Daily Python Problems
Weekly issues(start:2021/4/16)
Special Edition: Recursion7
Q7Levenshtein
在计算文本的相似性时,经常会用到编辑距离。编辑距离,又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。通常来说,编辑距离越小,两个文本的相似性越大。这里的编辑操作主要包括三种:
- 插入:将一个字符插入某个字符串;
- 删除:将字符串中的某个字符删除;
- 替换:将字符串中的某个字符替换为另外一个字符。
当两个字符串都为空串,那么编辑距离为0;
当其中一个字符串为空串时,那么编辑距离为另一个非空字符串的长度;
当两个字符串均为非空时(长度分别为 i 和 j ),取以下三种情况最小值即可:
- 长度分别为 i-1 和 j 的字符串的编辑距离已知,那么加1即可;
- 长度分别为 i 和 j-1 的字符串的编辑距离已知,那么加1即可;
- 长度分别为 i-1 和 j-1 的字符串的编辑距离已知,此时考虑两种情况,若第i个字符和第j个字符不同,那么加1即可;如果不同,那么不需要加1。
1 | def minDistance(word1, word2): |
Q6Pascal Triangle
1 | # Function Method |
Q5River Crossing Problem【Unsolved】
写一个程序来解决这样一个问题:3只羚羊和3只狮子准备乘船过河,河边有一艘能容纳2只动物的小船。但是,如果两侧河岸上的狮子数量大于羚羊数量,羚羊就会被吃掉。找到运送办法,使得所有动物都能安全渡河。
1 |
Q4Least Common Multiple
1 | def lcm(a, b): |
Q3Gread Common Divisor
1 | # recursion method |
Q2Three Water Problem
====essential===> target_number % gcd == 0
贝祖定理/裴蜀定理:对任何整数a、b和它们的最大公约数d,关于未知数x和y的线性不定方程(称为裴蜀等式):若a,b是整数,且gcd(a,b)=d,那么对于任意的整数x,y–>ax+by都一定是d的倍数,特别地,一定存在整数x,y,使ax+by=d成立。
倒水问题属于数论应用题,可以运用丢番图方程进行解答。丢番图方程 ax+by=c (a、b、c是整数)有解,当且仅当c||gcd(a,b)成立
<<整数a、b和它们的最大公约数c。
一定存在整数x,y,使ax+by=c成立。
若d是c的倍数,显然也一定存在整数x,y,使得 ax+by=d成立。>>
实际上,两个容量互质的水杯,可以倒出任意容量的水。
1 | class Solution: |
use recursion to calculate the sum of list
Q1Sum List
1 | # common case |
FirthIssue(5/22-27)4
Q4Binary Search
1 | # Method one |
Q3Fibonacci Sequence
1 | #---- Recursion[the worst way*] ---- |
Q2Recursion List
1 | def rev_list(l): |
Q1Greedy Algorithm
1 | def dpmakechange(coinvaluelist, change, mincoins, coinsused): |
FourthIssue(5/14-22)6
Q6Tower of Hanoi
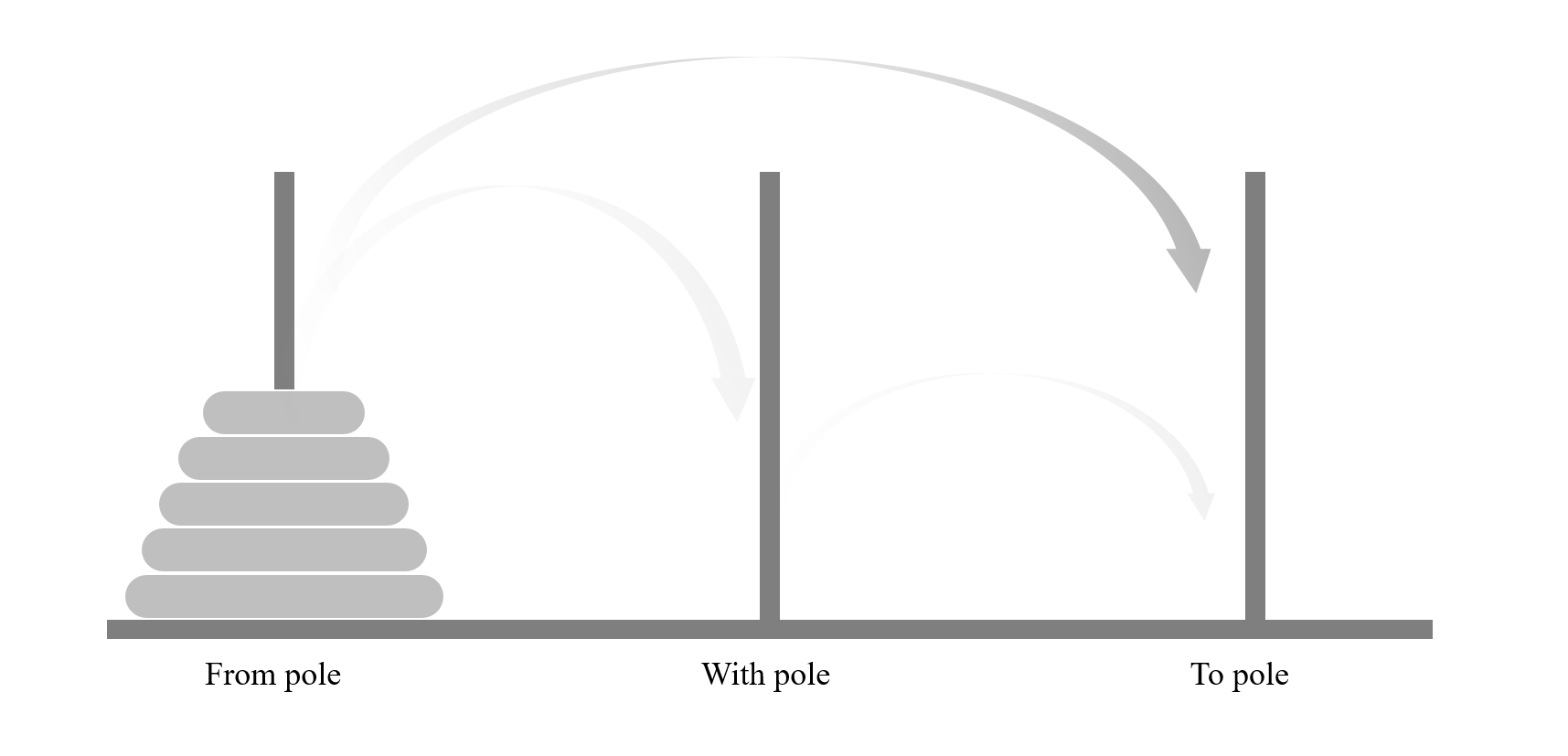
1 | def movedisk(fp, tp): |
1 | def hanoi(n, x, y, z): |
Q5Integer to arbitary base string
key steps: tostr(n//base, base)
1 | # uesing recursion |
1 | # useing stack |
Q4InfixExp convert PostExp
Q3Unordered Linked List
implement unordered linked list by python
1 | class Node: |
Q2Joseph ring problem
we can simulate a ring with Queue, the essential of joseph ring problem is Queue Problem
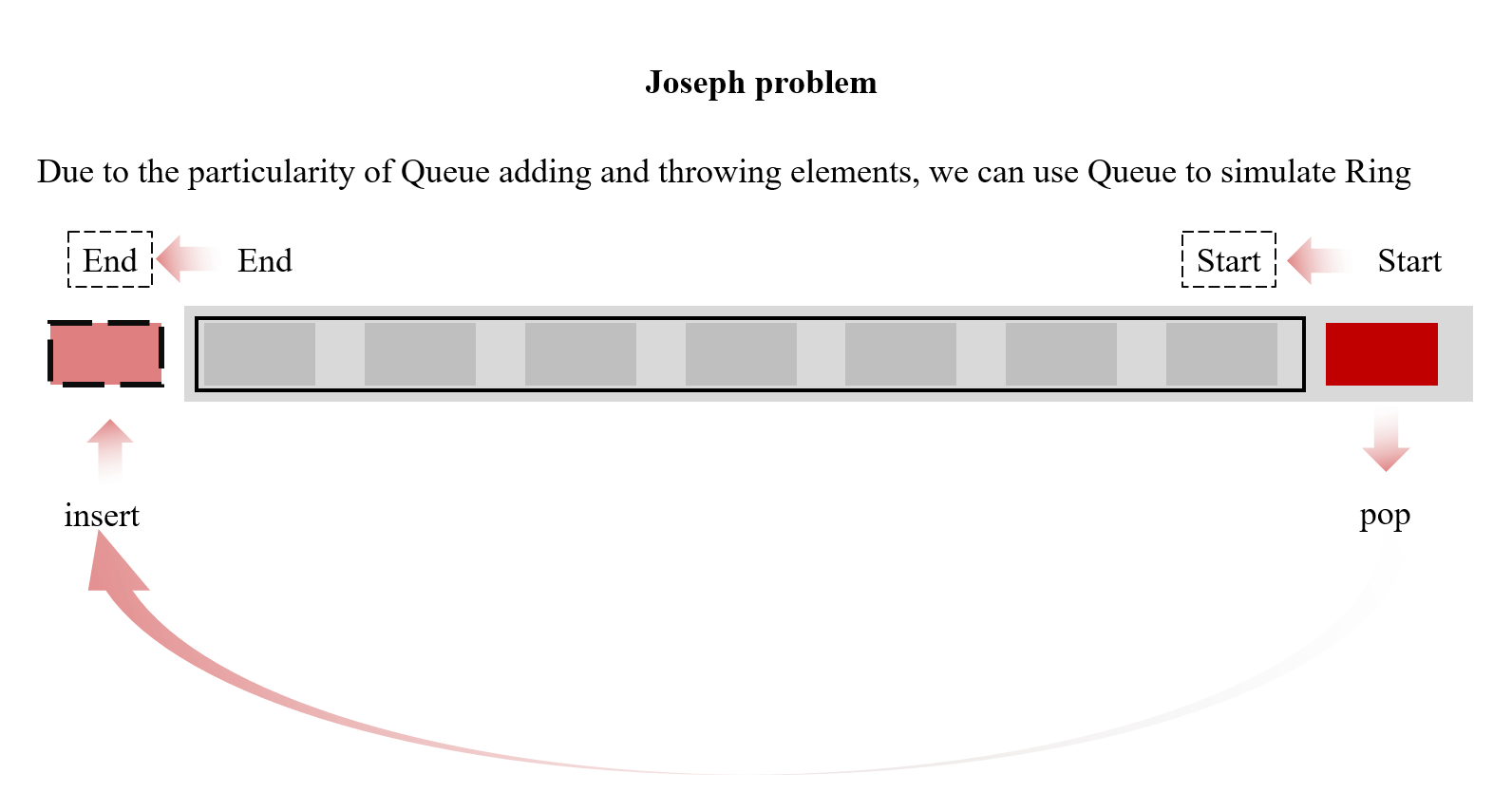
1 | print(listname) |
Q1Fixed-Point Problem
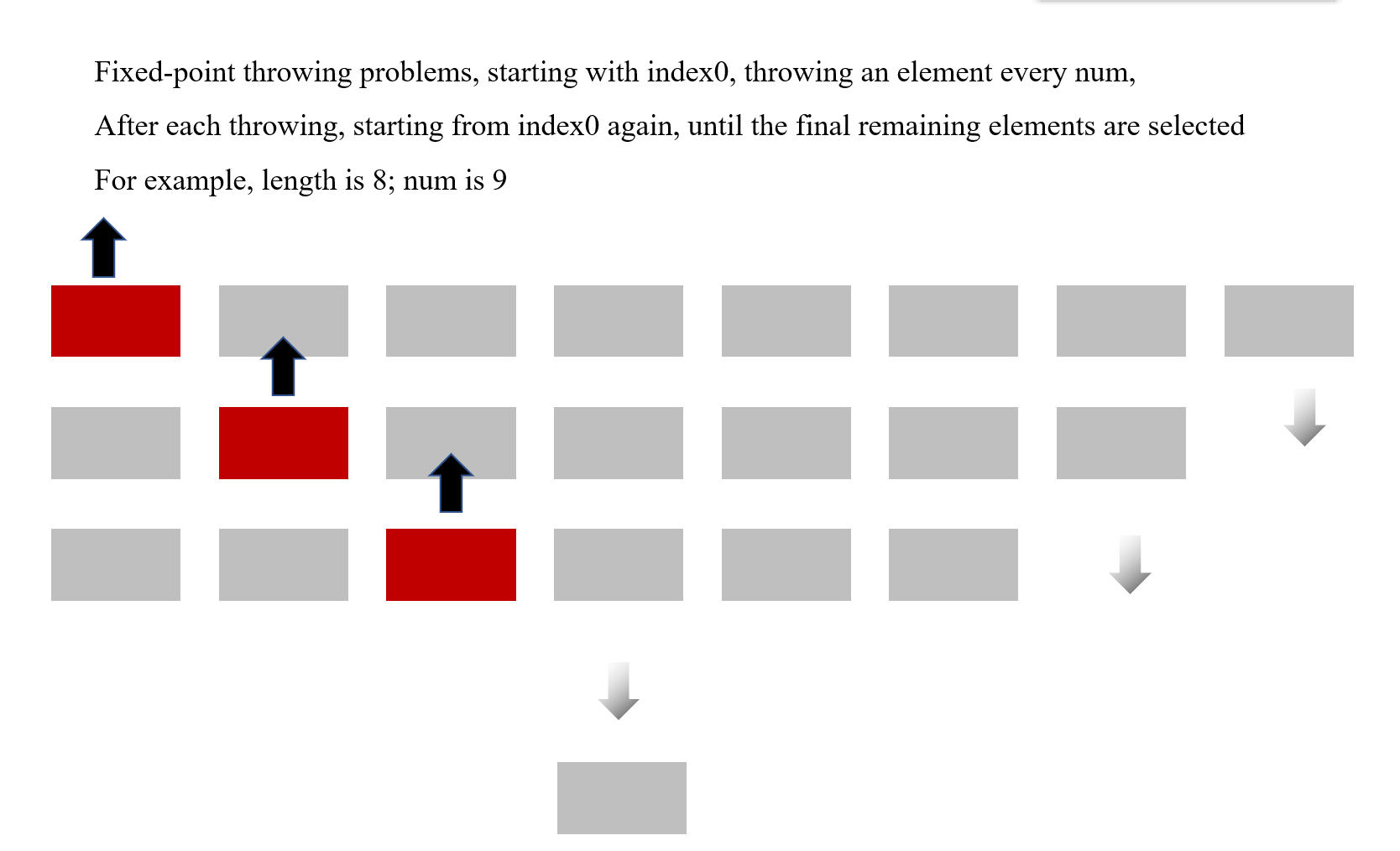
1 | def post_potatoes(namelist, num): |
ThirdIssue(5/10-14)4
Q4:Convert list to String
use the builtin function:''.join(list)
1 | temp_list = [chr(i) for i in range(65, 91)] |
Q3:Pre/Middle/PostExpression Conversion
| Middle Expression | Per Expression | Post Expression |
|---|---|---|
| A + B | + A B | A B + |
| A + (B * C) | + A * B C | A B C * + |
| (A + B) * C | *+ A B | A B + C * |
The preorder expression requires all operators to appear before the two operands it acts on ps: pay attention to bracket
First in First out
InfixExp(中序表达式)转换PostfixExp(后序表达式)算法:
1)当输入的是操作数时候,直接输出到后序表达式PostfixExp序列中
2)当输入开括号时候,把它压栈
3)当输入的是闭括号时候,先判断栈是否为空,若为空,则发生错误并进行相关处理。若非空,把栈中元素依次弹出并输出到Postfix中,知道遇到第一个开括号,若没有遇到开括号,也发生错误,进行相关处理
4)当输入是运算符op(+、- 、×、/)时候
a)循环,当(栈非空and栈顶不是开括号and栈顶运算符的优先级不低于输入的运算符的优先级)时,反复操作:将栈顶元素弹出并添加到Postfix中
b)把输入的运算符op压栈
5)当中序表达式InfixExp的符号序列全部读入后,若栈内扔有元素,把他们依次弹出并放到后序表达式PostfixExp序列尾部。若弹出的元素遇到空括号,则说明不匹配,发生错误,并进行相关处理
1 | # convert middle-expression to post expression |
Q2.1Calculate Post Expression
1 | def post_calculateion_expression(postfixexpr): |
Q1:BaseConversion
Decimal Conversion
remainder number optimization by string`s index
1 | def decimal(num): |
Second Issue(5/3-8)3
Q3:RegularExpression
https://deerchao.cn/tutorials/regex/regex.htm
注意:本题是整个面试流程中的第一道开卷试题。
请写一个 匹配 简历中 中英文本科学位名称 的 Python 正则表达式。
本题考察的技能和思维严谨性是这份工作最需要的,请仔细查一查想一想,最好上机调试一下,再作答。
简历中 描述本科学位,一般说:“Bachelor”, “本科”,等等。举几个从实际简历pdf提取的文字例子:
例1:
Education
Philippines University MBA
Pepperdine University – Malibu, CA Bachelor of Arts, Economics
要求正则匹配“Bachelor”。
例2:
学历教育
中国地质大学(武汉)地理信息系统专业——硕士
中国地质大学(武汉)地理信息系统专业——工学学士
要求正则匹配“学士”。
例3:
EDUCATION
Bachelor of Science in CSE/Bio-engineering; Bioinformatics, University of California, San Diego.
要求正则匹配“Bachelor”。
1 | import re |
Q2:Match Brackets
1 | import Stack |
Q1:Heterologous Detection
Method1Counting
1 | def counting_method(s1, s2): |
ord(character) –return–>the ascii code
example: ord(‘a’)–return–> 97
Method2Sorting
1 | def sortingmethod(s1, s2): |
First Issue(4/16-4/23)2
Q2:Fraction Class
create a instance to inplement the fraction`s add-method
1 | def gcd(m, n): |
Q1:Split string into individual letters
1 | string = 'ab_cdefg' |
- number(0-9):the representation of ASCII is 48~57
- Lower case letters(a-z):the representation of ASCII is 97~122
- uppercase letters(A-Z):the representation of ASCII is 65~90
ASCII: American standard code for information interchange