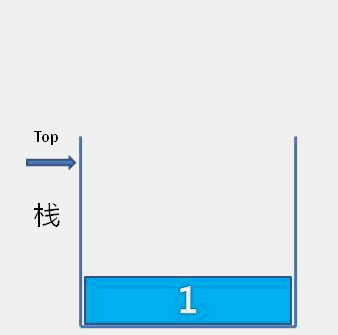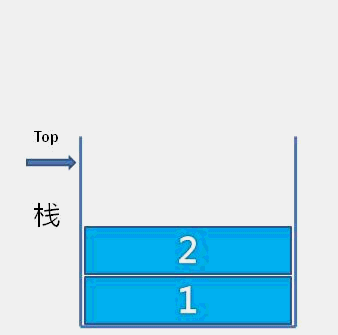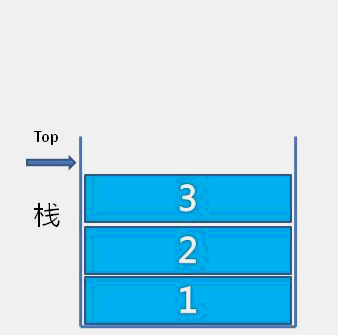
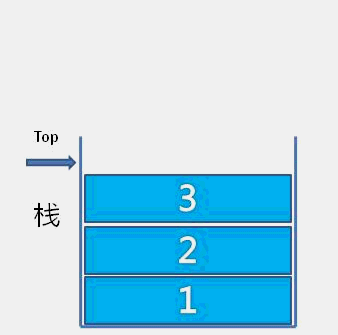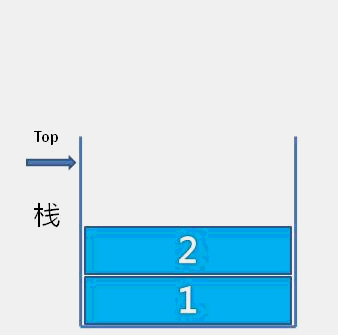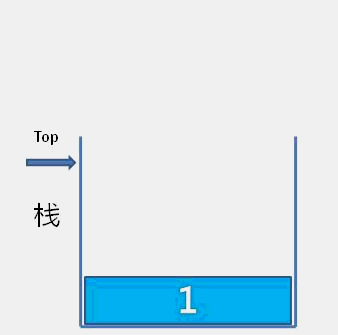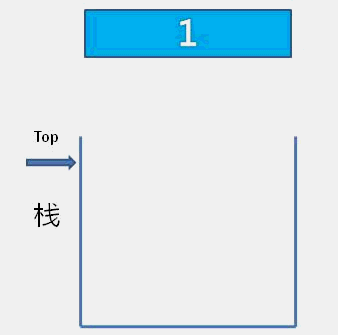
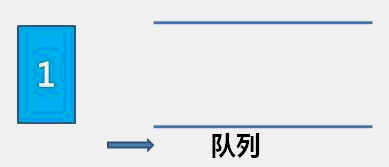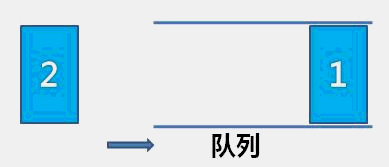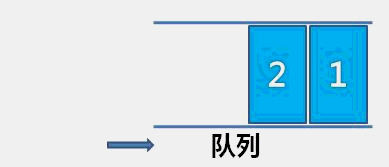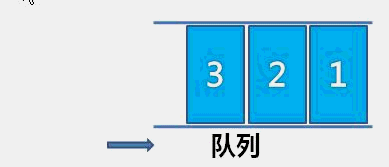
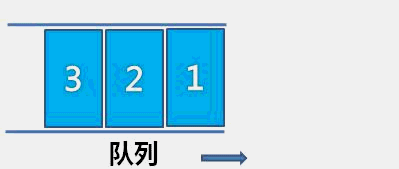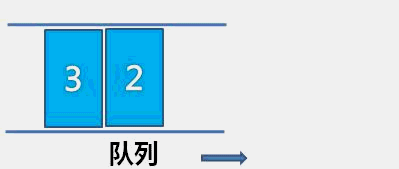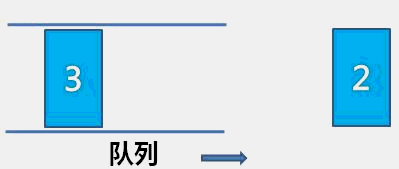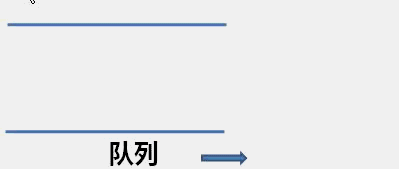
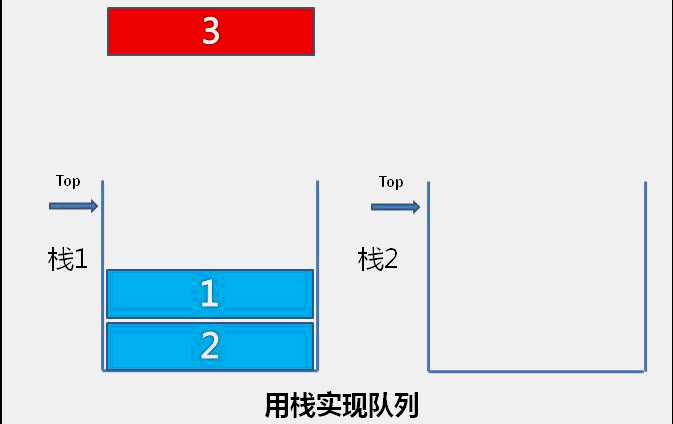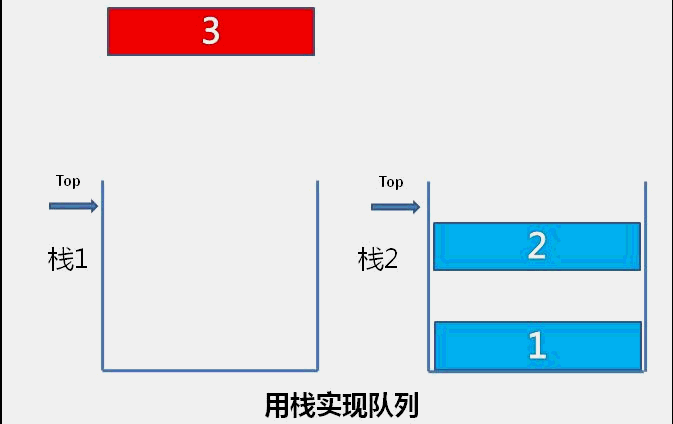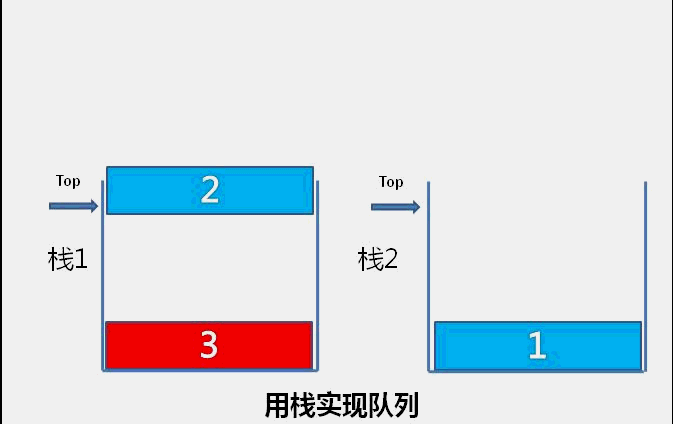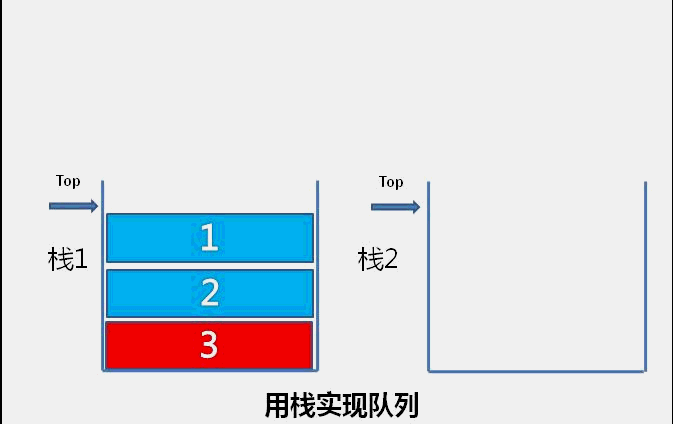
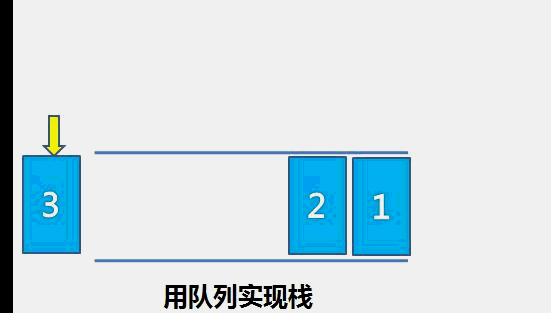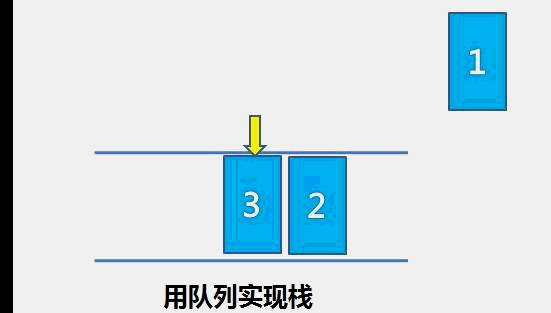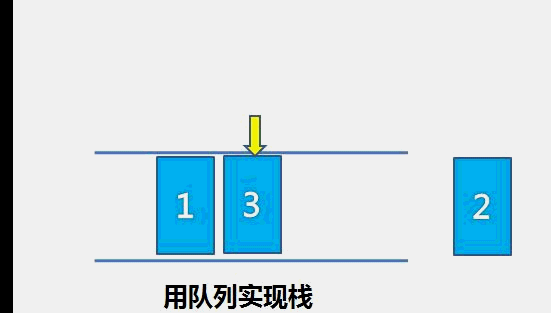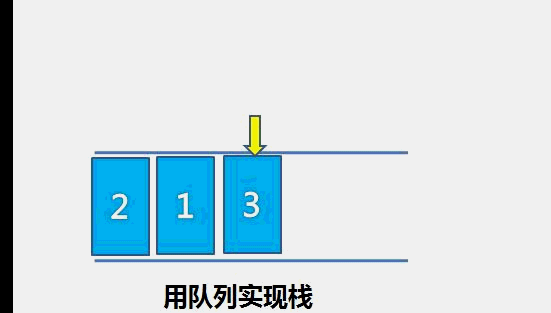
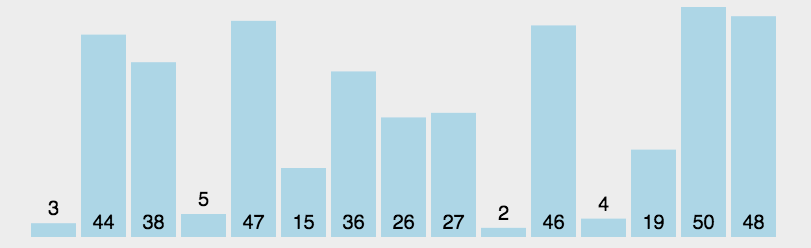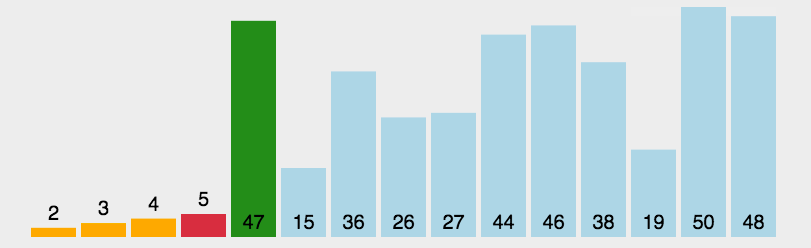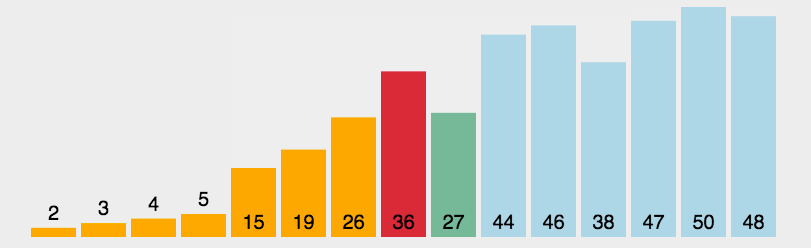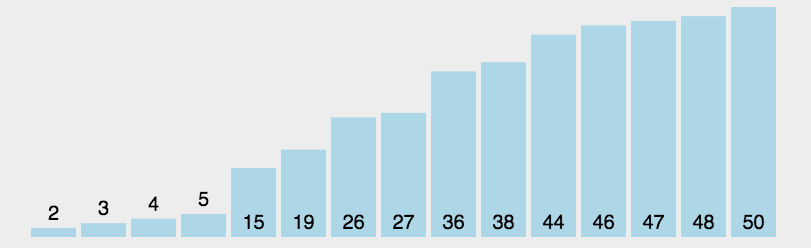
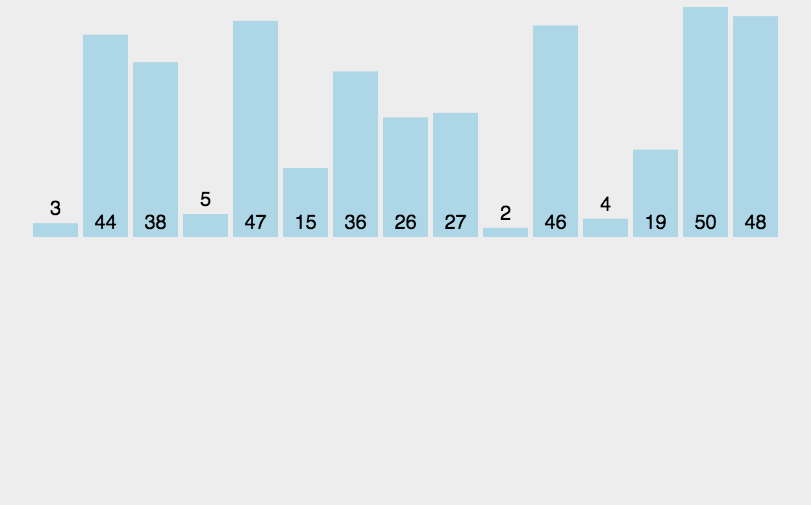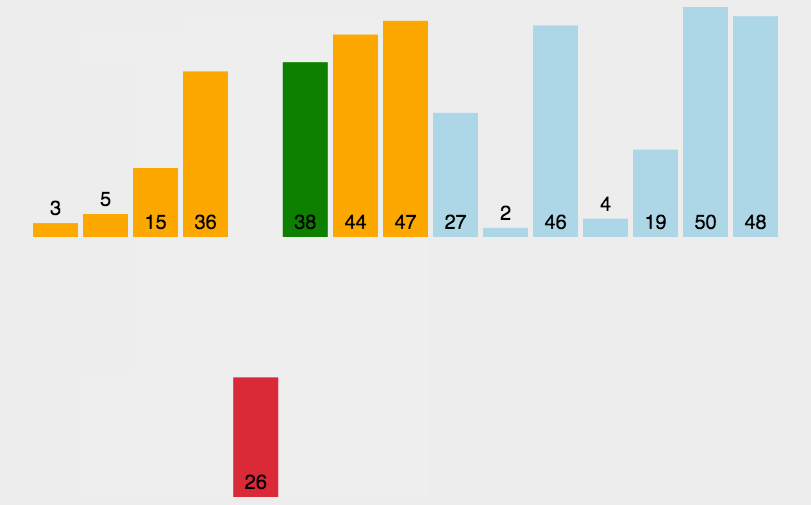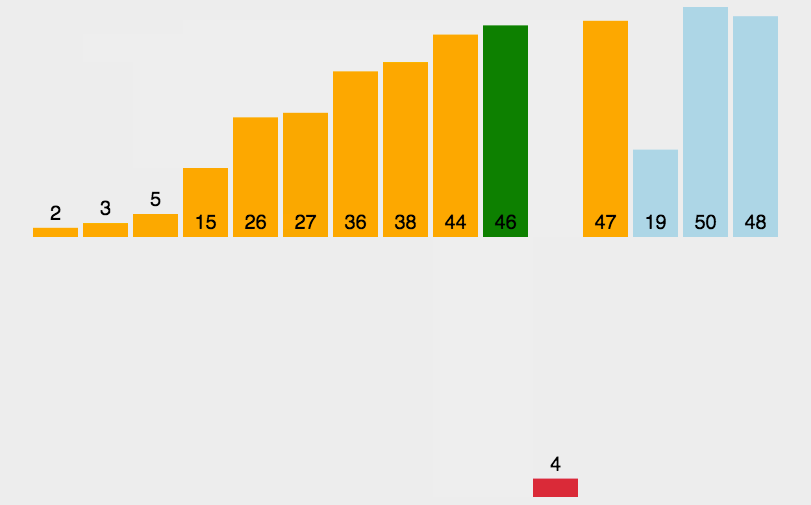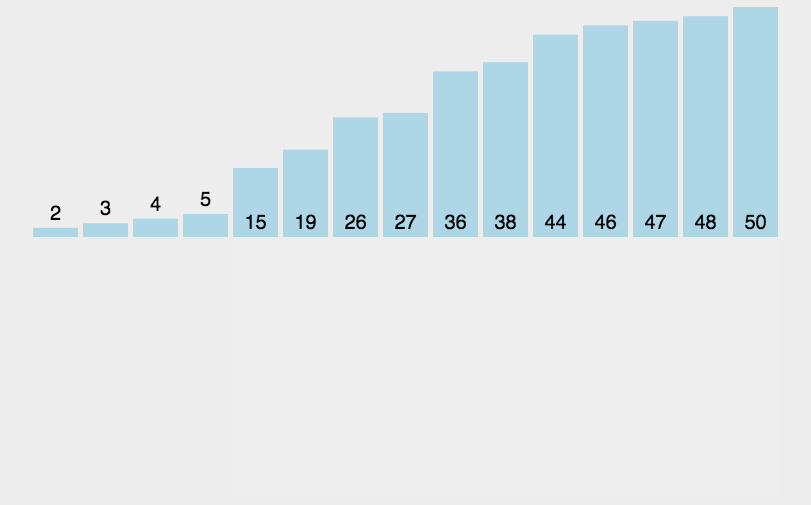
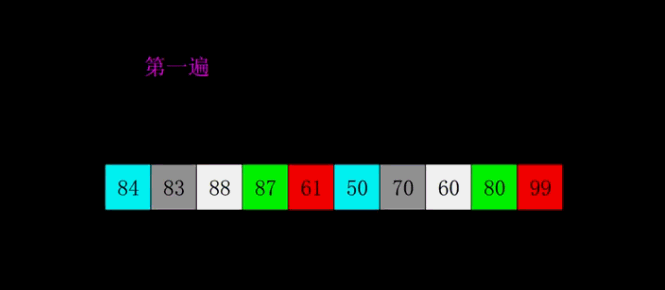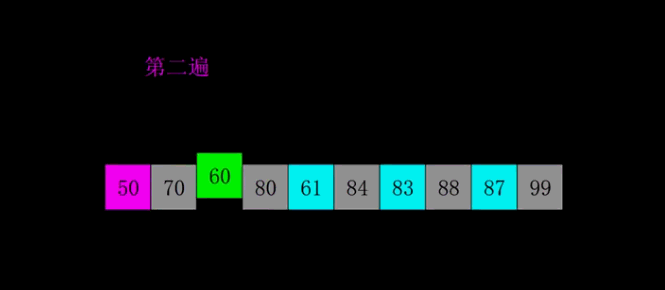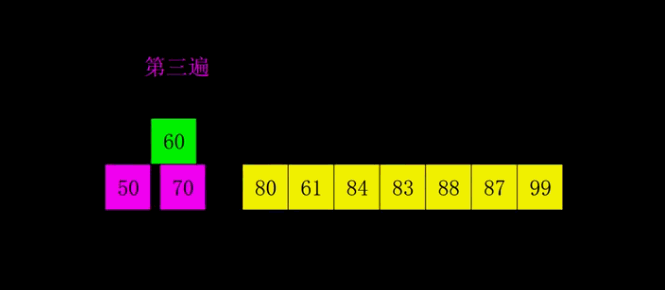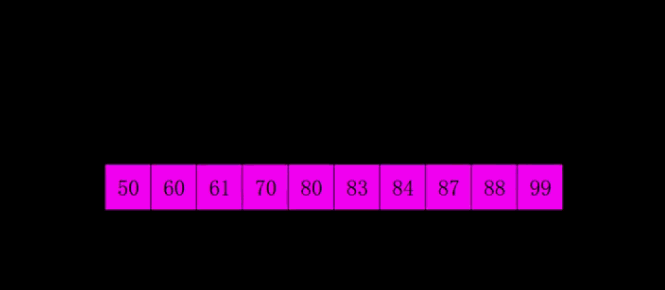
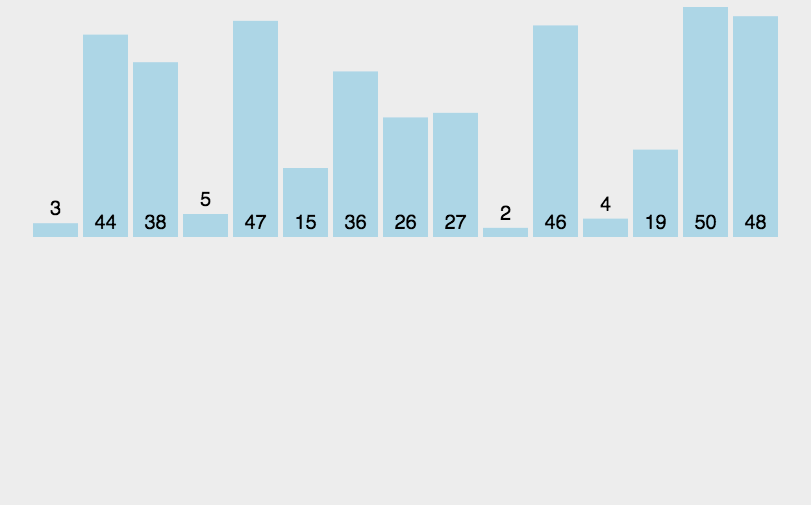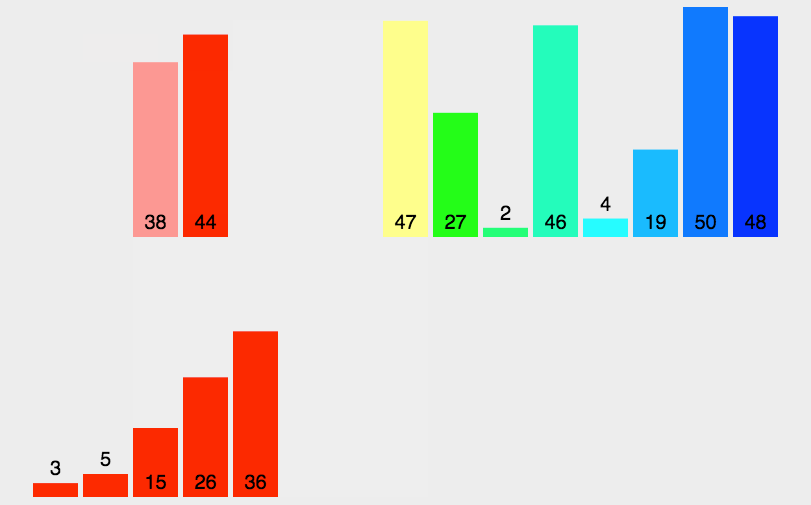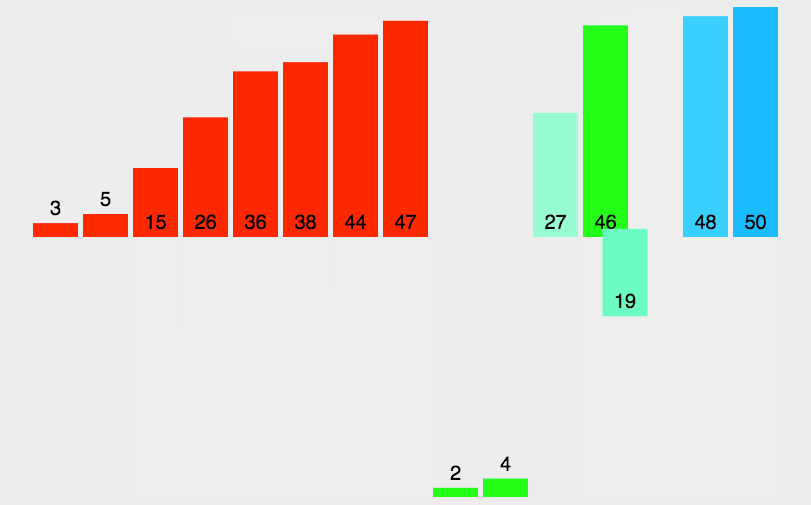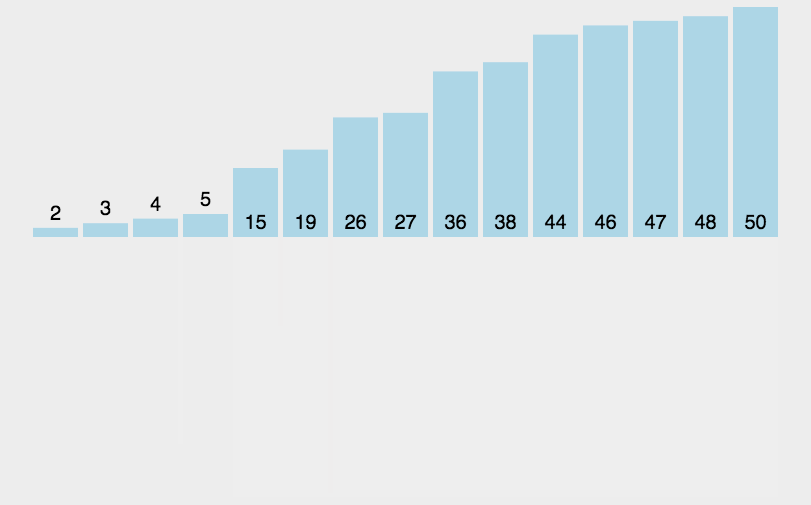
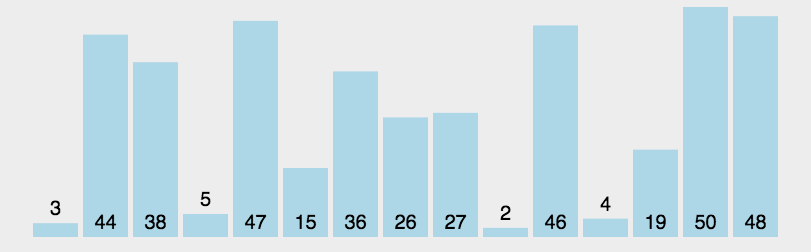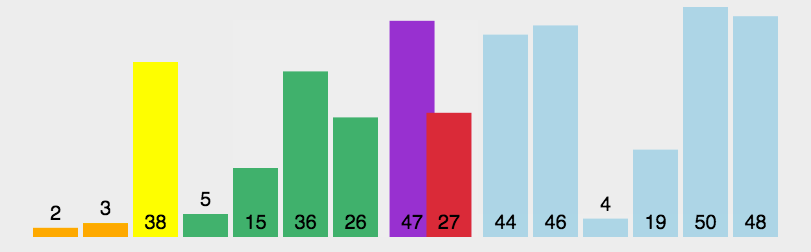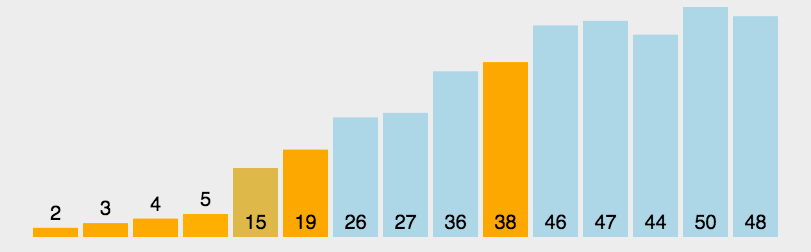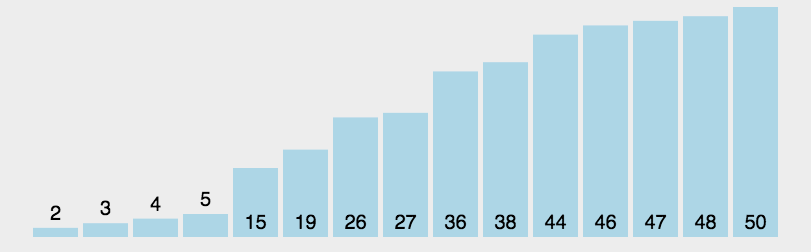
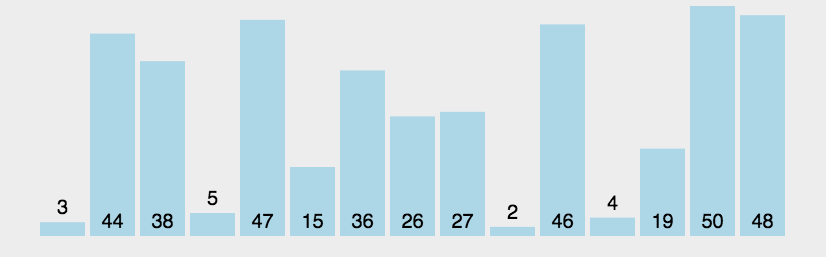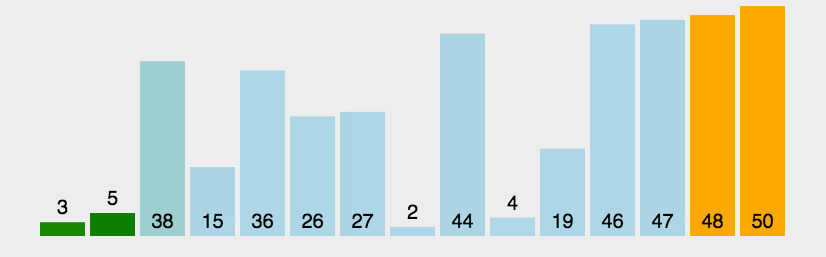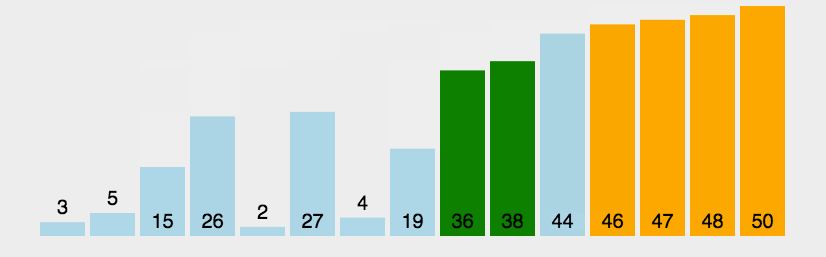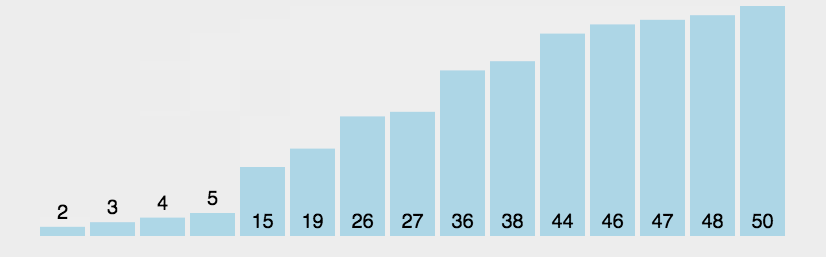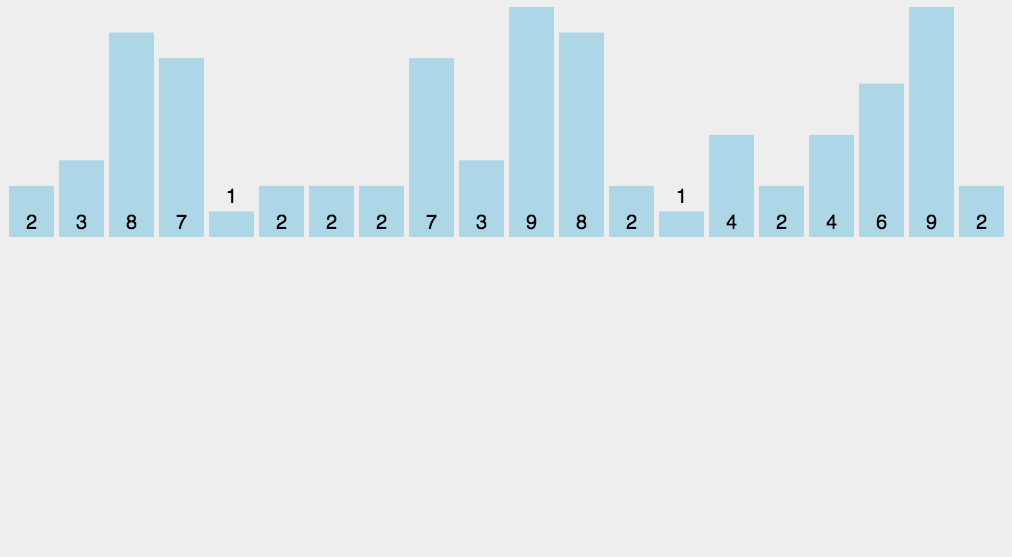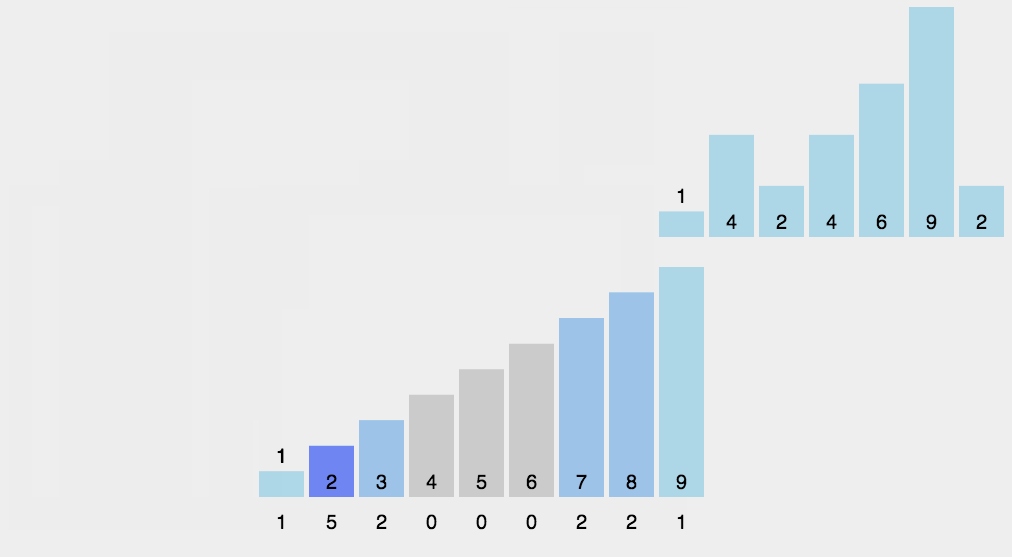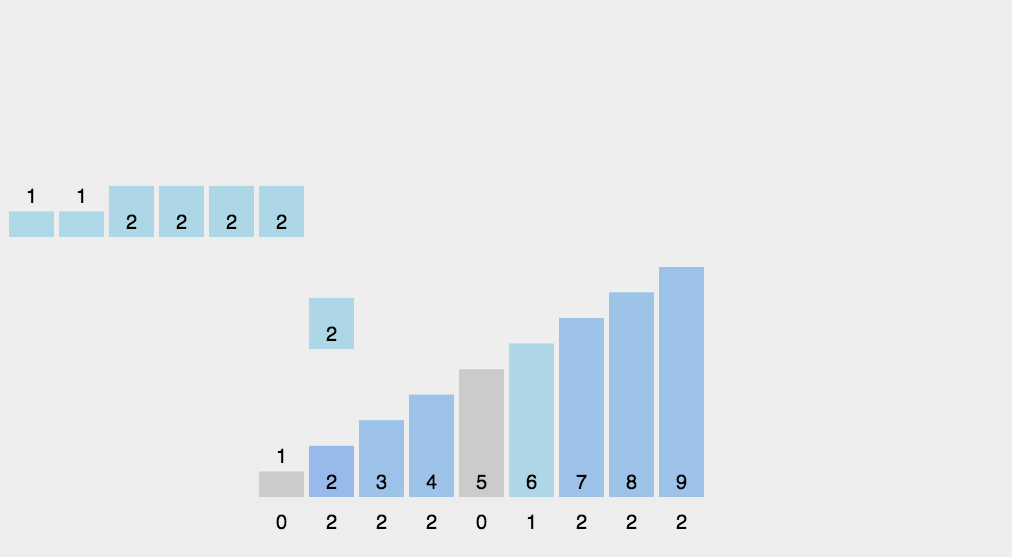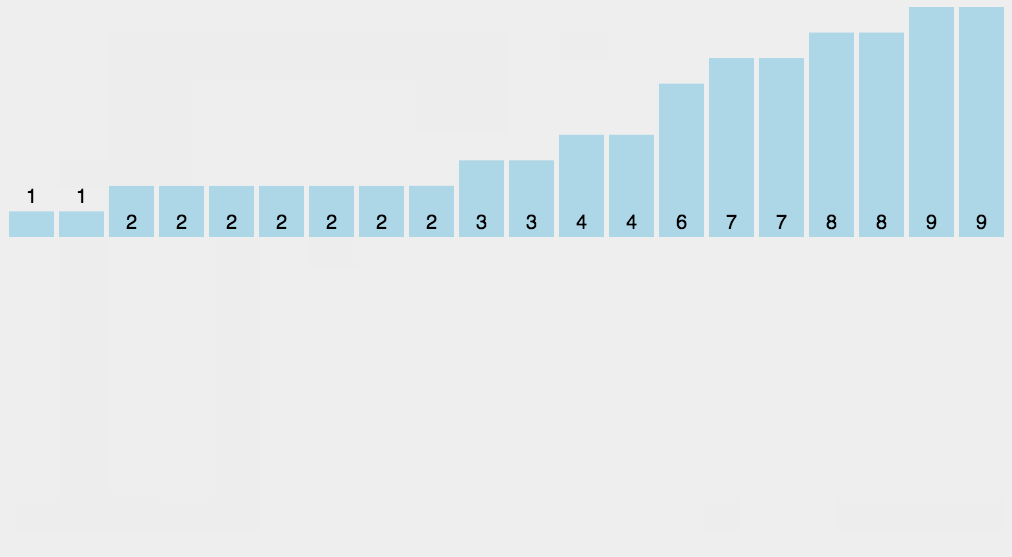The idea of bubble sort is that in each cycle, the big element goes down and the small one goes up, so that sorting is carried out. The specific process is as follows:
The idea of select sort is to find the smallest value in the first place in the process of each loop, loop to find other smaller values and place it in the next position, and sort by searching. The process is as follows:
1 2 3 4 5 6 7 8 9
defselect_sort(a): n = len(a) - 1 for i inrange(n): min_index = i for j inrange(i, n+1): if a[j] < a[min_index]: min_index = j a[i], a[min_index] = a[min_index], a[i] return a
3Insert Sort
The idea of insert sort is to compare with the previous elements. The big elements are placed at the back and the small ones are placed at the front. The specific process is as follows:
1 2 3 4 5 6 7 8 9 10
definsert_sort(a): n = len(a) for i inrange(1, n): cur_val = a[i] pos = i while pos > 0and a[pos - 1] > cur_val: a[pos] = a[pos - 1] pos -= 1 a[pos] = cur_val return a
4ShellSort
Shell sort is another variation of insert sort. The final sort is achieved through interval insert sort and gradually reducing the interval. The process is as follows:
defshell_sort(a): n = len(a) gap = n // 2 while gap > 0: for i inrange(gap): gap_insert(a, i, gap) #有间隔的插入排序 gap //= 2 return a defgap_insert(a, sta, gap): for i inrange(sta + gap, len(a), gap): cur_val = a[i] pos = i while pos > sta and a[pos - gap] > cur_val: a[pos] = a[pos - gap] pos -= gap a[pos] = cur_val return a
if __name__ == "__main__": a = [90, 5, 83, 42, 12, 15] print(shell_sort(a))
5MergeSort
Merge sort is based on the idea of divide and conquer. The data to be sorted is divided into two subsequences, the subsequences are sorted, and then the sorted subsequences are merged to achieve the final sorting. The process is as follows:
defmerge_sort(a): iflen(a) <= 1: return a n = len(a) // 2 left = merge_sort(a[:n]) #子序列归并排序 right = merge_sort(a[n:]) return merge(left, right) #合并排好序的子序列 defmerge(left, right): l, r = 0, 0 res = [] while l < len(left) and r < len(right): if left[l] < right[r]: res.append(left[l]) l += 1 else: res.append(right[r]) r += 1 res.extend(left[l:]) res.extend(right[r:]) return res
if __name__ == "__main__": a = [90, 5, 83, 42, 12, 15] print(merge_sort(a))
6HeapSort
The idea of heap sort is to create a big root heap, exchange the top position of the heap with the last one, and then create a big root heap, repeat the above operations to achieve sorting, the process is as follows:
defheap_sort(a): n = len(a) for i inrange(n // 2 - 1, -1, -1): siftdown(a, i, n - 1) #建立大根堆 for j inrange(n - 1, 0, -1): a[0], a[j] = a[j], a[0] #交换后,继续建立大根堆 siftdown(a, 0, j-1) return a defsiftdown(a, sta, end): root = sta #根节点 whileTrue: child = 2 * root + 1#左孩子节点 if child > end: break if child + 1 <= end and a[child] < a[child + 1]: #存在右孩子节点 child += 1 if a[root] < a[child]: #维护大根堆 a[root], a[child] = a[child], a[root] root = child else: break return a
if __name__ == "__main__": a = [90, 5, 83, 42, 12, 15] print(heap_sort(a))
7QuickSort
The idea of quick sorting is to select a baseline, put the one smaller than the baseline on one side, and put the one larger than the baseline on the other side, and achieve the final sorting by sorting the two parts. The process is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
defquick_sort(a): iflen(a) <= 1: return a left = [] right = [] base = a.pop() for x in a: if x < base: left.append(x) else: right.append(x) return quick_sort(left) + [base] + quick_sort(right)
if __name__ == "__main__": a = [90, 5, 83, 42, 12, 15] print(quick_sort(a))
8CountSort
The idea of count sort is to establish a counter, count the number of times each number appears, and then output the statistical results to achieve the final sort. The process is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
defcount_sort(a): n = len(a) max_val = max(a) count = [0] * (max_val + 1) for i inrange(n): count[a[i]] += 1 res = [] for i inrange(max_val + 1): for j inrange(count[i]): res.append(i) return res
if __name__ == "__main__": a = [90, 5, 83, 42, 12, 15] print(count_sort(a))
9BucketSort
The idea of bucket sorting is to put the elements in the corresponding range into the bucket, sort the elements in the bucket, and then take the elements out in order to complete the final sorting. The process is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
defbucket_sort(a,n=100,max_num=10000): buckets = [[] for _ inrange(n)] #创建桶 for x in a: i = min(x // (max_num // n) , n - 1) buckets[i].append(x) #将对应的数据放进桶中 for j inrange(len(buckets[i]) - 1 , 0 ,-1): if buckets[i][j] < buckets[i][j - 1]: buckets[i][j] , buckets[i][j - 1] = buckets[i][j - 1] , buckets[i][j] else: break result = [] forbinin buckets: result.extend(bin) return result
if __name__ == "__main__": a = [90, 5, 83, 42, 12, 15] print(bucket_sort(a))
10RadixSort
The idea of radix sort is to divide integers into different numbers by bit, and compare each number. The specific process is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
defradix_sort(a): max_val = max(a) it = 0 while10 ** it <= max_val: buckets = [[] for _ inrange(10)] for x in a: i = (x // (10 ** it)) % 10 buckets[i].append(x) a = [j for i in buckets for j in i] it += 1 return a
if __name__ == "__main__": a = [90, 5, 83, 42, 12, 15] print(radix_sort(a))