Python底层结构
三元表达式
条件为真时的结果 if 判段的条件 else 条件为假时的结果
1 | x = 4 |
基础知识
[Python里面如何生成随机数?]
random模块
**随机整数:random.randint(a,b)**:返回随机整数x,a<=x<=b
random.randrange(start,stop,[,step]):返回一个范围在(start,stop,step)之间的随机整数,不包括结束值。
**随机实数:random.random( ):**返回0到1之间的浮点数
random.uniform(a,b):返回指定范围内的浮点数。
[python复制一个对象]
Python里面如何拷贝一个对象?(赋值,浅拷贝,深拷贝的区别)
答:赋值(=),就是创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。
浅拷贝:创建一个新的对象,但它包含的是对原始对象中包含项的引用(如果用引用的方式修改其中一个对象,另外一个也会修改改变){1,完全切片方法;2,工厂函数,如list();3,copy模块的copy()函数}
深拷贝:创建一个新的对象,并且递归的复制它所包含的对象(修改其中一个,另外一个不会改变){copy模块的deep.deepcopy()函数}
[is与==的区别]
在 Python 中,”==” 和 “is” 的区别可类比这个例子 ,**==是相等性比较,比较的是两个对象中的值是否相等,is是一致性比较,比较的是两个对象的内存空间地址是否相同。**
[列表由于是可以增删的(可变化)因此不能做为hashtable的key]
[python不支持的数据类型是什么?]
python不支持的数据类型是char 、byte类型。Python没有char或byte类型来保存单一字符或 8 比特整数。你可以使用长度为 1 的字符串表示字符或 8 比特整数。
python的数据类型有:
数字(int)、浮点(float)、字符串(str),列表(list)、元组(tuple)、字典(dict)、集合(set)、
byte 是字节数据类型 ,是有符号型的,可以表示-128—127 的数;
char 是字符数据类型 ,是无符号型的,可以表示一个整数,不能表示负数。
字典排序
【1.按照keys进行排序】
1 | dct = {'a': 1, 'e': 8, 'c': 10, 'd': 4} |
【2.按照values进行排序】
1 | dct = {'a': 1, 'e': 8, 'c': 10, 'd': 4} |
【3.降序排列,可以在sorted()中设置reverse】
【4.集合无法进行排序】
【0.注意】
1 | a = set() |
Boolean运算优先级
同一优先级默认从左往右计算。
- 优先级是 not > and > or
- not:如果x是假的,则“非假”为真,否则x是真的,则非真为假
- and: 找到并返回第一个False(假)或最后一个True(真)
- or: 找到并返回第一个True(真)或最后一个False(假)
迭代器|生成器|迭代对象
生成器Generator
一种特殊的迭代器与迭代器定义一致
他与迭代器的编程方式不一样
1 | L = [x * x for x in range(10)] |
迭代器定义
1 | 1.在class中定义__iter__和__next__方法 |
判断是否是迭代对象或者迭代器使用:
1 | from collections.abc import Iterator, Iterable |
instance:
1 | from collections.abc import Iterator, Iterable |
可迭代对象内部有__iter__方法,retun一个迭代器
当terminal中输出的是generator时,可以使用:
1 | >>list(generator) |
查看迭代器的内容,而非输出其memory地址
浅拷贝/深拷贝
【copy解决的是容器中可迭代的值:应用于可变类型对象】

要想切断浅拷贝中第二层的值,可以通过重新引用来实现
1 | c[3] = [0, 1, 2, 3] |
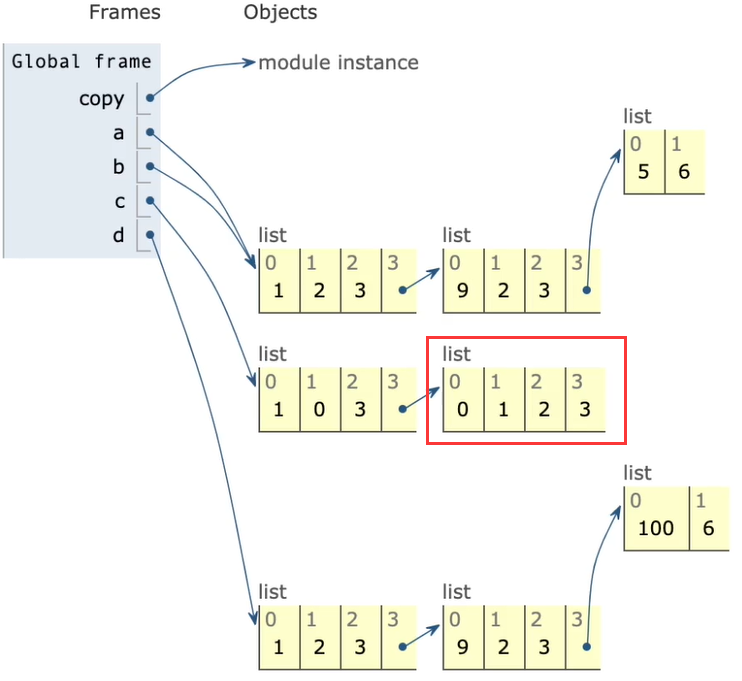
首先需要了解下几个概念
- 变量:是一个系统表的元素,拥有指向对象的连接空间
- 对象:被分配的一块内存,存储其所代表的值
- 引用:是自动形成的从变量到对象的指针
- 类型:属于对象,而非变量
- 不可变对象:一旦创建就不可修改的对象,包括字符串、元组、数值类型
(该对象所指向的内存中的值不能被改变。当改变某个变量时候,由于其所指的值不能被改变,相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。)
- 可变对象:可以修改的对象,包括列表、字典、集合
(该对象所指向的内存中的值可以被改变。变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的地址,通俗点说就是原地改变。)
当我们写:
1 | a = 'python' |
Python解释器干的事情:
\1. 创建变量a
\2. 创建一个对象(分配一块内存),来存储值 ‘python’
\3. 将变量与对象,通过指针连接起来,从变量到对象的连接称之为引用(变量引用对象)
1.赋值: 只是复制了新对象的引用,不会开辟新的内存空间。
并不会产生一个独立的对象单独存在,只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。
2.浅拷贝: 创建新对象,其内容是原对象的引用。
浅拷贝有三种形式: 切片操作,工厂函数,copy模块中的copy函数。
如: lst = [1,2,[3,4]]
切片操作:lst1 = lst[:] 或者 lst1 = [each for each in lst]
工厂函数:lst1 = list(lst)
copy函数:lst1 = copy.copy(lst)
浅拷贝之所以称为浅拷贝,是它仅仅只拷贝了一层,拷贝了最外围的对象本身,内部的元素都只是拷贝了一个引用而已,在lst中有一个嵌套的list[3,4],如果我们修改了它,情况就不一样了。
浅复制要分两种情况进行讨论:
1)当浅复制的值是不可变对象(字符串、元组、数值类型)时和“赋值”的情况一样,对象的id值(id()函数用于获取对象的内存地址)与浅复制原来的值相同。
2)当浅复制的值是可变对象(列表、字典、集合)时会产生一个“不是那么独立的对象”存在。有两种情况:
第一种情况:复制的对象中无复杂子对象,原来值的改变并不会影响浅复制的值,同时浅复制的值改变也并不会影响原来的值。原来值的id值与浅复制原来的值不同。
第二种情况:复制的对象中有复杂子对象(例如列表中的一个子元素是一个列表),如果不改变其中复杂子对象,浅复制的值改变并不会影响原来的值。 但是改变原来的值中的复杂子对象的值会影响浅复制的值。
3.深拷贝:和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。深拷贝出来的对象是一个全新的对象,不再与原来的对象有任何关联。
所以改变原有被复制对象不会对已经复制出来的新对象产生影响。
只有一种形式,copy模块中的deepcopy函数
对于不可变对象的深浅拷贝
1 | import copy |
结果:
1 | =====赋值===== |
不可变对象类型,没有被拷贝的说法,即便是用深拷贝,查看id的话也是一样的,如果对其重新赋值,也只是新创建一个对象,替换掉旧的而已。
一句话就是,不可变类型,不管是深拷贝还是浅拷贝,地址值和拷贝后的值都是一样的。
对于可变对象深浅拷贝
1 | import copy |
结果:
1 | =====赋值===== |
赋值: 值相等,地址相等
copy浅拷贝:值相等,地址不相等
deepcopy深拷贝:值相等,地址不相等
对于可变对象深浅拷贝(外层改变元素)
1 | import copy |
结果:
1 | [1, 2, 3, [4, 5], 6] #l添加一个元素6 |
对于可变对象深浅拷贝(内层改变元素)
1 | import copy |
结果:
1 | [1, 2, 3, [4, 5, 6]] #l[3]添加一个元素6 |
1.外层添加元素时,浅拷贝不会随原列表变化而变化;内层添加元素时,浅拷贝才会变化。
2.无论原列表如何变化,深拷贝都保持不变。
3.赋值对象随着原列表一起变化。
几何[set]
Python set 集合最常用的操作是向集合中添加、删除元素,以及集合之间做交集、并集、差集等运算,本节将一一讲解这些操作的具体实现。
向 set 集合中添加元素
set 集合中添加元素,可以使用 set 类型提供的 add() 方法实现,该方法的语法格式为:
setname.add(element)
其中,setname 表示要添加元素的集合,element 表示要添加的元素内容。
需要注意的是,使用 add() 方法添加的元素,只能是数字、字符串、元组或者布尔类型(True 和 False)值,不能添加列表、字典、集合这类可变的数据,否则 Python 解释器会报 TypeError 错误。例如:
1 | a = {1,2,3}a.add((1,2))print(a)a.add([1,2])print(a) |
运行结果为:
{(1, 2), 1, 2, 3}
Traceback (most recent call last):
File “C:\Users\mengma\Desktop\1.py”, line 4, in
a.add([1,2])
TypeError: unhashable type: ‘list’
从set集合中删除元素
删除现有 set 集合中的指定元素,可以使用 remove() 方法,该方法的语法格式如下:
setname.remove(element)
使用此方法删除集合中元素,需要注意的是,如果被删除元素本就不包含在集合中,则此方法会抛出 KeyError 错误,例如:
1 | a = {1,2,3}a.remove(1)print(a)a.remove(1)print(a) |
运行结果为:
{2, 3}
Traceback (most recent call last):
File “C:\Users\mengma\Desktop\1.py”, line 4, in
a.remove(1)
KeyError: 1
上面程序中,由于集合中的元素 1 已被删除,因此当再次尝试使用 remove() 方法删除时,会引发 KeyError 错误。
如果我们不想在删除失败时令解释器提示 KeyError 错误,还可以使用 discard() 方法,此方法和 remove() 方法的用法完全相同,唯一的区别就是,当删除集合中元素失败时,此方法不会抛出任何错误。
例如:
1 | a = {1,2,3}a.remove(1)print(a)a.discard(1)print(a) |
运行结果为:
{2, 3}
{2, 3}
Python set集合做交集、并集、差集运算
集合最常做的操作就是进行交集、并集、差集以及对称差集运算,首先有必要给大家普及一下各个运算的含义。
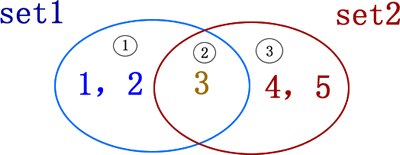
图 1 中,有 2 个集合,分别为 set1={1,2,3} 和 set2={3,4,5},它们既有相同的元素,也有不同的元素。以这两个集合为例,分别做不同运算的结果如表 1 所示。
| 运算操作 | Python运算符 | 含义 | 例子 |
|---|---|---|---|
| 交集 | & | 取两集合公共的元素 | >>> set1 & set2 {3} |
| 并集 | | | 取两集合全部的元素 | >>> set1 | set2 {1,2,3,4,5} |
| 差集 | - | 取一个集合中另一集合没有的元素 | >>> set1 - set2 {1,2} >>> set2 - set1 {4,5} |
| 对称差集 | ^ | 取集合 A 和 B 中不属于 A&B 的元素 | >>> set1 ^ set2 {1,2,4,5} |
字典[dict]
字典中的.pop()是指删除key-val并抛出val
字典的访问:
- dic.get(key, default):访问key,如果没有key返回None,有key返回对应的value
- dic[key]:通过key访问value
- for key in dic.keys():访问所有的keys
- for value in dic.values():访问所有的values
- for key, value in dic.items():访问所有的键值对
- for i in dict–>access key
- for key in dict.keys–>accsee key
- for key, val in dict.item–>access key and val
- dict[key]–>access key对应的val, 没有的话返回KeyError
- dict.get(key, val(default:None))–>访问dict中key对应的值,没有的话返回val
有与dict中的key不可以直接修改,如果要修改key需要以下操作
第一种方法:将需要修改的键对应的值用dict.pop() 的方法提取出来,并重新赋值给新的键,即dict[新的键] = dict.pop(旧的键)。(字典dict的pop是删除某个键及其对应的值,返回的是该键对应的值)
1 | dict={'a':1, 'b':2} |
第二种方法:结合dict.pop() 和dict.update() 的方法。(字典dict的pop是删除某个键及其对应的值,返回的是该键对应的值)
1 | dict={'a':1, 'b':2} |
第三种方法:结合直接修改和del语句。先用直接修改的方式将旧键赋值给新的键,再用del语句删除原来的键名。
1 | dict={'a':1, 'b':2} |
Operators
//:rounding down ==> 7//2 = 3.5 —> 3
[start:end]==>contains start except end
[1, 2, 3, 4, 5] ==[2:]==>[3, 4, 5]
[1, 2, 3, 4, 5] ==[:2]==>[1, 2]
[1, 2, 3, 4, 5] ==[1:3]==>[2, 3]
切片操作[start:end]==>[start, end)
[a::b]
这个是python的slice notation的特殊用法。
b = a[i:j] ==>[i, j)==>new list
- default(i)=0
- default(j)=len(alist)
[i:j:s]==>[i, j) step=s
如果s<0
- i缺省时,默认为-1;
- j缺省时,默认为-len(a)-1
所以a[::-1]相当于 a[-1:-len(a)-1:-1],也就是从最后一个元素到第一个元素复制一遍。
常见的譬如[::-1]==>将list的所有元素反转
1 | b1 = [1, 2, 3, 4][::-1] |
randint(start, end)==>contains start and end==>[start, end]
example==>randint(1, 3)==>1, 2, 3
测试code性能
Performance
1.timeit
timeit只输出被测试代码的总运行时间
1 | import timeit |
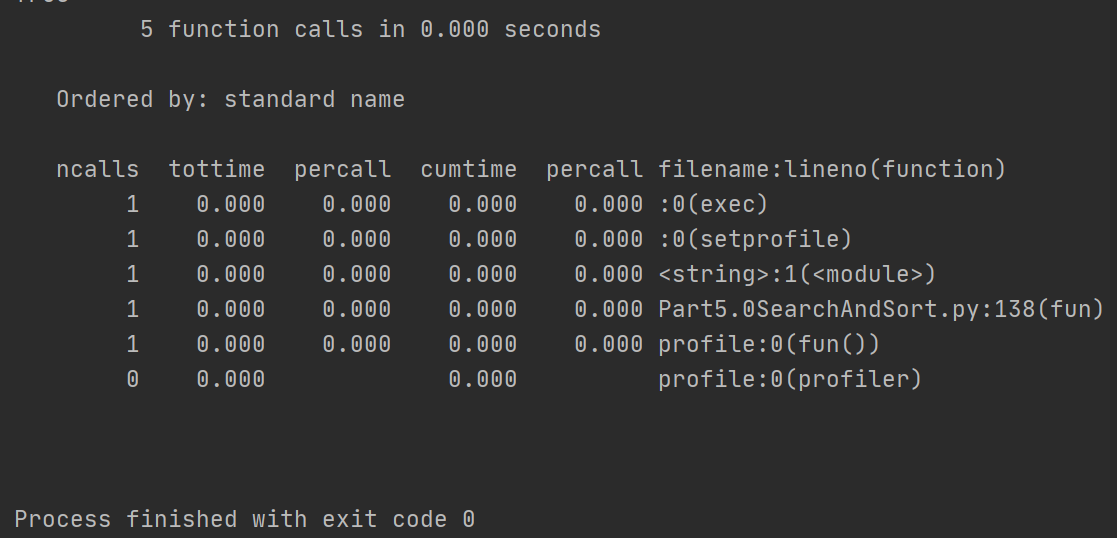
2.profile[函数时间]
profile:纯Python实现的性能测试模块,接口和cProfile一样。
1 | import profile |
- ncall:函数运行次数
- tottime: 函数的总的运行时间,减去函数中调用子函数的运行时间
第一个percall:percall = tottime / nclall
- cumtime:函数及其所有子函数调整的运行时间,也就是函数开始调用到结束的时间。
第二个percall:percall = cumtime / nclall
| 名称 | 含义 |
|---|---|
| ncalls | 函数被调用次数 |
| tottime | 函数(除去子函数)总运行时间 |
| percall | 平均时间,等于tottime/ncalls |
| cumtime | 函数(包括子函数)总运行时间 |
| percall | 平均时间,等于cumtime/ncalls |
| filename | 文件:行号(函数) |
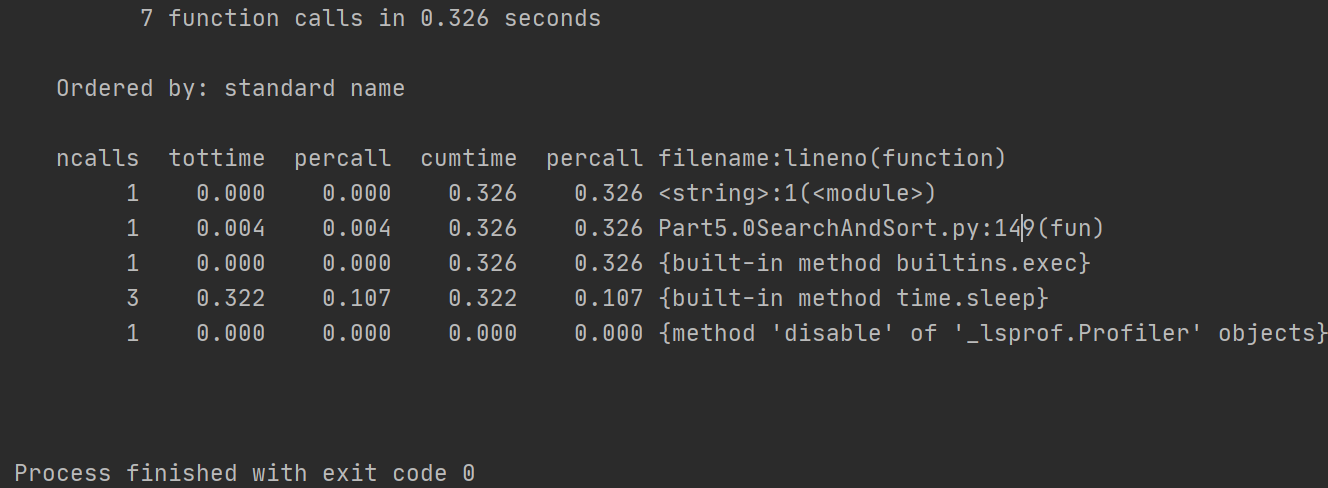
3.cProfiler[函数时间]
profile:c语言实现的性能测试模块,接口和profile一样。
1 | import cProfile |
result:
profiler 和 cProfiler 都只能检测整个函数的运行时间,要想知道每行代码运行所损耗的时间需要line_profiler或者memory_profiler(不仅可以得到每行代码运行的时间还可以统计每行代码所占用的内存大小)
4.line_profiler[分段时间]
pip install line_profiler
安装之后kernprof.py会加到环境变量中。
line_profiler可以统计每行代码的执行次数和执行时间等,时间单位为微妙。
该模块常通过装饰器来使用。在安装好该模块后,编写需要测试的python程序,并在需要测试的函数上方加入@profile,保存为*.py文件。在命令行使用kernprof -l -v *.py,在输出打印出程序结果之后会打印性能分析。
输出结果的含义:
1 | from line_profiler import LineProfiler |
| 名称 | 意义 |
|---|---|
| Timer unit | 计时器单位,微秒 |
| Total time | 测试代码总运行时间 |
| File | 测试代码文件名 |
| Hits | 每行代码运行次数 |
| Time | 每行代码运行时间 |
| Per Hit | 每行代码运行一次的时间 |
| % Time | 每行代码运行时间的百分比 |
| Line Contents | 每行代码 |
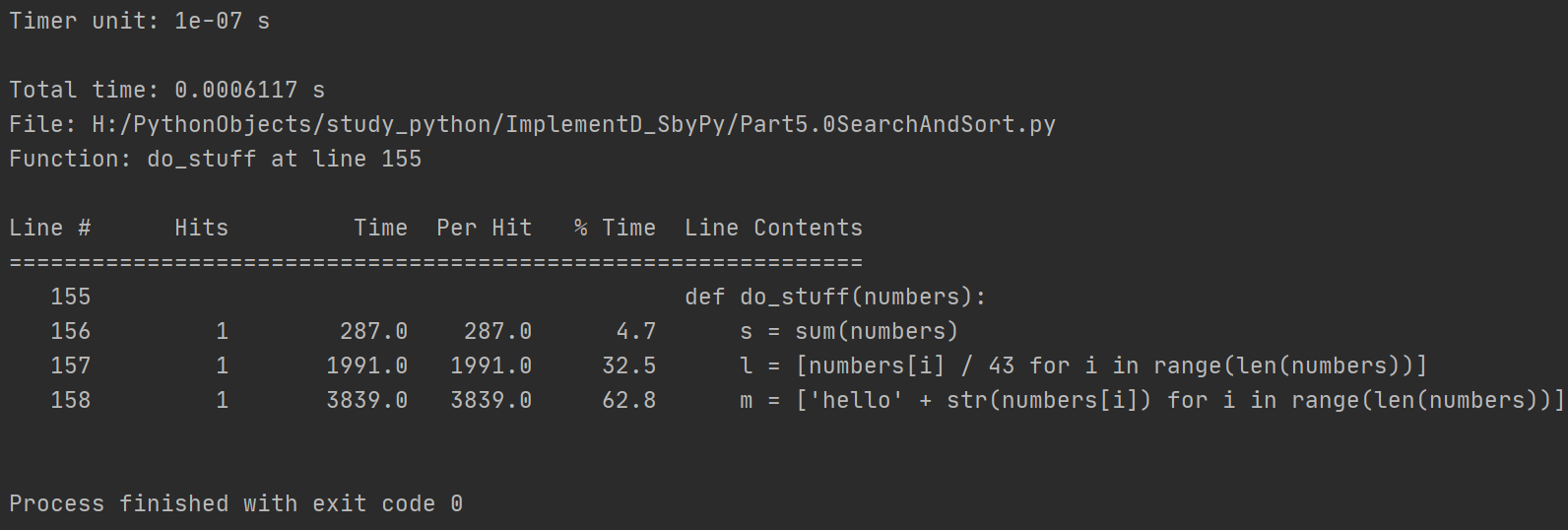
- Total Time:测试代码的总运行时间
- Hits:表示每行代码运行的次数
- Time:每行代码运行的总时间
- Per Hits:每行代码运行一次的时间
- % Time:每行代码运行时间的百分比
5.memory_profiler:[内存]
memory_profiler工具可以统计每行代码占用的内存大小。
测试代码:
使用方法同line_profiler模块,借助装饰器调用。在需要分析的函数上方加@profile。在命令行使用python -m memory_profiler *.py运行代码。
输出结果中:
Mem usage:内存使用情况
Increment:每行代码运行后内存增减情况
使用:
- 在需要测试的函数加上@profile装饰
- 执行命令: python -m memory_profiler C:Python34 est.py
1 | # 将调试文件独立出xx.py |
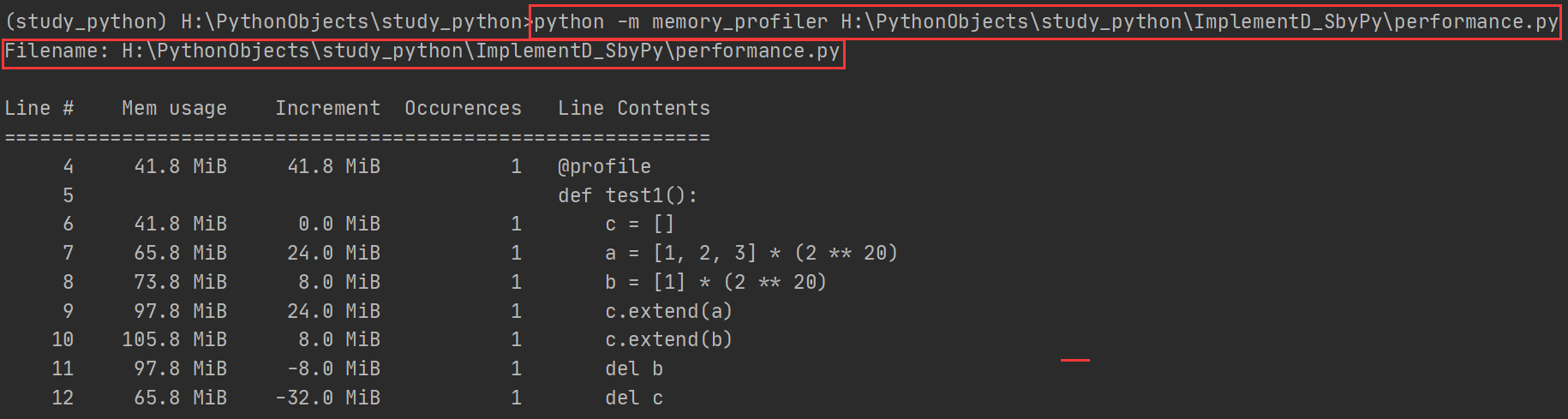
Mem usage为当前总内存Increment为增加的内存
总结起来使用非常时间
- 方法前加上
@profile主键 - 使用
python -m memory_profiler来运行,不过直接用python运行也可以
通过上面这段代码我们可以发现,del 语句只是将变量删除,并不能减少内存的消耗。
参数使用
precision显示小数点后的位数
默认显示的内存单位为 MiB,小数点后显示一位,如果某行代码占用内存比较小,就可能显示不出来,此时可以通过调整小数点后的位数实现。
1 | from memory_profiler import profile |
stream将结果输出到流中
每次运行都要打印内存情况,势必会影响程序输出效果,我们可以将结果通过流输出到文件中
1 | from memory_profiler import profile |
6.objgraph:[待完善]
objgraph是一个实用模块,可以列出当前内存中存在的对象,可用于定位内存泄露。
objgraph需要安装:
pip install objgraph
Time
计算Python的某个程序,或者是代码块运行的时间一般有三种方法。
1.datetime
1 | import datetime |
2.time–time
1 | import time |
3.time-clock(version<3.8)
1 | import time |
通过对以上方法的比较我们发现,方法二的精度比较高。方法一基本上是性能最差的。这个其实是和系统有关系的。一般我们推荐使用方法二和方法三。我的系统是Ubuntu,也就是Linux系统,方法二返回的是UTC时间。 在很多系统中time.time()的精度都是非常低的,包括windows。
python 的标准库手册推荐在任何情况下尽量使用time.clock().但是这个函数在windows下返回的是真实时间(wall time)
方法一和方法二都包含了其他程序使用CPU的时间。方法三只计算了程序运行CPU的时间。
方法二和方法三都返回的是浮点数
究竟是使用 time.clock() 精度高,还是使用 time.time() 精度更高,要视乎所在的平台来决定。总概来讲,在 Unix 系统中,建议使用 **time.time()**,在 Windows 系统中,建议使用 **time.clock()**。
我们要实现跨平台的精度性,我们可以使用timeit 来代替time
1 | import timeit |
时间复杂度
随着问题规模的增加,T(n)变化最大的数量级称为时间复杂度O(n)
字符编码
Python2中默认的编码格式是 ASCII 格式,程序文件中如果包含中文字符(包括注释部分)需要在文件开头加上 # -*- coding: UTF-8 -*- 或者 #coding=utf-8 就行了
Python3默认支持Unicode
保留字(关键字)
30个关键字
1 | and exec not |
注释
1 | # 单行注释 |
变量赋值
Python是动态语言,所以在定义变量的时候不需要申明类型,直接使用即可。
Python会根据值判断类型。
1 | name = "Zeta" # 字符串变量 |
多变量赋值
1 | a,b = 1,2 # a=1; b=2 |
标准数据类型
Python 的标准数据类型有:
- Boolean(布尔值)
- Number(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)(hash map)—遇到hash冲突时,采用的是开放寻址法而不是链接法
Python标准数据结构有:
有序结构,可以使用index下标进行检索数据,并且序列中的元素可以重复
- List
- Tuple
- String
无序结构,不可以用index下标进行检索,序列中允许有重复元素
- Set
- Dictionary
数据类型转换
Python类型转换非常简单,用类型名作为函数名即可。
1 | int(n) # 将数字n转换为一个整数 |
另外,Python中可以直接转换数字字符串和数字:
1 | s = "123" |
条件语句
Python传统的判断语句如下
1 | if name == 'zeta': # 判断变量是否为 zeta |
Python不支持三元表达式,但是可以用一种类似的替代办法
1 | title = "boss" |
逻辑与用 and ,逻辑或用 or
循环语句
Python中有while和for两种循环,都可以使用break跳出循环和continue立即进入下一轮循环,另外,Python的循环语句还可以用else执行循环全部完毕后的代码,break跳出后不会执行else的代码
while 条件循环,
1 | count = 0 |
for 遍历循环,循环遍历所有序列对象的子项
1 | names = ['zeta', 'chow', 'world'] |
for循环中也可以用else,(注释掉代码中的break试试看。)
函数
用def关键字定义函数,并且在Python中,作为脚本语言,调用函数必须在定义函数之后。
1 | def foo(name): |
默认参数 Python定义函数参数时,可以设置默认值,调用时如果没有传递该参数,函数内将使用默认值,默认值参数必须放在无默认值参数后面。
1 | def foo(name="zeta"): |
关键字参数 一般函数传递参数时,必须按照参数定于的顺序传递,但是Python中,允许使用关键字参数,这样通过指定参数明,可以不按照函数定义参数的顺序传递参数。
1 | def foo(age, name="zeta"): |
不定长参数,Python支持不定长参数,用*定义参数名,调用时多个参数将作为一个元祖传递到函数内
1 | def foo(*names): |
return 返回函数结果。
模块
- 模块是一个.py文件
- 模块在第一次被导入时执行
- 一个下划线定义保护级变量和函数,两个下划线定义私有变量和函数
- 导入模块习惯性在脚本顶部,但是不强制
导入包
在Python中,使用import导入模块。
1 | #!/usr/bin/python# -*- coding: UTF-8 -*- # 导入模块import support support.print_func(“Runoob”) |
还可以使用from import导入模块指定部分
1 | from modname import name1[, name2[, ... nameN]] |
为导入的包设置别名用 as关键字
1 | import datetime as dt |
错误和异常
Python中用经典的 try/except 捕获异常
1 | try:<语句> #运行别的代码 |
还提供了 else 和 finally
如果没发生异常的执行else语句块,finally块的代码无论是否捕获异常都会执行
Python内建了很全面的异常类型名称,同时能自定义异常类型
面向对象
Python完全支持面向对象的。
多线程
- 使用
thread模块中的start_new_thread()函数 - 使用
threading模块创建线程
总结
Python和Go分别在动态语言和静态语言中都是最易学易用的编程语言之一。
它们并不存在取代关系,而是各自在其领域发挥自己的作用。
Python的语法简单直观,除了程序员爱不释手外也非常适合于其他领域从业者使用。
Go兼具语法简单和运行高效的有点,在多线程处理方面很优秀,非常适合已经掌握一定编程基础和一门主流语言的同学学习,不过,Go是不支持面向对象的,对于大多数支持面向对象语言的使用者在学习Go语言的时候,需要谨记并且转换编程思路。