# method 1 # 使用队列queue模拟 a = [1, 2, 3, 4, 1, 5] long = 0 queue = [] for ele in a: while ele in queue: queue.pop(0) queue.append(ele) long = max(long, len(queue)) print(long)
# methond 2 # list记录,再使用slice更新 arr = [2, 2, 3, 4, 8, 99, 3] long, cur_seq = 0, [] for i in arr: if i in cur_seq: long = max(long, len(cur_seq)) start = cur_seq.index(i) cur_seq = cur_seq[start + 1:] cur_seq.append(i) print(max(long, len(cur_seq)))
# methond3 # 动态规划 classSolution: defmaxLength(self, a): iflen(a) == 1: return1 dp = [0]*(len(a)+1) dp[0] = 0 cur_list = a[:1] for i inrange(1, len(a)): progress = self.dp_len(cur_list, a[i]) dp[i] = max(dp[i-1], progress[0]) cur_list = progress[1] returnmax(dp) # update the situation defdp_len(self, temp, ele): while ele in temp: temp.pop(0) temp.append(ele) returnlen(temp), temp
# methond1 [合并列表再排序,时间复杂度高] classSolution: defmerge(self , A, m, B, n): # write code here for i inrange(len(B)): A[m] = B[i] m += 1 index = len(A)-1 sign = False whilenot sign: sign = True for i inrange(index): if A[i] > A[i+1]: sign = False A[i], A[i+1] = A[i+1], A[i] index -= 1 return A # method2 [利用列表本身已经是排好序的,使用merge思想] A = [4, 5, 6] B = [1, 2, 3] m = 3 n = 3 ls = [] ifnot A: print(B) ifnot B: print(A) i = j = 0 while i < m and j < n: if A[i] <= B[j]: ls.append(A[i]) i += 1 else: ls.append(B[j]) j += 1 ls.extend(A[i:]) ls.extend(B[j:]) print(ls)
# method3 [利用merge排序但是思想上首先排最大值,因为对于AB来说都是已经排序号的链表] A = [4, 5, 6, 0, 0, 0] B = [1, 2, 3] m = 3 n = 3 ifnot A: print(B) ifnot B: print(A)
while m > 0and n > 0: if A[m-1] > B[n-1]: A[m+n-1] = A[m-1] m -= 1 else: lA[m+n-1] = B[n-1] n -= 1 # based on the poroblem, the B alwalys has the remaind ele < == > #==> m = 0; n> A[:n] = B[:n] print(A)
链表
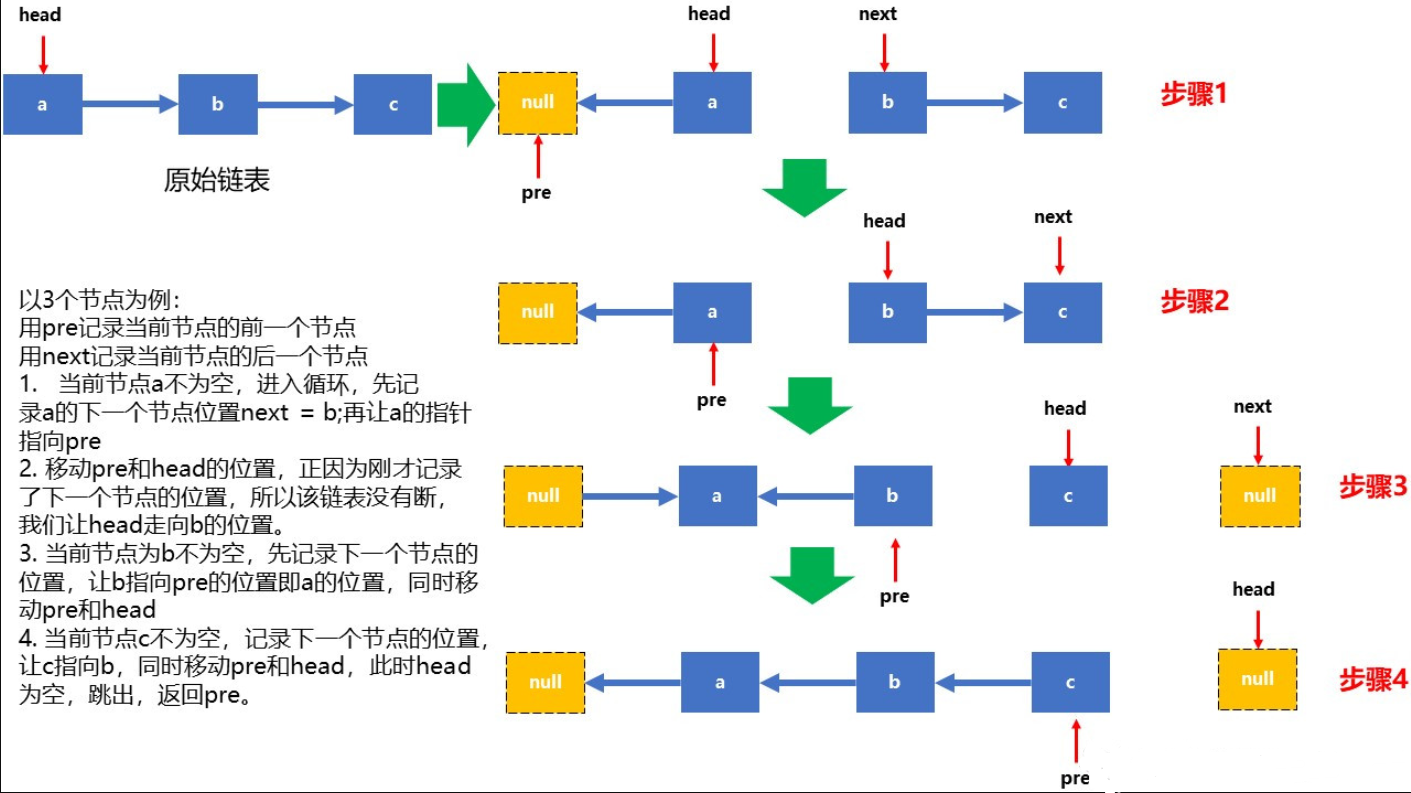
1.E反转链表
思路
【使用指针进行操作:使用前序赋值法替换】
输入一个链表,反转链表后,输出新链表的表头。
示例1
输入:
1
{1,2,3}
返回值:
1
{3,2,1}
1 2 3 4 5 6 7 8 9 10 11 12 13 14
classListNode: def__init__(self, x): self.val = x self.next = None classSolution: # 返回ListNode defReverseList(self, pHead): pre, cur, nex = None, pHead, None while c: nex = c.next cur.next = pre pre = cur cur = nex return pre
2.M链表中的节点每K个一组翻转
将给出的链表中的节点每\ k k 个一组翻转,返回翻转后的链表 如果链表中的节点数不是\ k k 的倍数,将最后剩下的节点保持原样你不能更改节点中的值,只能更改节点本身。
# 链表反转 classSolution: defreverseKGroup(self , head , k ): # write code here fast = head for _ inrange(k): ifnot fast: return head fast = fast.next new_head = self.reverse(head, fast) # 此时head变成了尾巴 # tail = head head.next = self.reverseKGroup(fast, k) return new_head defreverse(self, head, fast): last = None p = head while p isnot fast: temp = p.next p.next = last last = p p = temp return last
# list反转 temp = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] whileTrue: result = [] n = int(input('reverse number:')) if n >= len(temp): print('the number is too bigger, pls litter') continue for i inrange(0, len(temp), n): if i + n <= len(temp): result.extend((temp[i:i+n])[::-1]) else: result.extend(temp[i:]) print('->'.join('%s' %i for i in result))
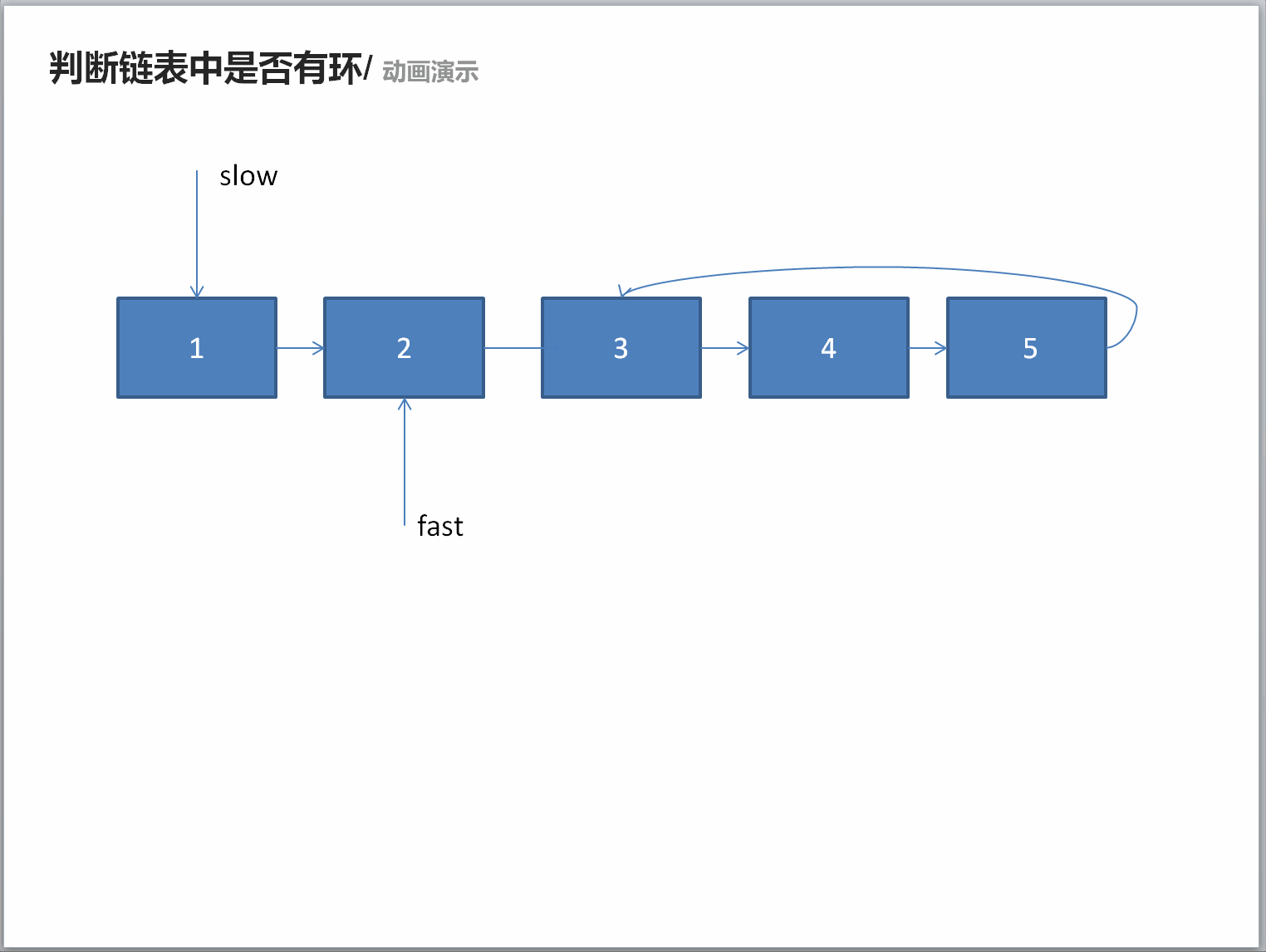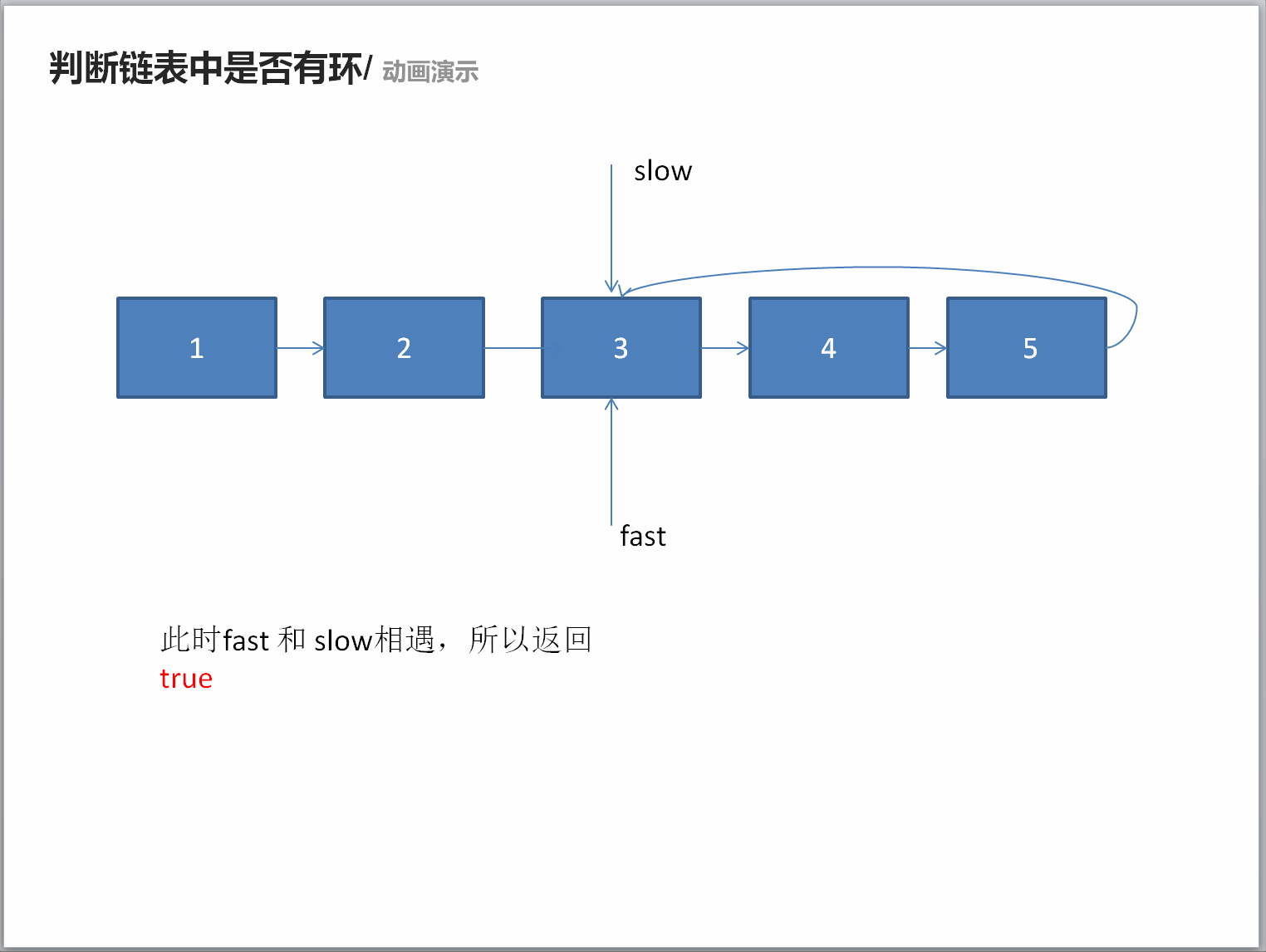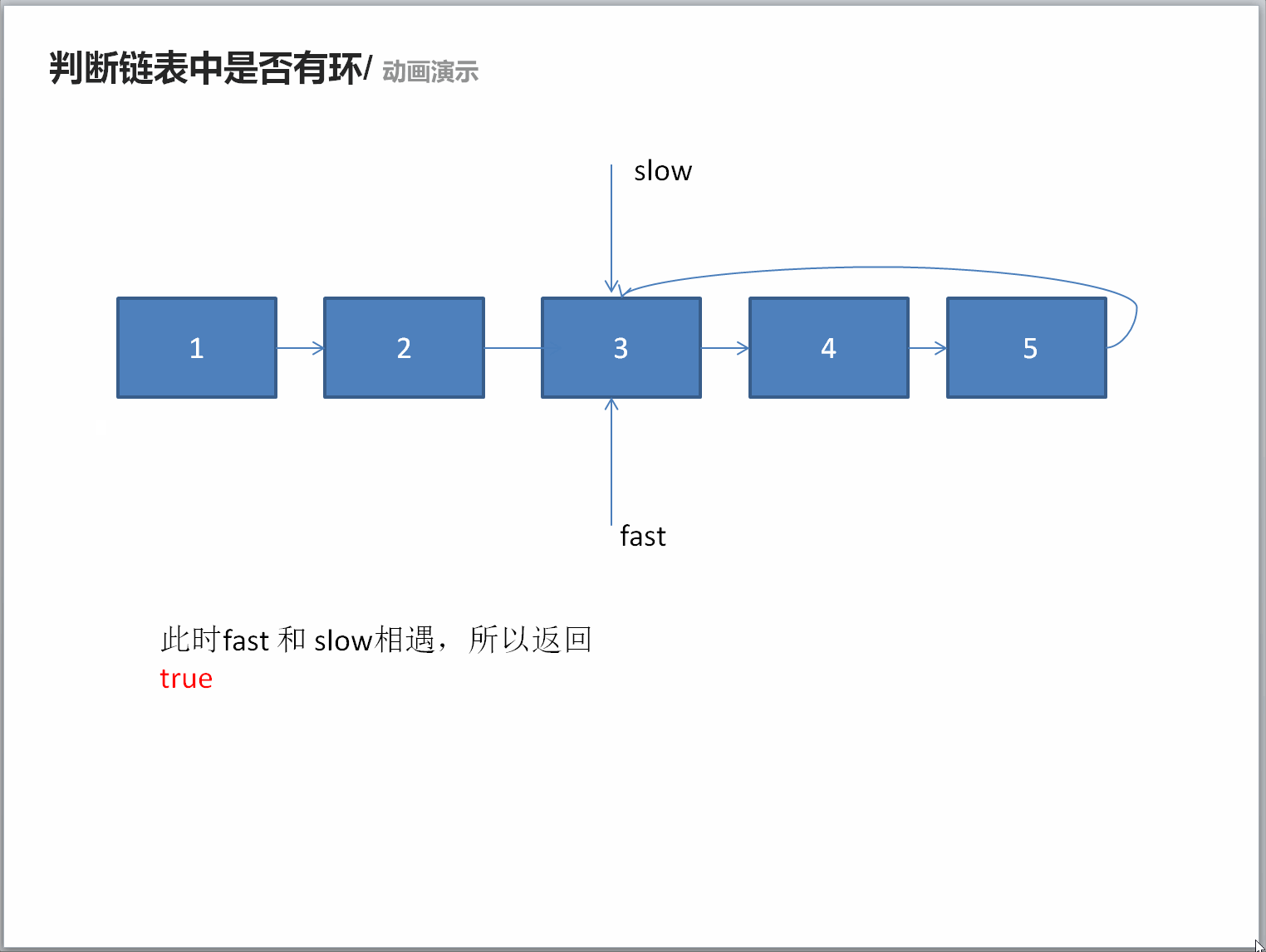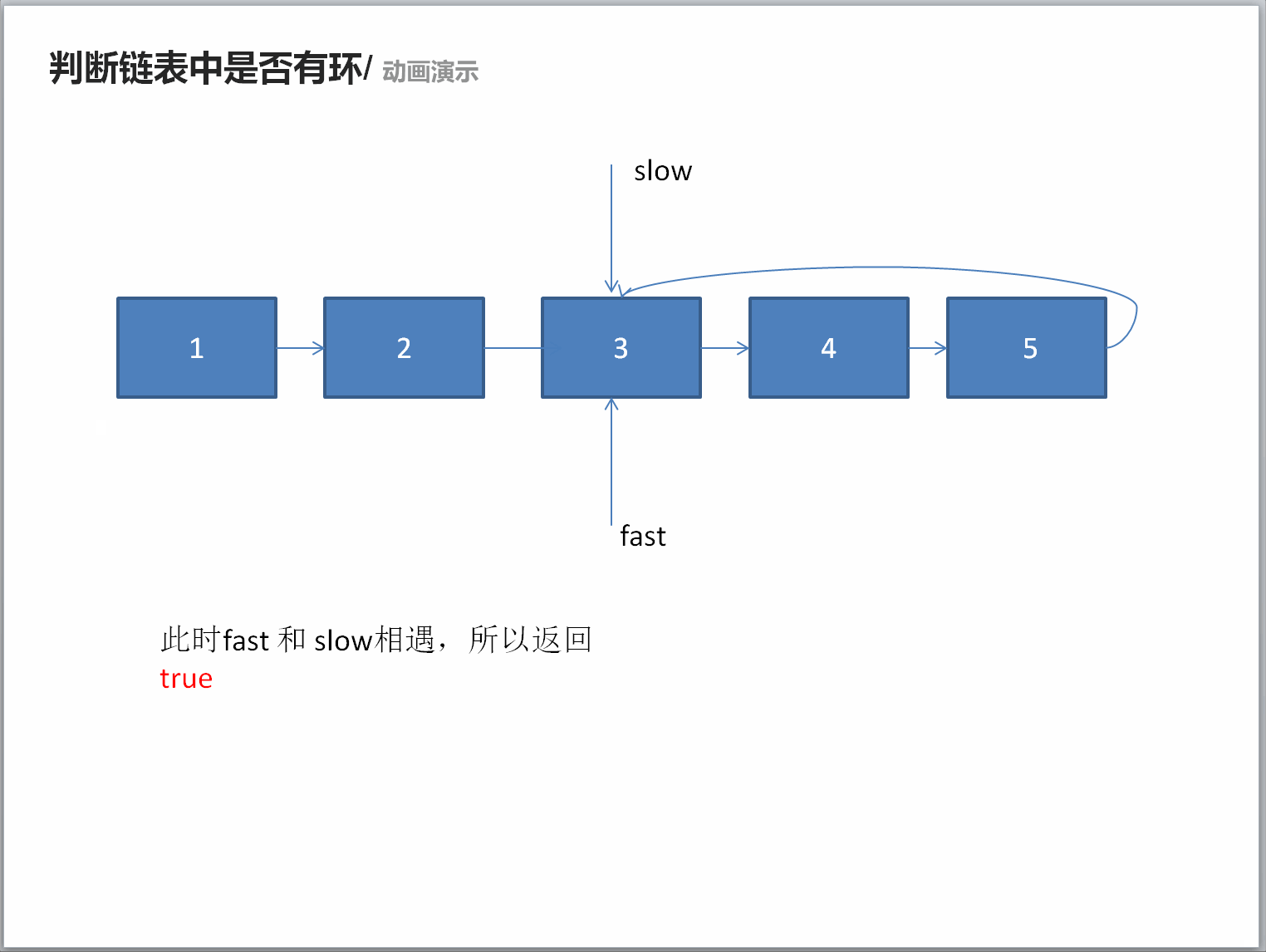
classSolution: defhasCycle(self , head ): if head isNoneor head.nextisNone: returnFalse slow = head fast = head.next while fast != slow: if fast isNoneor fast.nextisNone: returnFalse fast = fast.next.next slow = slow.next returnTrue
classSolution: deflevelOrder(self , root ): # write code here #队列解决 qune, res = [], [] ifnot root: return res qune.append(root) whilelen(qune)!=0: n = len(qune) temp = [] for i inrange(n): node = qune.pop(0) temp.append(node.val) if node.left: qune.append(node.left) if node.right: qune.append(node.right) res.append(temp) return res
classSolution: defPrint(self, pRoot): # write code here if pRoot == None: return [] # 定义两个栈,一个保存从左到右的打印的层的节点,一个保存从右到左打印的层的节点 stack1 = [] stack2 = [] stack1.append(pRoot) res = [] while stack1 or stack2: if stack1: tempValue = [] while stack1: tempNode = stack1.pop() tempValue.append(tempNode.val) if tempNode.left: stack2.append(tempNode.left) if tempNode.right: stack2.append(tempNode.right) res.append(tempValue) if stack2: tempValue = [] while stack2: tempNode = stack2.pop() tempValue.append(tempNode.val) if tempNode.right: stack1.append(tempNode.right) if tempNode.left: stack1.append(tempNode.left) res.append(tempValue) return res
# method1:暴力解法 classSolution: defmaxsumofSubarray(self , arr ): # write code here sum = arr[0] presum = 0 for ele in arr: if presum < 0: presum = ele else: presum += ele sum = max(presum, sum) returnsum
# method2:动态规划 classSolution: defmaxsumofSubarray(self , arr ): # write code here # dp[i]代表到第i位的时侯,以arr[i]结尾的连续子数组最大累加和 dp = [0] * len(arr) # 开辟dp res = arr[0] # 保存最终的结果 dp[0] = arr[0] # 初始化 for i inrange(1,len(arr)): # 维护dp[i], 如果<0,则舍弃cur dp[i] = max(dp[i-1],0) + arr[i] res = max(res,dp[i]) # 每更新一个dp值就更新一下res return res
# method3:动态规划 不仅可以return max number 还可以返回子串 a = [1, -2, 3, 5, -2, 6, -1]
for i inrange(1, l1): for j inrange(1, l2): if str1[i] == str2[j]: dp[i][j] = dp[i-1][j-1] + str1[i] iflen(dp[i][j]) > len(ans): ans = dp[i][j] print(ans)
for i inrange(l1): for j inrange(l2): if str1[i] == str2[j]: temp.append(str1[i])
print(temp)
5.M最长回文子串
思路
对于一个字符串,请设计一个高效算法,计算其中最长回文子串的长度。
给定字符串A以及它的长度n,请返回最长回文子串的长度。
1 2
输入:"abc1234321ab",12 return:7
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
classSolution: defgetLongestPalindrome(self, A, n): # write code here dp = [[0]*(n) for _ inrange(n)] maxL = 0 for right inrange(0, n): for left inrange(right,-1,-1): if A[left] != A[right]: continue if right - left <= 1: dp[right][left] = 1 else: dp[right][left] = dp[right-1][left+1] if dp[right][left]==1and right-left+1 > maxL: maxL = right-left+1 return maxL
# m, n = row * col classSolution: defuniquePaths(self , m , n ): # 创建DP时注意m,n的位置 dp = [[0]*n for _ inrange(m)] # 先traverse col 再 traverse row for i inrange(m): for j inrange(n): if i == 0or j == 0: dp[i][j] = 1 else: dp[i][j] = dp[i-1][j] + dp[i][j-1] return dp[-1][-1]
# 使用暴力双循环 classSolution: defmaxProfit(self , prices): # write code here ans = 0 for i inrange(len(prices)): for j inrange(len(prices)): if prices[j] - prices[i] > 0and i < j: temp = prices[j] - prices[i] ans = max(ans, temp) return ans
# 使用切片 classSolution: defmaxProfit(self , prices): # write code here ans = 0 for i inrange(len(prices)-1): temp = max(prices[i+1:]) ans = max(temp - prices[i], ans) return ans
8.M矩阵的最小路径和
思路
题目
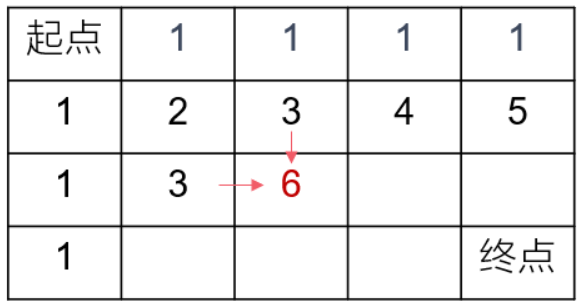
给定一个 n * m 的矩阵 a,从左上角开始每次只能向右或者向下走,最后到达右下角的位置,路径上所有的数字累加起来就是路径和,输出所有的路径中最小的路径和。
1
3
5
9
8
1
3
4
5
0
6
1
8
8
4
0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
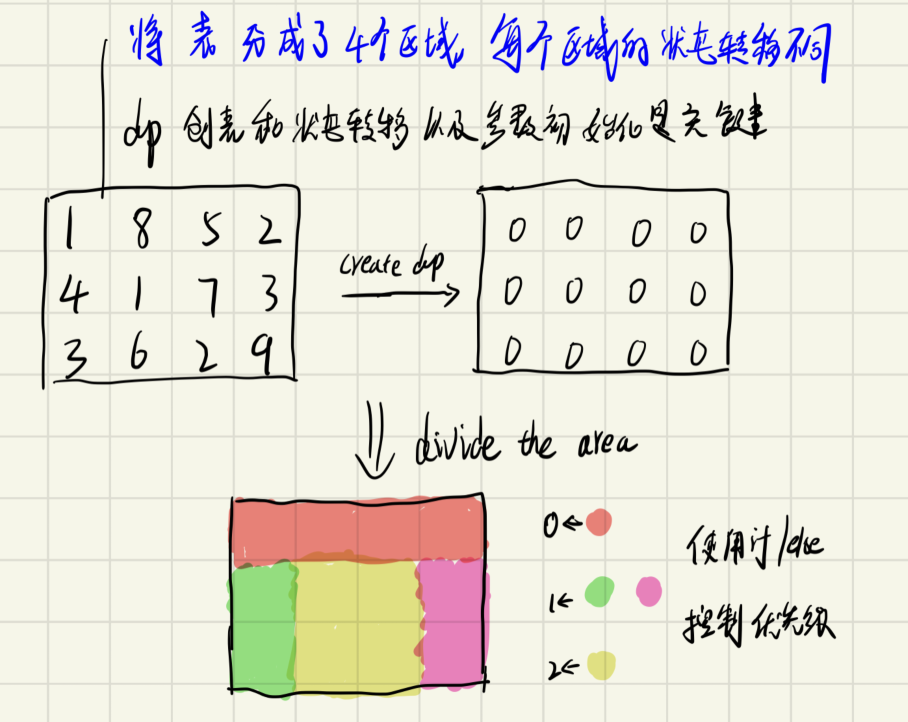
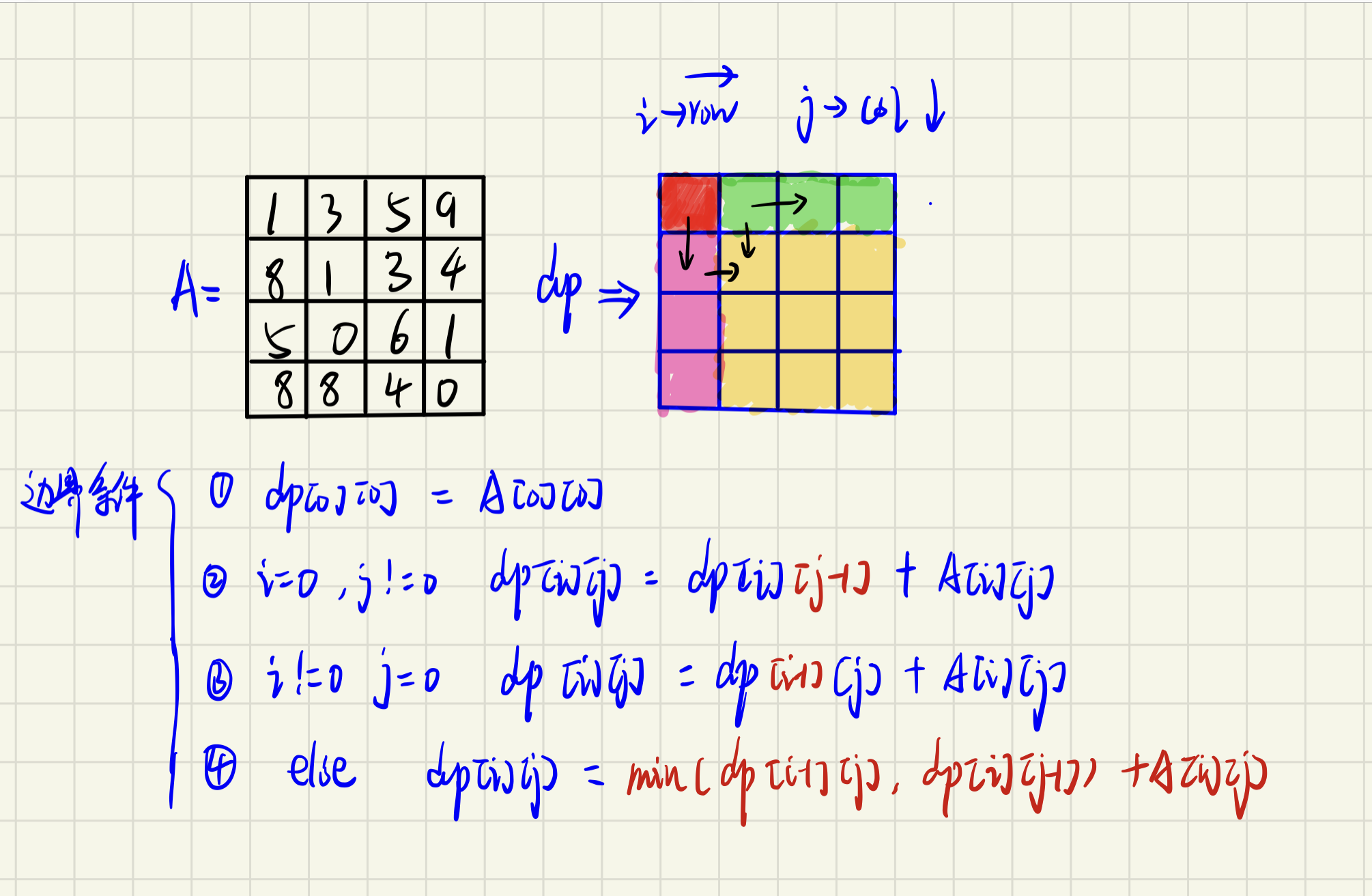
defminPathSum(self , matrix ): n, m = len(matrix), len(matrix[0]) dp = [[0]*m for _ inrange(n)] for i inrange(n): for j inrange(m): if i == 0and j == 0: dp[i][j] = matrix[0][0] elif i == 0and j != 0: dp[i][j] = dp[i][j-1] + matrix[i][j] elif i != 0and j == 0: dp[i][j] = dp[i-1][j] + matrix[i][j] else: dp[i][j] = min(dp[i-1][j], dp[i][j-1]) + matrix[i][j] return dp[-1][-1]
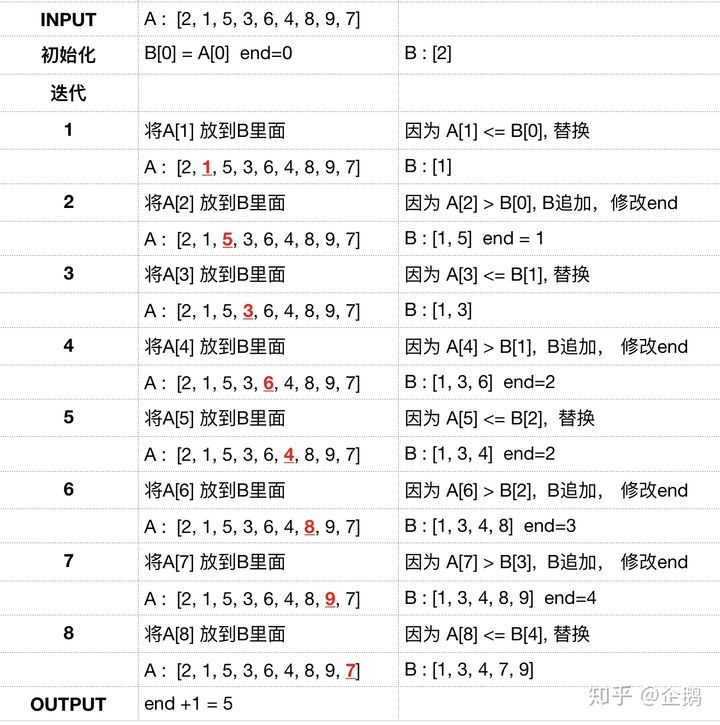
# 使用贪婪算法加二分算法 defget_lis_length(arr): temp = [arr[0]] end = 0
for i inrange(1, len(arr)): if arr[i] > temp[end]: end += 1 temp.append(arr[i]) else: pos = binary_search(temp, 0, len(temp), arr[i]) temp[pos] = arr[i] return end + 1
defbinary_search(arr, start, end, value): l = start r = end-1 while l <= r: m = (l + r) //2 if arr[m] == value: return m elif arr[m] < value: l = m + 1 else: r = m - 1 return l
# 使用dynamic programming classSolution: deflengthOfLIS(self, nums: List[int]) -> int: ifnot nums: return0 # 记录长度dp dp = [] for i inrange(len(nums)): dp.append(1) for j inrange(i): if nums[i] > nums[j]: dp[i] = max(dp[i], dp[j] + 1) returnmax(dp)
classSolution: defLIS(self , arr ): # write code here import bisect a=[] dp=[1]*len(arr) for i inrange(len(arr)): j=bisect.bisect_left(a, arr[i]) if j==len(a): a.append(arr[i]) else: a[j]=arr[i] dp[i]=j+1 L=len(a) for i inrange(len(dp)-1,-1,-1): if dp[i]==L: a[L-1]=arr[i] L-=1 return a
classSolution: defPermutation(self, s): defbfs(visited, unvisited): iflen(unvisited) == 0: res.append(visited) return d = set() for i, x inenumerate(unvisited): if x notin d: d.add(x) bfs(visited+x, unvisited[:i]+unvisited[i+1:]) res = [] bfs('', s) return res
deffindKth(a, start, end, K): low, high = start, end key = a[start] while start < end: while start < end and a[end] <= key: end -= 1 a[start] = a[end] while start < end and a[start] >= key: start += 1 a[end] = a[start] a[start] = key if start < K - 1: return findKth(a, start + 1, high, K) elif start > K - 1: return findKth(a, low, start - 1, K) else: return a[start]
try: while (1): line = sys.stdin.readline() if line == '': break lines = line.strip().replace('[', '').replace(']', '').split(',') lines = list(map(int, lines)) n, K = lines[-2], lines[-1] val = findKth(lines, 0, n - 1, K) print(val) except: pass
classSolution: defLRU(self , operators , k ): # write code here keys = [] d = {} res = [] for op in operators: if op[0] == 1: iflen(keys) == k: key = keys.pop(0) d.pop(key) keys.append(op[1]) d[op[1]]=op[2] if op[0] == 2: ans = d.get(op[1],-1) res.append(ans) if ans != -1: keys.remove(op[1]) keys.append(op[1]) return res