华为题库
1H字符串最后一个单词的长度
字符串
思路/考点
将输入的字符串通过split()转化成list,再通过index进行求解
描述
计算字符串最后一个单词的长度,单词以空格隔开,字符串长度小于5000。
输入描述:
输入一行,代表要计算的字符串,非空,长度小于5000。
输出描述:
输出一个整数,表示输入字符串最后一个单词的长度。
1 | t = input().split(' ') |
2H计算某字母出现次数
字符串/哈希
思路/考点
考察count()函数,由于tuple\string\list在python具有相似的底层逻辑,因此count()既可以统计string中某字符串出出现的个数,又可以统计list中元素出现的个数
描述
写出一个程序,接受一个由字母、数字和空格组成的字符串,和一个字母,然后输出输入字符串中该字母的出现次数。不区分大小写,字符串长度小于500。
输入描述:
第一行输入一个由字母和数字以及空格组成的字符串,第二行输入一个字母。
输出描述:
输出输入字符串中含有该字符的个数。
1 | str = input() |
3H明明的随机数[0]
数组
描述
明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性,他先用计算机生成了N个1到1000之间的随机整数(N≤1000),对于其中重复的数字,只保留一个,把其余相同的数去掉,不同的数对应着不同的学生的学号。然后再把这些数从小到大排序,按照排好的顺序去找同学做调查。请你协助明明完成“去重”与“排序”的工作(同一个测试用例里可能会有多组数据(用于不同的调查),希望大家能正确处理)。
注:测试用例保证输入参数的正确性,答题者无需验证。测试用例不止一组。
当没有新的输入时,说明输入结束。
输入描述:
注意:输入可能有多组数据(用于不同的调查)。每组数据都包括多行,第一行先输入随机整数的个数N,接下来的N行再输入相应个数的整数。具体格式请看下面的”示例”。
输出描述:
返回多行,处理后的结果
1 | import sys |
4H字符串分隔
字符串
思路/考点
注意slice的运用,同时对于需要对其的字符串使用ljust–左对齐–右填充
描述
•连续输入字符串,请按长度为8拆分每个字符串后输出到新的字符串数组;
•长度不是8整数倍的字符串请在后面补数字0,空字符串不处理。
输入描述:
连续输入字符串(输入多次,每个字符串长度小于100)
输出描述:
输出到长度为8的新字符串数组
1 | while True: |
使用ljust()、rjust()、center()
parameters:width(contains oneself), fillchar
是对齐方向ljust,左对齐右填充
5M进制转换
字符串
思路/考点
使用int(str, base=n)进行进制的直接转化,其中输入的str是在base的基础上的值,此操作将会返回一个int值(base=10)
同理bin(str, base=n) 将会返回一个int值(base=2)开头为0b
0b在c语言中表示二进制
描述
写出一个程序,接受一个十六进制的数,输出该数值的十进制表示。
输入描述:
输入一个十六进制的数值字符串。
输出描述:
输出该数值的十进制字符串。不同组的测试用例用\n隔开。
1 | while True: |
6M质数因子
排序/递归
思路/考点
描述
功能:输入一个正整数,按照从小到大的顺序输出它的所有质因子(重复的也要列举)(如180的质因子为2 2 3 3 5 )
最后一个数后面也要有空格
输入描述:
输入一个long型整数
输出描述:
按照从小到大的顺序输出它的所有质数的因子,以空格隔开。最后一个数后面也要有空格。
1 | def factor(n): |
7E取近似值
数学/语法
思路/考点
- int()函数如果接受的是个float数,他将只取整数位抛弃小数位
- //也是只取整数位
写出一个程序,接受一个正浮点数值,输出该数值的近似整数值。如果小数点后数值大于等于5,向上取整;小于5,则向下取整。
1 | num = int(float(input())+0.5) |
8M合并表记录
几何/哈希
思路/考点
考察dict的访问:
- for i in dict–>access key
- for key in dict.keys–>accsee key
- for key, val in dict.item–>access key and val
- dict[key]–>access key对应的val, 没有的话返回KeyError
- dict.get(key, val(default:None))–>访问dict中key对应的值,没有的话返回val
有与dict中的key不可以直接修改,如果要修改key需要以下操作
第一种方法:将需要修改的键对应的值用dict.pop() 的方法提取出来,并重新赋值给新的键,即dict[新的键] = dict.pop(旧的键)。(字典dict的pop是删除某个键及其对应的值,返回的是该键对应的值)
1 | dict={'a':1, 'b':2} |
第二种方法:结合dict.pop() 和dict.update() 的方法。(字典dict的pop是删除某个键及其对应的值,返回的是该键对应的值)
1 | dict={'a':1, 'b':2} |
第三种方法:结合直接修改和del语句。先用直接修改的方式将旧键赋值给新的键,再用del语句删除原来的键名。
1 | dict={'a':1, 'b':2} |
描述
数据表记录包含表索引和数值(int范围的正整数),请对表索引相同的记录进行合并,即将相同索引的数值进行求和运算,输出按照key值升序进行输出。
输入描述:
先输入键值对的个数
然后输入成对的index和value值,以空格隔开
输出描述:
输出合并后的键值对(多行)
1 | num = int(input()) # 共输入几组key-val |
9M提取不重复的整数
数组/位运算/哈希
描述
输入一个int型整数,按照从右向左的阅读顺序,返回一个不含重复数字的新的整数。
保证输入的整数最后一位不是0。
输入描述:
输入一个int型整数
输出描述:
按照从右向左的阅读顺序,返回一个不含重复数字的新的整数
1 | temp = input() |
:m:’’.join()将list中的元素转化成string,如果list中有number,则需要使用格式''.join('%s' %i for i in list)
10E字符个数统计
字符串/哈希
思路/考点
- 如何记录已存在的值,如果当前值已经存在,则跳过该值的后续操作
描述
编写一个函数,计算字符串中含有的不同字符的个数。字符在ASCII码范围内(0~127,包括0和127),换行表示结束符,不算在字符里。不在范围内的不作统计。多个相同的字符只计算一次
例如,对于字符串abaca而言,有a、b、c三种不同的字符,因此输出3。
输入描述:
输入一行没有空格的字符串。
输出描述:
输出 输入字符串 中范围在(0~127,包括0和127)字符的种数。
1 | while True: |
11E数字颠倒
字符串
思路/考点
- 考察对tuple/string/list使用slice操作[::-1]
输入一个整数,将这个整数以字符串的形式逆序输出
程序不考虑负数的情况,若数字含有0,则逆序形式也含有0,如输入为100,则输出为001
输入一个int整数
将这个整数以字符串的形式逆序输出
1 | temp = input()[::-1] |
12E字符串反转
字符串
思路/考点
接受一个只包含小写字母的字符串,然后输出该字符串反转后的字符串。(字符串长度不超过1000)
输入一行,为一个只包含小写字母的字符串。
输出该字符串反转后的字符串。
Essrntial:同11数字颠倒
13H句子逆序
数组
思路/考点
- 控制输入,使用split()将输入的string转化成list,以方便后续操作
- 控制输出,使用.join(),将list转化成string,其中sep=‘ ’
将一个英文语句以单词为单位逆序排放。例如“I am a boy”,逆序排放后为“boy a am I”
所有单词之间用一个空格隔开,语句中除了英文字母外,不再包含其他字符
输入一个英文语句,每个单词用空格隔开。保证输入只包含空格和字母。
得到逆序的句子
I am a boy
boy a am I
1 | while True: |
14M字符串排序
输入一定的字符串,将字符串按照字母优先级进行排序
1 | words = [] |
sort()即可进行数字排序也可以对单词按照字母优先级进行排序
15E求int数据在存贮中使用1的个数
位运算
思路/考点
- 使用bin()将输入的base=10数据转化成binary数据(str)
- 使用str的slice将0b(二进制开头)去除[2:]
- 使用.count(‘item’) 返回str中‘item’出现的次数
描述
输入一个int型的正整数,计算出该int型数据在内存中存储时1的个数。
输入描述:
输入一个整数(int类型)
输出描述:
这个数转换成2进制后,输出1的个数
1 | temp = bin(int(input())) |
16M购物单【:star::star::star:】
动态规划
思路/考点
描述
王强今天很开心,公司发给N元的年终奖。王强决定把年终奖用于购物,他把想买的物品分为两类:主件与附件,附件是从属于某个主件的,下表就是一些主件与附件的例子:
| 主件 | 附件 |
|---|---|
| 电脑 | 打印机,扫描仪 |
| 书柜 | 图书 |
| 书桌 | 台灯,文具 |
| 工作椅 | 无 |
如果要买归类为附件的物品,必须先买该附件所属的主件。每个主件可以有 0 个、 1 个或 2 个附件。附件不再有从属于自己的附件。王强想买的东西很多,为了不超出预算,他把每件物品规定了一个重要度,分为 5 等:用整数 1 ~ 5 表示,第 5 等最重要。他还从因特网上查到了每件物品的价格(都是 10 元的整数倍)。他希望在不超过 N 元(可以等于 N 元)的前提下,使每件物品的价格与重要度的乘积的总和最大。
设第 j 件物品的价格为 v[j] ,重要度为 w[j] ,共选中了 k 件物品,编号依次为 j 1 , j 2 ,……, j k ,则所求的总和为:
v[j 1 ]*w[j 1 ]+v[j 2 ]*w[j 2 ]+ … +v[j k ]*w[j k ] 。(其中 * 为乘号)
请你帮助王强设计一个满足要求的购物单。
输入描述:
输入的第 1 行,为两个正整数,用一个空格隔开:N m
(其中 N ( <32000 )表示总钱数, m ( <60 )为希望购买物品的个数。)
从第 2 行到第 m+1 行,第 j 行给出了编号为 j-1 的物品的基本数据,每行有 3 个非负整数 v p q
(其中 v 表示该物品的价格( v<10000 ), p 表示该物品的重要度( 1 **~** 5 ), q 表示该物品是主件还是附件。如果 q=0 ,表示该物品为主件,如果 q>0 ,表示该物品为附件, q 是所属主件的编号)
输出描述:
输出文件只有一个正整数,为不超过总钱数的物品的价格与重要度乘积的总和的最大值( <200000 )。
1 | money, things = map(int, input().split()) |
17H坐标移动
思路/考点
使用isdigit判断输入的字符串是否为整数;使用slice[start:end)
开发一个坐标计算工具, A表示向左移动,D表示向右移动,W表示向上移动,S表示向下移动。从(0,0)点开始移动,从输入字符串里面读取一些坐标,并将最终输入结果输出到输出文件里面。
输入:
合法坐标为A(或者D或者W或者S) + 数字(两位以内)
坐标之间以;分隔。
非法坐标点需要进行丢弃。如AA10; A1A; $%$; YAD; 等。
下面是一个简单的例子 如:
A10;S20;W10;D30;X;A1A;B10A11;;A10;
处理过程:
起点(0,0)
+ A10 = (-10,0)
+ S20 = (-10,-20)
+ W10 = (-10,-10)
+ D30 = (20,-10)
+ x = 无效
+ A1A = 无效
+ B10A11 = 无效
+ 一个空 不影响
+ A10 = (10,-10)
结果 (10, -10)
注意请处理多组输入输出
1 | while True: |
18H识别有效的IP地址和掩码并进行分类统计
字符串/查找
思路/考点
请解析IP地址和对应的掩码,进行分类识别。要求按照A/B/C/D/E类地址归类,不合法的地址和掩码单独归类。
所有的IP地址划分为 A,B,C,D,E五类
A类地址1.0.0.0~126.255.255.255;
B类地址128.0.0.0~191.255.255.255;
C类地址192.0.0.0~223.255.255.255;
D类地址224.0.0.0~239.255.255.255;
E类地址240.0.0.0~255.255.255.255
私网IP范围是:
10.0.0.0~10.255.255.255
172.16.0.0~172.31.255.255
192.168.0.0~192.168.255.255
子网掩码为二进制下前面是连续的1,然后全是0。(例如:255.255.255.32就是一个非法的掩码)
注意二进制下全是1或者全是0均为非法
注意:
\1. 类似于【0...】和【127..*.*】的IP地址不属于上述输入的任意一类,也不属于不合法ip地址,计数时可以忽略
\2. 私有IP地址和A,B,C,D,E类地址是不冲突的
输入描述:
多行字符串。每行一个IP地址和掩码,用~隔开。
输出描述:
统计A、B、C、D、E、错误IP地址或错误掩码、私有IP的个数,之间以空格隔开。
1 | ans = [0] * 7 |
19H简单错误记录
字符串
思路/考点
描述
开发一个简单错误记录功能小模块,能够记录出错的代码所在的文件名称和行号。
处理:
1、 记录最多8条错误记录,循环记录,最后只用输出最后出现的八条错误记录。对相同的错误记录只记录一条,但是错误计数增加。最后一个斜杠后面的带后缀名的部分(保留最后16位)和行号完全匹配的记录才做算是”相同“的错误记录。
2、 超过16个字符的文件名称,只记录文件的最后有效16个字符;
3、 输入的文件可能带路径,记录文件名称不能带路径。
4、循环记录时,只以第一次出现的顺序为准,后面重复的不会更新它的出现时间,仍以第一次为准
输入描述:
每组只包含一个测试用例。一个测试用例包含一行或多行字符串。每行包括带路径文件名称,行号,以空格隔开。
输出描述:
将所有的记录统计并将结果输出,格式:文件名 代码行数 数目,一个空格隔开,如:
示例1
输入:
1 | D:\zwtymj\xccb\ljj\cqzlyaszjvlsjmkwoqijggmybr 645 |
输出:
1 | rzuwnjvnuz 633 1 |
1 | # 初始全纪录list |
20H密码验证合格程序
字符串/数组
思路/考点
[如何检测字符串的类型是本题中的关键]
string.isxxx()检测
1 | isdecimal():判断给定字符串是否全为数字 |
[使用slice[i:i+3]]来控制子串,同时使用string.count([:])>1–>False控制子串是否有长度大于3且相等的情况]
密码要求:
1.长度超过8位
2.包括大小写字母.数字.其它符号,以上四种至少三种
3.不能有相同长度大于2的子串重复
输入
一组或多组长度超过2的字符串。每组占一行
输出
如果符合要求输出:OK,否则输出NG
1 | while True: |
21M简单密码
字符串
思路/考点
【考察】
- dict.get(key, defalut=Value)–>不存在return None
- ord与chr
- 字符串检测.isdigit()/is.upper()/.islower
描述
密码是我们生活中非常重要的东东,我们的那么一点不能说的秘密就全靠它了。哇哈哈. 接下来渊子要在密码之上再加一套密码,虽然简单但也安全。
假设渊子原来一个BBS上的密码为zvbo9441987,为了方便记忆,他通过一种算法把这个密码变换成YUANzhi1987,这个密码是他的名字和出生年份,怎么忘都忘不了,而且可以明目张胆地放在显眼的地方而不被别人知道真正的密码。
他是这么变换的,大家都知道手机上的字母: 1–1, abc–2, def–3, ghi–4, jkl–5, mno–6, pqrs–7, tuv–8 wxyz–9, 0–0,就这么简单,渊子把密码中出现的小写字母都变成对应的数字,数字和其他的符号都不做变换,
声明:密码中没有空格,而密码中出现的大写字母则变成小写之后往后移一位,如:X,先变成小写,再往后移一位,不就是y了嘛,简单吧。记住,z往后移是a哦。
输入描述:
输入包括多个测试数据。输入是一个明文,密码长度不超过100个字符,输入直到文件结尾
输出描述:
输出渊子真正的密文
1 | temp = input() |
22E汽水瓶
数学/模拟
思路/考点
【连续输入整数】
1 | while True: |
【从本质上讲为n//2–>return value】
描述
有这样一道智力题:“某商店规定:三个空汽水瓶可以换一瓶汽水。小张手上有十个空汽水瓶,她最多可以换多少瓶汽水喝?”答案是5瓶,方法如下:先用9个空瓶子换3瓶汽水,喝掉3瓶满的,喝完以后4个空瓶子,用3个再换一瓶,喝掉这瓶满的,这时候剩2个空瓶子。然后你让老板先借给你一瓶汽水,喝掉这瓶满的,喝完以后用3个空瓶子换一瓶满的还给老板。如果小张手上有n个空汽水瓶,最多可以换多少瓶汽水喝?
输入描述:
输入文件最多包含10组测试数据,每个数据占一行,仅包含一个正整数n(1<=n<=100),表示小张手上的空汽水瓶数。n=0表示输入结束,你的程序不应当处理这一行。
输出描述:
对于每组测试数据,输出一行,表示最多可以喝的汽水瓶数。如果一瓶也喝不到,输出0。
1 | while True: |
23H删除字符串中出现次数最少的字符
字符串
思路/考点
【方向点】
- 如何找到出现次数最小的元素
- 如何再字符串中剔除1中的元素
- string.replace(ele, ‘target’)用于替换字符串中的元素,其中可以用于删除/更改操作
【method1】创建一个unicode(list)记录每个ele出现的次数,如果ele出现的次数不等于min,则跳过result
描述
实现删除字符串中出现次数最少的字符,若多个字符出现次数一样,则都删除。输出删除这些单词后的字符串,字符串中其它字符保持原来的顺序。
注意每个输入文件有多组输入,即多个字符串用回车隔开
输入描述:
字符串只包含小写英文字母, 不考虑非法输入,输入的字符串长度小于等于20个字节。
输出描述:
删除字符串中出现次数最少的字符后的字符串。
方法一:使用unicode[list]来存贮每个ele的出现次数
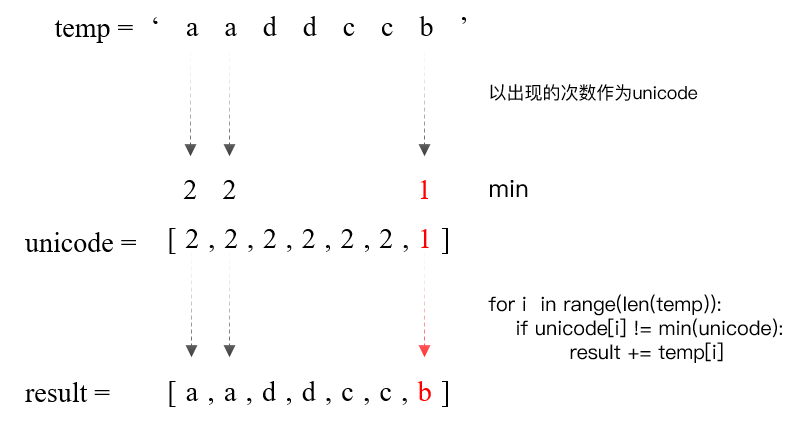
1 | # method1 |
方法二:使用hash table来存贮每个ele出现的次数

1 | a = min(dict.values) |
1 | while True: |
24H合唱队【:star::star::star:未解决】
动态规划/队列
思路/考点
描述
计算最少出列多少位同学,使得剩下的同学排成合唱队形
说明:
N位同学站成一排,音乐老师要请其中的(N-K)位同学出列,使得剩下的K位同学排成合唱队形。
合唱队形是指这样的一种队形:设K位同学从左到右依次编号为1,2…,K,他们的身高分别为T1,T2,…,TK, 则他们的身高满足存在i(1<=i<=K)使得T1<T2<……<Ti-1<Ti+1>……>TK。
你的任务是,已知所有N位同学的身高,计算最少需要几位同学出列,可以使得剩下的同学排成合唱队形。
注意:不允许改变队列元素的先后顺序 且 不要求最高同学左右人数必须相等
请注意处理多组输入输出!
备注:
1<=N<=3000
输入描述:
有多组用例,每组都包含两行数据,第一行是同学的总数N,第二行是N位同学的身高,以空格隔开
输出描述:
最少需要几位同学出列
1 | import bisect |
25H数据分类处理【未解决】
排序
思路/考点
输入描述:
一组输入整数序列I和一组规则整数序列R,I和R序列的第一个整数为序列的个数(个数不包含第一个整数);整数范围为0~0xFFFFFFFF,序列个数不限
输出描述:
从R依次中取出R,对I进行处理,找到满足条件的I:
I整数对应的数字需要连续包含R对应的数字。比如R为23,I为231,那么I包含了R,条件满足 。
按R从小到大的顺序:
(1)先输出R;
(2)再输出满足条件的I的个数;
(3)然后输出满足条件的I在I序列中的位置索引(从0开始);
(4)最后再输出I。
附加条件:
(1)R需要从小到大排序。相同的R只需要输出索引小的以及满足条件的I,索引大的需要过滤掉
(2)如果没有满足条件的I,对应的R不用输出
(3)最后需要在输出序列的第一个整数位置记录后续整数序列的个数(不包含“个数”本身)
序列I:15,123,456,786,453,46,7,5,3,665,453456,745,456,786,453,123(第一个15表明后续有15个整数)
序列R:5,6,3,6,3,0(第一个5表明后续有5个整数)
输出:30, 3,6,0,123,3,453,7,3,9,453456,13,453,14,123,6,7,1,456,2,786,4,46,8,665,9,453456,11,456,12,786
说明:
30—-后续有30个整数
3—-从小到大排序,第一个R为0,但没有满足条件的I,不输出0,而下一个R是3
6— 存在6个包含3的I
0— 123所在的原序号为0
123— 123包含3,满足条件
1 | instance |
1 | try: |
26H字符串排序
字符串
思路/考点
- 首先讲string中的element的alpha与number和others分离,这里采用.isdigit()
- 对alpha进行排序操作,再输入顺序的前提下对A/a这种相同元素的字母进行排序这里使用:sorted(iteration, key=lambda x:x.lower())
- 由于result中的值,是除了alpha之外的字符串,当检测到当前result为空(‘ ’)说明此处应该填上排好序的alpha,因此使用
if not x:进行控制
编写一个程序,将输入字符串中的字符按如下规则排序。
规则 1 :英文字母从 A 到 Z 排列,不区分大小写。
如,输入: Type 输出: epTy
规则 2 :同一个英文字母的大小写同时存在时,按照输入顺序排列。
如,输入: BabA 输出: aABb
规则 3 :非英文字母的其它字符保持原来的位置。
如,输入: By?e 输出: Be?y
1 | while True: |
27H查找兄弟单词
查找
思路/考点
描述
定义一个单词的“兄弟单词”为:交换该单词字母顺序(注:可以交换任意次),而不添加、删除、修改原有的字母就能生成的单词。
兄弟单词要求和原来的单词不同。例如:ab和ba是兄弟单词。ab和ab则不是兄弟单词。
现在给定你n个单词,另外再给你一个单词str,让你寻找str的兄弟单词里,按字典序排列后的第k个单词是什么?
注意:字典中可能有重复单词。本题含有多组输入数据。
输入描述:
先输入单词的个数n,再输入n个单词。 再输入一个单词,为待查找的单词x 最后输入数字k
输出描述:
输出查找到x的兄弟单词的个数m 然后输出查找到的按照字典顺序排序后的第k个兄弟单词,没有符合第k个的话则不用输出。
28M按照输入顺序排序[:star:]
题目
输入一串英文字符(含大小写), 将英文字符在ascending的基础上对于A,a等按照输入顺序排序
1 | a = input().strip() |
Leecode
1E.两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
思路:
- 使用双循环暴力求解,缺点是时间复杂度会很高
- 使用哈希表,记录上一个值和对应的index
1 | def solution1(alist, target): |
2M.两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
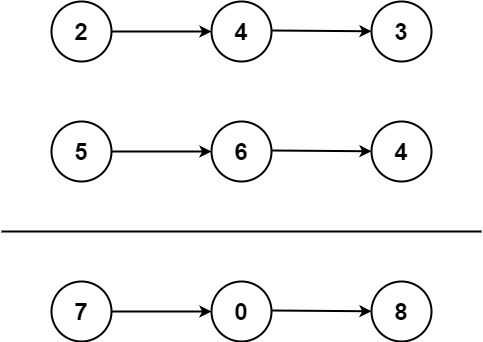
1 | def solution(l1, l2): |
3M求最长的回文子串
思路/考点
子序列!==子集
求子序列的问题可以理解成求解index的问题,通过控制[start:end)切片操作来实现字符串子序列的提取
chars=‘acbcd’的所有子字符串为:
{‘’, ‘b’, ‘cb’, ‘cbc’, ‘acbc’, ‘a’, ‘c’, ‘acb’, ‘bc’, ‘ac’}
找出长度最大的回文子串:
比如a,aba
1 | chars = "acbcd" |
4H最小路径[:star:DP/回溯]
从上到下找到最短路径(数宇之和最小),只能往下层走,同时只能走向相邻的节点,例如图中第一排2只能走向第二排的3、7﹔第一排的5可以走向第二排的1、7、3
| 1 | 8 | 5 | 2 |
|---|---|---|---|
| 4 | 1 | 7 | 3 |
| 3 | 6 | 2 | 9 |