Part0.BulitIn
小知识
处理大数据
- 如果是类
->减少内存使用__slots__ - 如果是数值类型 使用
Numpyarraymemoryview
为什么说repr是开发者模式的str
因为eval(repr(obj)) –> obj
如果class中有self.__attr私有变量, 则无法通过eval(repr(obj))获取obj
1 | def repr(obj): # real signature unknown; restored from __doc__ |
self|cls
python中cls代表的是类的本身,相对应的self则是类的一个实例对象。
因为cls等同于类本身,类方法中可以通过使用cls来实例化一个对象。
cls通常于@classmethod搭配使用用于实例化类对象
反射
python的反射,它的核心本质其实就是利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动!
林奈结构
没有采用一贯的下行二分法体系(系统)而是采用在一个界(kingdom)之内只含有四个阶元层次:纲(class),目(order),属(genus),种(species)的等级结构的体系。
帮助
想知道某个类或者函数有方法以及其例子时, 可以使用dir()或者help()
比如想了解pandas.read_excel如何读取其title和data
1 | import pandas as pd |
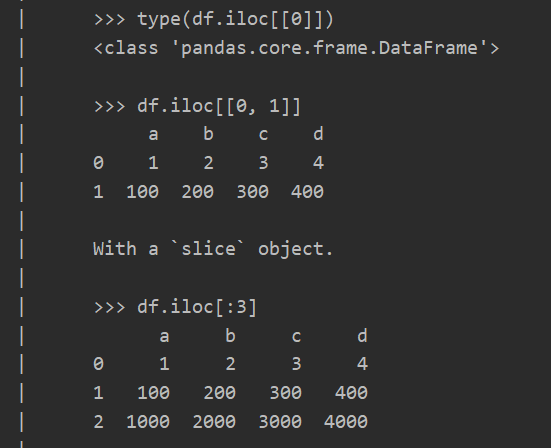
想了解一个函数或者对象要做什么事情可以使用__annotation__ __doc__ inspect.signature
annotation
1 | {'dtype': 'DtypeArg | None', 'storage_options': 'StorageOptions'} |
doc
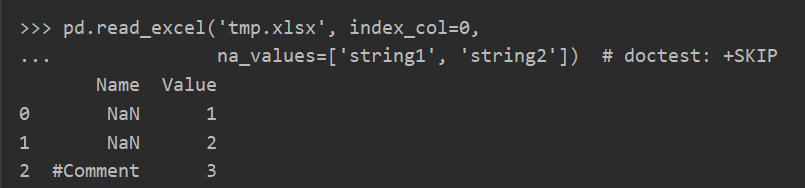
signature
1 | (io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype: 'DtypeArg | None' = None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options: 'StorageOptions' = None) |
下划线
| 模式 | 例子 | 含义 |
|---|---|---|
| 单前导 | _var |
命名约定, 内部私有变量, 解释器不强制执行, 除import * 外 |
| 单末尾 | var_ |
命名约定, 避免与关键字冲突 |
| 双前导 | __var |
类的上下位中使用, 名称修饰为_class__var避免属性被意外修改 |
| 双前导|双末尾 | __var__ |
magic method |
| 单下划 | _ |
占位符 |
format
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:+.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:>10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 | '{:b}'.format(11) '{:d}'.format(11) '{:o}'.format(11) '{:x}'.format(11) '{:#x}'.format(11) '{:#X}'.format(11) |
1011 11 13 b 0xb 0XB |
进制 |
^, <**, **> 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,**只能是一个字符[即只能填充一次]**,不指定则默认是用空格填充。
1 | # 即长度为多少 |
+ 表示在正数前显示 **+**,负数前显示 **-**; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
1 | # {} format |
Dis常用字节码
| Name | args | Info |
|---|---|---|
| LOAD_GLOBAL | namei | 加载名称为 co_names[namei] 的全局对象推入栈顶。 |
| LOAD_FAST | var_num | 将指向局部对象 co_varnames[var_num] 的引用推入栈顶。 |
| LOAD_CONST | consti | 将 co_consts[consti] 推入栈顶。 |
| CALL_FUNCTION | argc | 调用一个可调用对象并传入位置参数。 argc 指明位置参数的数量。 栈顶包含位置参数,其中最右边的参数在最顶端。 在参数之下是一个待调用的可调用对象。 CALL_FUNCTION 会从栈中弹出所有参数以及可调用对象,附带这些参数调用该可调用对象,并将可调用对象所返回的返回值推入栈顶。在 3.6 版更改: 此操作码仅用于附带位置参数的调用。 |
| POP_TOP | 删除堆栈顶部(TOS)项 | |
| STORE_FAST | var_num | 将 TOS 存放到局部对象 co_varnames[var_num]。 |
| RETURN_VALUE | 返回 TOS 到函数的调用者。 |
Attention
函数|方法返回
python 会对operation返回return None来表示对对象的就地更改, 即不会id(obj)不会变
- 用返回None来表示就地改动有一个弊端, 即调用者无法将其串联起来; 而返回一个新对象的方法(比如说str里的所有方法)则正好相反, 他们可以串联起来调用
sort
sort分为两种, 一种是value sort即根据值进行排序, 另一种是time sort即就算两个元素比不出大小, 但在每次排序的结果里他们的相对位置是固定的
推导式
- 一般推导式的作用
[]{}- 创建新的数据对象
- 过滤作用
Q&A
1.python中list和array的区别
- list是python的内置数据类型
- list中的数据类不必相同的
- array的中的类型必须全部相同
- 在list中的数据类型保存的是数据存放的地址,简单的说就是指针,并非数据
- 这种保存方式增加了存储和CPU的消耗例如list1=[1,2,3,’a’]需要4个指针和四个数据
- 数组在背后存的并不是float对象,而是数字的机器翻译,也就是字节表述。这一点和c语言中的数组一样
- array创建的数组不适用于数字操作(比如矩阵和矢量运算)。另外+=和*=运算符可以用于array的添加。
- 从python3.4开始,数组(array)类型不再支持诸如list.sort()这种就地排序方法。要给数组排序的话,得用sorted函数新建一个数组:
Magic Method
表1:跟运算符无关的 magic method
| 类别 | 方法名 |
|---|---|
| 字符串/字节序列表示形式 | repr str format bytes |
| 数值转换 | abs bool complex int float hash index |
| 集合模拟 | len getitem setitem delitem contains |
| 迭代枚举 | iter reversed next |
| 可调用模拟 | call |
| 上下文管理 | enter exit |
| 实例创建/销毁 | new init del |
| 属性管理 | getattr getattribute setattr delattr dir |
| 属性描述符 | get set delete |
| 跟类有关的服务 | prepare instancecheck subclasscheck |
表2:跟运算符相关的 magic method
| 类别 | 方法名和对应的运算符 |
|---|---|
| 一元运算符 | neg - pos + abs abs() |
| 众多比较运算符 | lt < le <= eq == ne != gt > ge >= |
| 算术运算符 | add + sub - mul * truediv / floordiv // mod % divmod divmod() pow **|pow() round round() |
| 反向算术运算符 | radd rsub rmul rturediv rfloordiv rmod rdivmod rpow |
| 增量赋值算术运算符 | iadd isub imul itruediv ifloordic imod ipow |
| 位运算符 | invert ~ lshift << rshift >> and & or | xor ^ |
| 反向位运算符 | rlshift rrshift rand rxor ror |
| 增量赋值位运算符 | ilshift irshift iand ixor ior |
1 | 注: 以下所有的keyword默认为 self.__xx__(): |
bool|len
默认情况下我们定义的类的实例总是被认为True,除非在define class中有实现bool或者len
bool()的背后其实是调用x.__bool__()的结果;如果x.__bool__()不存在, 则调用len()即x.__len__(),如果为0-False other-True
调用优先级为bool > len
1 | # define a class |
and|mul
and --> + add
mul --> * multiple
str|repr
两者的却别在于str will called by str() and print(), repr can only called by print()
如果两者特殊方法保留一个repr会是更好的选择, 因为在没有str时, 解释器会调用repr
优先级str > repr
1 | # define a class |
Moudle
functools
recude
对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
1 | sum2 = reduce(lambda x, y: x+y, [1,2,3,4,5]) |
os
listdir
列出目录下的所有文件和文件夹不包括
...隐藏目录
1 | import os |
locale
locale 是根据计算机用户所使用的语言,所在国家或者地区,以及当地的文化传统所定义的一个软件运行时的语言环境。通常情况下它可以按照涉及使用习惯分为12大类:
- 语言符号及其分类(LC_CTYPE)
- 数字(LC_NUMBERIC)
- 比较习惯(LC_COLLATE)
- 时间显示格式(LC_TIME)
- 货币单位(LC_MONETARY)
- 信息主要是提示信息,错误信息,状态信息,标题,标签,按钮和菜单等(LC_MESSAGES)
- 行么书写方式(LC_NAME)
- 地址书写方式(LC_ADDRESS)
- 电话号码书写方式(LC_TELEPHONE)
-度量衡表达方式(LC_MEASUREMENT) - 默认纸张尺寸大小(LC_PAPER)
- 对locale 自身包含信息的概述(LC_IDENTIFICATION)
- 除此之外还有一个LANGUAGE参数,它与LC_MESSAGES相似
time
time
process_time
process_time_ns
perf_counter
perf_counter_ns
time()精度上相对没有那么高,而且受系统的影响,适合表示日期时间或者大程序程序的计时。
perf_counter()适合小一点的程序测试,会计算sleep()时间。
process_counter()适合小一点的程序测试,不会计算sleep()时间。
此外Python3.7开始还提供了以上三个方法精确到纳秒的计时。分别是:
1 | time.perf_counter_ns() |
arrary
数组所接受的typecode以及其对应的存储数据类型
| Type code | C Type | Python Type | Minimum size in bytes | Notes |
|---|---|---|---|---|
| ‘b’ | signed char | int | 1 | |
| ‘B’ | unsigned char | int | 1 | |
| ‘u’ | Py_UNICODE | Unicode character | 2 | (1) |
| ‘h’ | signed short | int | 2 | |
| ‘H’ | unsigned short | int | 2 | |
| ‘i’ | signed int int | 2 | ||
| ‘I’ | unsigned int | int | 2 | |
| ‘l’ | signed long | int | 4 | |
| ‘L’ | unsigned long | int | 4 | |
| ‘q’ | signed long long int | 8 | (2) | |
| ‘Q’ | unsigned long long | int | 8 | (2) |
| ‘f’ | float | float | 4 | |
| ‘d’ | double | float | 8 |
bisect
bisect是一个根据二分算法写的库,其中主要的俩个方法是bisect和insert,根本上根据二分算法算出有序序列的索引,可以当做快速定位index使用
bisect|bisect_left
接受一个有序序列,一个元素,返回该元素在有序序列的索引,索引以前全≤该元素,bisect(bisect_right)|bisect_left主要区别是如果俩对比元素相等,前者返回index是从右边插入,后者左边
1 | import bisect |
insort
根据bisect或者bisect_left返回的index进行插入,接受有序序列,返回有序序列
itertools
groupby
和nlargest() nsmallest()一样支持key=
【聚合】
有时候我们需要给一个sequence按照某个属性分组,可以借助groupby来实现,groupby常常和lambda map operator.itemgetter一起使用,因为在分组前,大多希望相关的数据聚集在一起, 这样对于groupby来说分组才有意义
语法:
1 | groupby(seqence, key) |
注意:
- 如果groupby中的key=None,那么group后的key是被group中的element, 如果key=fun那么group后的key是fun(element)
- 返回的数据
- type(key) type(element)
- type(data) iterator
实列:
1 | a = [{'severity': '严重'}, {'severity': '严重'}, {'severity': '不严重'}, {'severity': '严重'}] |
operator
itemgetter
使用[]运算符, 不仅支持序列还支持映射和任何实现了
__getitem__方法的类
operator模块提供的itemgetter函数主要用于获取某一对象 特定维度的数据,其中的参数为特定维度的索引
operator.itemgetter函数获取的并不是某一个数值,而是某一个函数常常可以使用lambda 函数替换
用法:
1 | itemgetter(var) |
1 | import operator |
headq
nlargest
nsmallest
和groupby()一样支持key=
介绍:
这两个函数可以帮助我们在某个集合中找出最大或最小的N个元素
语法:
1 | def nlargest(n, iterable, key=None): |
random
- 注意如果在random.method之前使用了seed,那么random.method每次都将按照一定规则返回相同的数值
shuffle
语法:
1 | random.shuffle(iterable) |
实列:
1 | import random |
seed
调用 random.random()|shuffle 生成随机数时,每一次生成的数都是随机的。
但是,当使用 random.seed(x) 设定好种子之后,其中的 x 可以是任意数字,这个时候,先调用seed的情况下,使用 random() 生成的随机数将会是同一个
randrange
从指定范围内,按指定基数递增的集合中 获取一个随机数。
random.randrange([start], stop[, step])
1 | # 结果相当于从[10, 12, 14, 16, … 96, 98]序列中获取一个随机数。 |
sample
random.sample的函数原型为:random.sample(sequence, k)从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列。
1 | temp = [i for i in range(10)] |
dis
dis.dis
Python代码在执行的时候,会被编译为Python字节码,再由Python虚拟机执行Python字节码。有时候就我们执行python文件的时候会生成一个pyc文件,这个pyc文件即用于存储Python字节码指令,而这些字节码是一种类似于汇编指令的中间语言,但是每个字节码对应的不是机器指令,而是一段C代码。
而dis模块,就是用于查看这些字节码的运行轨迹,因此我们可以用dis模块判断两个函数的内存占用谁会更大,谁会更消耗CPU性能,不仅如此,通过指令,我们还可以知道Python中一些内置函数、变量的取值过程、运行逻辑,对于我们代码性能并优化代码很有帮助。
1 | import dis |
字节码操作:
假设
- ori_tuple = (1, 2, [10, 20])
- index = 2
- mutable_sequence = [30, 40]
6 BINARY_SUBSCR 将
ori_tuple[index]的值存入TOS(Top Of Stack)10 INPLACE_ADD 计算
ori_tuple[index] += mutable_sequence, 这一步骤可以完成, 是因为TOS指向的是一个可变对象14 STORE_SUBSCR 赋值, 这一步骤失败, 是因为tuple属于不可变序列(immutable)
我们从这个操作中可以得到三个教训:
- 不要把可变对象放在元组中
- 增量赋值(+=)不是一个原子操作, 在计算完后的赋值阶段如果抛出异常, 计算仍然会完成
譬如:
1 | b = (1, 2, [10, 20]) |
在上述实列中, 即使在最后的赋值阶段tuple抛出异常, 但是此时tuple的数据依然发生了改变!
| Python字节码 name(variable) | 执行操作 |
|---|---|
| LOAD_NAME | 将与 co_names[namei] 相关联的值推入栈顶。 |
| DUP_TOP_TWO | 复制堆栈顶部的两个引用,使它们保持相同的顺序。 |
| BINARY_SUBSCR | 实现 TOS = TOS1[TOS] 。 |
| INPLACE_ADD | 就地实现 TOS = TOS1 + TOS 。 |
| ROT_THREE | 将第二个和第三个堆栈项向上提升一个位置,顶项移动到位置三。 |
| STORE_SUBSCR | 实现 TOS1[TOS] = TOS2 。 |
| LOAD_CONST | 将 co_consts[consti] 推入栈顶 |
| RETURN_VALUE | 返回 TOS 到函数的调用者。 |
sys
getsizeof
1 | getsizeof(object, default) -> int |
获取对象所消耗的内存大小
argv
是一个从程序外部获取参数的桥梁,从外部取得的参数可以是多个,所以获得的是一个列表(list),也就是说sys.argv其实可以看作是一个列表,所以才能用[]提取其中的元素。其第一个元素是程序本身,随后才依次是外部给予的参数。
memoryview
memoryview**[内存视图]是一个内置类, 它能让用户在不复制内容的情况下操作同一个数组的不同切片,其实内存试图时泛化和去数学化的numpy数组**,它允许你在不复制内容的前提下,在数据结构之间共享内存, 其中数据结构可以是任何形式,这个功能在处理大型数据集合的时候十分重要
memoryview 语法:
1 | memoryview(obj) |
参数说明:
- obj – 对象
返回元组列表(物理地址)。
.cast
memoryview.cast的概念和数组模型差不多,能用不同的方式读写同一块内存地址,而且内容字节不会随意移动,和C语言中类型转换的概念相似.cast会把同一块内存里的内容打包成一个全新的memoryview对象给你
Method
all|any
都接受一个可迭代对象, 其中all是当可迭代对象中的元素都是True时返回True, any是有一个为True时则返回True
1 | d = all(map(lambda x: x > 10, [1, 10, 11])) |
eval
描述
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
语法
以下是 eval() 方法的语法:
1 | eval(expression[, globals[, locals]]) |
参数
- expression – 表达式。
- globals – 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
返回值
返回表达式计算结果。
isatty
isatty() 方法检测文件是否连接到一个终端设备,如果是返回 True,否则返回 False。
语法
isatty() 方法语法如下:
1 | fileObject.isatty() |
assert
python断言和try-except用法相反
断言函数是对表达式布尔值的判断,要求表达式计算值必须为真。可用于自动调试。
如果表达式为假,触发异常;如果表达式为真,不执行任何操作。
1 | assert condition |
reverse
reversed
s.reverse()就地排序,id(s)不变reversed(s)返回s的倒序迭代器
id
返回对象的物理存储地址, 一般用作操作符是或否创建了一个新对象, 比较两个对象的物理地址是否相同使用is
map
提供的函数对指定序列做映射。
1 | map(function, iterable, ...) |
filter
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
Python2.7 返回列表,Python3.x 返回迭代器对象
1 | filter(function, iterable) |
Python2.x 中返回的是过滤后的列表, 而 Python3 中返回到是一个 filter 类。
filter 类实现了 iter 和 next 方法, 可以看成是一个迭代器, 有惰性运算的特性, 相对 Python2.x 提升了性能, 节约内存。
abs|fabs[math]
Python 中 fabs(x) 方法返回 x 的绝对值。虽然类似于 abs() 函数,但是两个函数之间存在以下差异:
abs()是一个内置函数,而fabs()在math模块中定义的。fabs()函数只适用于float和integer类型,而abs()也适用于复数。
1 | import math |
hypot[math]
hypot() 返回欧几里德范数 sqrt(x*x + y*y)
hypot()是不能直接访问的,需要导入 math 模块,然后通过 math 静态对象调用该方法。
1 | #!/usr/bin/python |
bool
bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False用于判断真假
bool 是 int 的子类。
1 | issubclass(bool, int) # bool 是 int 子类 |
issubclass
issubclass(class, classinfo) --> return True|False
issubclass() 方法用于判断参数 class 是否是类型参数classinfo的子类
Part1.DataModel
1.具名元组
Python元组的升级版本 – namedtuple(具名元组)
因为元组的局限性:不能为元组内部的数据进行命名,所以往往我们并不知道一个元组所要表达的意义,所以在这里引入了 collections.namedtuple 这个工厂函数,来构造一个带字段名的元组。具名元组的实例和普通元组消耗的内存一样多,因为字段名都被存在对应的类里面。这个类跟普通的对象实例比起来也要小一些,因为 Python 不会用 dict 来存放这些实例的属性。
namedtuple 对象的定义如以下格式:
collections.namedtuple(typename, field_names, verbose=False, rename=False)
返回一个具名元组子类 typename,其中参数的意义如下:
- typename:元组名称
- field_names: 元组中元素的名称
- rename: 如果元素名称中含有 python 的关键字,则必须设置为 rename=True
- verbose: 默认就好
下面来看看声明一个具名元组及其实例化的方法:
1 | import collections |
2.列表表达式
1 | # 两者相等 |
3.random choice
1 | from random import choice |
4.Magic Method
1 | obj[key] |
5.迭代器与生成器
5.1迭代器
迭代是Python最强大的功能之一,是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
迭代器有两个基本的方法:iter() 和 **next()**。
字符串,列表或元组对象都可用于创建迭代器:
1 | list=[1,2,3,4] |
迭代器对象可以使用常规for语句进行遍历:
1 | #!/usr/bin/python3 |
也可以使用 next() 函数:
1 | #!/usr/bin/python3 |
5.2创建一个迭代器
把一个类作为一个迭代器使用需要在类中实现两个方法 iter() 与 next()
在定义类的时候都有一个构造函数,Python 的构造函数为 init(), 它会在对象初始化的时候执行。
iter() 方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 next() 方法并通过 StopIteration 异常标识迭代的完成。
next() 方法(Python 2 里是 next())会返回下一个迭代器对象。
创建一个返回数字的迭代器,初始值为 1,逐步递增 1:
1 | class Numbers(): |
5.3生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
以下实例使用 yield 实现斐波那契数列:
1 | #!/usr/bin/python3 |
5.4迭代器和生成器对比
迭代器(iterator)是一个特殊的类,其中必有iterm和next方法,本质上是一个类|对象
- 除了使用class来定义一个迭代器外, 还可以使用iterm(obj)来快速生成一个迭代器对象
- 可以使用rais StopIteration来抛出exception阻止迭代器进入死循环
- 是一个可以记住遍历的位置的对象(本质上含有iterm和next)
生成器是一个含有yield的函数(generator),生成器是一个返回迭代器的函数,只能用于迭代操作,其实生成器也可以理解成一种特殊的迭代器
- 生成器是一个返回迭代器的函数
- 在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
- 调用一个生成器函数,返回的是一个迭代器对象
6.len为什么不是普通方法
如果x是一个python内置类型的实例, 那么len(x)中Cpython会直接调用这个类的属性,解释器将不走__len__()这个方法
杂谈
数据模型|对象模型
- python文档中大多使用数据模型, 而大多数喜欢使用对象模型
- 对象模型:计算机编程语言中对象的属性<==>数据模型
魔法方法
- python用这个方法来提供更多的元对象协议,目的是让语言的使用者和开发者拥有并使用同样的工具
元对象
the art of the MetaObject Protocal | AMOP- 元对象协议:那些对构建语言本身来讲很重要的对象, 以此为前提, 协议也可以看成是接口, 即是说, 元对象协议是对象模型(数据模型)的同义词, 他们的本质都是构建核心语言的API
Part2.DataStructure
2.0前言
在创建poython之前Guido曾为ABC语言贡献过代码, ABC语言是一个致力于为初学者设计变成环境的长达10的研究项目, 其中很多点子在现在看来任然具有python的特性如:
- 序列的泛型操作
- 内置的元组
- 映射类型
- 用缩进来构建源码
- 无需变量声明的强类型
python也从ABC继承了用统一风格处理序列数据这一特点, 无论是中数据结构(string|list|bytes|tuple|array|xml|element|database query)他们都公用一套操作:
- 迭代
- 切片
- 排序
- 拼接
2.1内置序列类型
python使用C实现了两大类序列类型:容器序列 扁平序列
两者的却别前者支持存储不同类型的数据; 后者仅支持一种类型的数据
容器序列: list tuple collection.deque
- 存放的是任意类型的对象的引用
- 支持存储不同数据类型
- 非连续内存存储
扁平序列: str bytes bytearray memoryvivew arrary.arrary
- 存放的是值而不是引用
- 只能存储一种数据类型[字符 字节 数值]
- 连续存储
根据是否可以被修改可以分为:可变序列 不可变序列
从UML图中可以看出两者之间的部分继承关系,但是内置的序列类型不是直接sequence和mutale sequence这两个抽象基类继承来的Abstarct Base Class | ABC
| immutable sequence | mutable sequence | |
|---|---|---|
| *getitem | y | |
| *setitem | y | |
| *delitem | y | |
| *contains | y | |
| *iter | y | |
| *reversed | y | |
| *iadd | y | |
| index | y | |
| insert | y | |
| append | y | |
| reverse | y | |
| extend | y | |
| pop | y | |
| remove | y | |
| count | y |
2.2 列表推导和生成器表达
list comprehension and generator expression
[]: 列表推导式
(): 生成器表达式
列表推导式: 快速构建list
使用原则:
列表推导式的作用只有一个:生成列表
创建新列表
尽量保持简短
在
py3.x中修复了列表推导是中的变量泄露问题(通过局部作用域修复)使用
filter + map也可以达到相同效果注意:
filter返回的是一个迭代器两者的效率根据不同情况表现不一样
1 | temp = '!@#$%' |
2.2.1 笛卡尔积
1 | col_1 = ["A", "B", "c"] |
列表推导式和双层
for循环俩者执行顺序一样
2.2.2生成器表达式
使用列表推导也可以初始化元组|数组|其他序列,但是生成器表达式是一个更好的选择, 因为背后支持迭代器协议,可以逐个产出元素而非先建立一个完整的list,可以更好的节省内存
生成器表达式和列表推导式的区别是:
[]()- 生成一个完整的
list; 迭代器
2.3 元组
元组: 是一个不可变的list; 记录一定的维度[位置]的数据信息
元组的拆包
本质上是将元组中的数据提取
元组的拆包方式在任意可迭代对象中都是通用的
for-loop**拆包返回的是list
平行赋值
a, b = b, a本质上也是拆包可以使用
_占位符来过滤掉不需要的数据
1 | # 1.for-loop |
2.3.1 具名元组
collections.namedtuple构建的类的实例所消耗的内存和元组一样, 因为字段名都存在了相应的类里
1 | # namedtuple |
除了从普通元组继承的属性之外, 具名元组还有独特的属性:_fields类属性|类方法|_make(iterable)和实列方法_asdict()
1 | ... |
2.3.2 不可变列表[元组]
元组支持列表的大多数操作除了增删改元素之外
2.4切片
- 切片支持大多数
可变序列 - 切片的数学表达式为
[<= <) - 区间运算
start default=0 s[a:b:c] start end step其中step可以为负即反向取值
本质上在使用slice取值时, python会调用seq.__getitem__(slice(start, end, step))
或者说slice()是一个切片对象, 可以改切片命名就像excel--sheet一样
1 | name_slice = slice(0, 5) |
2.4.1 多维切片|省略
多维切片所支持的数据序列也是多维度,而python内置的数据序列都是一维的
本质上多维切片seq[i, j]| seq[m:n, i:j]调用的是seq.__getitem__((i, j))或者seq.__setitem((i, j))
省略...在python解释器中是一个符号,其实本质上Ellipsis对象的别称
如果x是四维数组,那么x[i:...]就是x[i:::]的缩写
2.4.2 切片赋值
- 通过切片赋值右边必须是可迭代对象
2.5 对序列使用+和*
+和*都遵守一条规律即不修改原有的操作对象而是创建一个全新的序列+通常是相同类型的数据在操作中python会创建一个包含相同类型数据的序列作为拼接的结果
注意在使用
seq * n操作时, 如果seq里的元素是对其他可变对象的引用的话, 虽然* n拼接了, 但本质上还是对seq的引用, 对其进行操作时很可能会出现”多重操作”
示例:
1 | a = [["_"] * 3 for i in range(3)] |
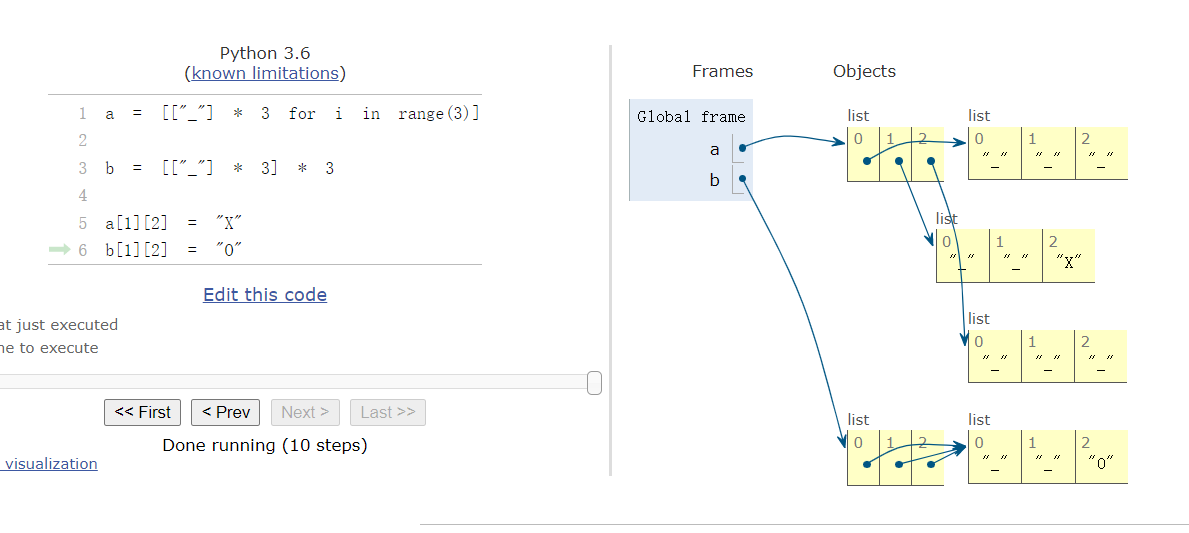
其中b时三个指向同一对象的引用
b所犯的错误和下面的错误一样
1 | # list中追加的是对同一对象的三次引用 |
2.6 序列的增量赋值
即就地增量 += *= (仅针对可变序列), 不可变序列增量拼接的话实现的是 + * 每次都会创建一个新对象,效率会很低(str除外, 因为对于str的拼接操作过于频繁, CPython对其进行优化)
在调用这些运算符中, python优先调用__iadd__|__imul__如果没有会次级调用__add__|__mul__
需要注意的是:
如果a实现了__iadd__那么+=会实现就地增量赋值,像a.extend(iterator) 否则会调用__add__, 此时不是就地增加,而是首先计算a + b得到一个新的对象, 然后再将对象赋值给a,即是否实现就地完全取决于这个类型有没有实现__iadd__
1 | aa = [1, 2, 3] |
对不可变序列进行重复拼接操作:
- 创建一个新对象
- 将原来对象的元素复制到新对象中
- 追加寻元素
str有优化:在为str初始化内存的时候,程序会为他流出额外的可扩展空间,因此进行增量操作的时候,并不会涉及复制原有字符串到新位置的这一操作
2.6.1 元组的增量赋值
1 | t = (1, 2, [1, 2]) |
- 元组中的元素被成功拼接
- 解释器抛出异常
其实写成t[2].extend([3, 4])就不会抛出异常了
1 | # 使用dis.dis展示操作的python字节码 |
- BINARY_SUBSCR: 将值存入stack (DONE)
- INPLACE_ADD 完成 += (DONE)
- STORE_SUBSCR 赋值 (ERROR)
可以得出:
- 不要把可变对象放在元组里
- 增量赋值不是一个原子操作
- 先计算
- 后赋值
2.7 排序.sort和sorted()
两者都是排序, 且内部算法使用的是
Timsort,它是一种自适应算法,会根据原始数据的顺序特点交替使用插入排序和并归排序,而且Timsort算法是稳定的(相等元素的相对位置保持不变)
seq.sort: 就地排序, 在原始数据的基础上排序, id不会改变, 这个方法返回
None- python operation返回
None表示就地修改, 不会创建新对象 - 如果函数或者方法对对象进行就地修改,那么就应该让他返回
None,通知调用者传入的参数发生改变,但并未创建新对象 random.shuffle(iterator)|id(iterator)不会修改- 返回
None表示就地改动又个弊端, 就是调用者无法串联接口,即始终使用的是一个对象引用
- python operation返回
sort(obj) 会返回一个新建的
list- 可以接收任何形式的可迭代对象作为参数,包括不可变序列和生成器
- 最后返回的是一个
list
两者都接受两个参数
reverse=False: 是否反向排序key=identity function:接收一个排序fun通常使用lambda函数- 恒等函数
(identity funtion)默认用元素自己的值进行排序 key=str.lower:忽略大小写排序key=len: 基于长度排序
- 恒等函数
接收
key参数:min|maxsort|.sortitertools.groupby()heapq.nlargest()|heapq.nsmller()
1 | import random |
2.8 bisect管理有序序列
bisect模块包含两个主要的函数bisect和insort, 两者都是通过二分法获取index并进行操作
bisect(haystack, needle), 在haystack中搜索needle其中:
haystack必须是有序的return index
bisect可以建立一个用数字作为索引的查询表格, 比如把表格和成绩对应起来
1 | import bisect |
bisect.insort(seq, item) 把变量item插入到有序序列seq中[本质上是通过二分法获取index后插入]
- 如果只是处理数字列表的话,
array是一个更好的选择
2.9 当list不是首选时
list可以处理多个数据类型,但当面对大量的数字类型时, array是一个更好的选择
- 数组存储的不是
num对象,而是数字的机器翻译(字节表述) - 和C语言的数组一样, 如果需要频繁的对序列进行进出操作,
deque的速度会更快 - 在处理
包含操作时,set是个更好的选择,python对此进行过优化,需要注意的是,set不是序列,他是无序的
2.9.1 数组
array.array在存储数字方面效率胜于list且支持list的基本操作,此外数组还提供从文件读取(.frombytes)和存入文件(.tofile)的快速方法
python中的数组和C一样, 在创建数组时都需要一个类型码,以表明要存储的数据类型
1 | from array import array |
method区别:
- 数组不支持浅拷贝|但支持
__deepcopy__ - 数组支持
seq.reverse()但不支持seq.__reversed__() - 数组不支持就地排序
seq.sort()
从python3.4开始数组不再支持就地排序seq.sort(), 如果需要排序得用sorted函数重新建立一个数组
a = array.array(a.typecode, sorted(a))
2.9.2 内存视图
memoryview是一个内置类, 可以让用户在不复制内容的情况下操作同一数组的不同切片
- 本质上是泛化和去数学化的
Numpy数组 - 可以在不需要复制内容的前提下,在任何数据结构之间共享内存
- 处理大数据很实用 –> 节省了数据copy内存和时间
- 需要注意是对原数据直接进行操作
memoryview.cast能用不同的方式读写同一块内存数据,并且内容字节不会随意移动,会把同一块内存里的内容打包成一个全新的memoryview.cast对象给你
不同方式:可以用不同的读写方式操作数据
1 | # init array 类型码“h” |
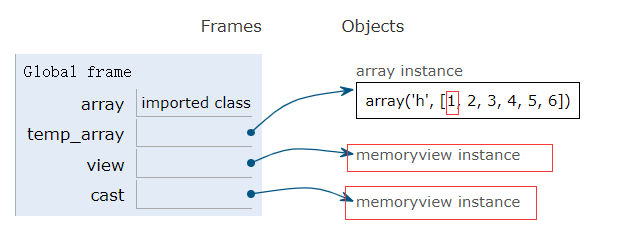
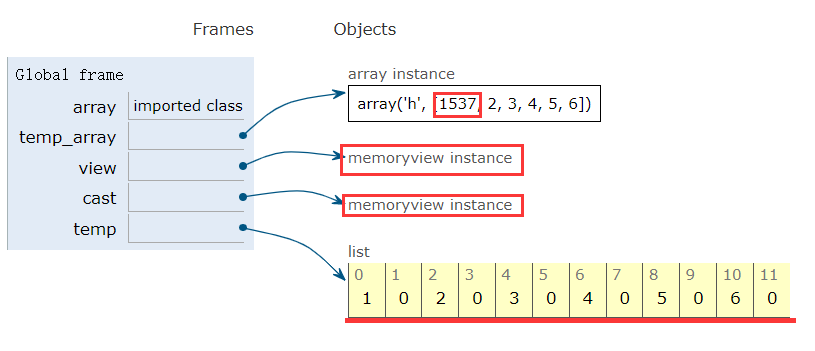
2.9.3 NumPy|SciPy
NumPy和SciPy提供了高阶数组和矩阵操作, python内置数据类型都是一维数据
维度: row
每个维度所含元素: col
1 | import numpy |
2.9.4 双向队列
用列表和append pop(0)可以实现队列 先进先出, 但是删除list中的第一个或者在第一元素前添加一个元素都是十分耗时的, 因为这涉及到所有元素的移动
collection.deque双端队列实现了队列两端元素操作的优化, 但是涉及到中间元素的操作依然会耗时, 并且是一个thread safe类
- 快速从两端对元素进行操作
- 存储最近使用的几个元素
collection.deque可以实现简单的过期机制<通过设置maxlen>append(item)|popleft(index)都是原子操作, 因此deque可以在多线程程序中安全地当作先进先出的栈使用, 而且使用者不需要担心资源锁问题
1 | from collections import deque |
2.10 线程安全
除了
collections.deque外还有其他python标准库也有对队列的实现
queue
提供了同步线程安全类Queue|LifoQueue|PriorityQueue,不同的线程可以利用这些数据类型来交换信息
- 线程通信
- 三个类构造时都有一个可选参数
maxsize用来限制队列大小 - 在满员时这些类并不会丢掉旧的元素腾出位置
- 而是会锁住资源, 直到另外的线程移除了某个元素
- 适合控制活跃线程的数量
multiprocessing
这个包实现了自己的Queue和queue.Queue类似, 是设计给进程通信用的还有一个multiprocessiong.JoinableQueue
- 进程通信
- 任务管理
asyncio
python3.4及以上提供, 里面有Queue LifoQueue PriorityQueue和JoinableQueue这些类受到queue和multiprocessing的影响,用于异步变成任务管理
- 异步编程
heapq
和上面三个模块不同, heapq没有队列类,而是提供了heappush和heappop方法, 可以让用户把可变序列当作堆队列或者优先队列使用
本章小结
可变序列 不可变序列
容器序列: 存储引用 非连续存储
扁平序列: 存储值 连续存储 原子性数据
列表: 列表中数据最好是具有相同特性的数据
拆包: 获取元组内数据最安全可靠的方法,*拆包的利器
具名元组: 将元组与数据关联
namedtuple()._asdict将具名元组转化成ordereddoctdict(zip(iter_key, iter_value))普通元组转化dict
序列切片是python中最受欢迎的语言特性之一
对切片赋值是一个修改可变序列的捷径
重复拼接n*seq要在正确的前提下使用!!!!!
- 初始化含有不可变元素的序列
增量赋值+= 和 *=的操作行为和序列本身有关(可变序列|不可变序列)
PS: string类型有优化不会重复复制原数据
可变序列: 就地修改
不可变序列: 生成新的序列
sort和sorted()与key的用法背后的逻辑是
timsort算法, 它是一种自适应算法, 会根据原始数据的特点交替使用插入排序和并归排序
元组的鼻祖是ABC语言中的compounds, tuple更准确的说是frozenlist
key参数
再使用默认函数key进行排序时Python总会比较两个键, 但是这一计算阶段发生在C语言层, 这也是比调用用户自定义比较函数快的原因
- 当
ele是int或者str时,key支持int或者strint: 比较整个数值str: 只比较第一位数值
1 | temp_1 = [3, 45, 2, "10", "34"] |
Part3.Dict|Set
dict的内置函数_builtins_.dict_, Python对字典实现了高度优化 –>hashtable
3.1 泛映射类型
collections.abc中含有Mapping和MutableMapping这俩个抽象类,为dict和其他类似的类型定义形式接口
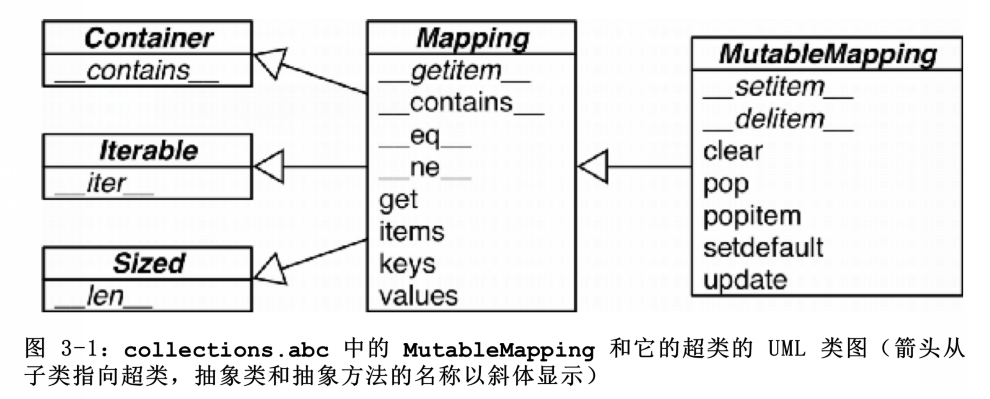
非抽象类一般不会直接继承这些抽象基类, 而是直接对dict或者collections.User.Dict进行扩展,这些抽象基类的主要作用是作为形式化的文档, 定义构建一个映射类型所需要的最基本接口.而且还可以与isinstance一起使用来判断某个数据是否是广义上的mapping类型
1 | my_dict = {} |
- 使用
isinstance而不是type - 可以判断除
dict外的广义映射类型
标准库的所有映射类型都是通过dict来实现的,他们有个共同的限制, 即key必须是可散列的
可散列数据
1 | An object is hashable if it has a hash value which never changes during its lifetime (it needs a __hash__() method), and can be compared to other objects (it needs an __eq__() method). Hashable objects which compare equal must have the same hash value. |
- 含有
__hash__散列 - 含有
__eq__比较key - 哈希值在整个声明周期不会变化
- 散列对象相等==>散列值一定相等
可散列的数据类型:
- str
- bytes
- 数值类型
- frozenset
- tuple(所含的元素全为可散列)
一般用户自定义的类型的对象都是可散列的, 其中散列值就是id(obj), 所以所有这些对象在比较时都是不相等的. 如果一个对象实现了__eq__方法, 并且在方法中用到了这个对象的内部状态的话, 那么只有当所有这些内部状态都是不可变的情况下, 这个对象才是可散列的
构造字典方法
1 | >> |
3.2 字典推导
推导式的作用:
创建新的数据对象
过滤作用
3.3 常见的映射方法
映射类型的方法很丰富, dict defalutdict 和OrderedDict的常见方法, 后面两个数据类型是dict的变种,位于collections模块内
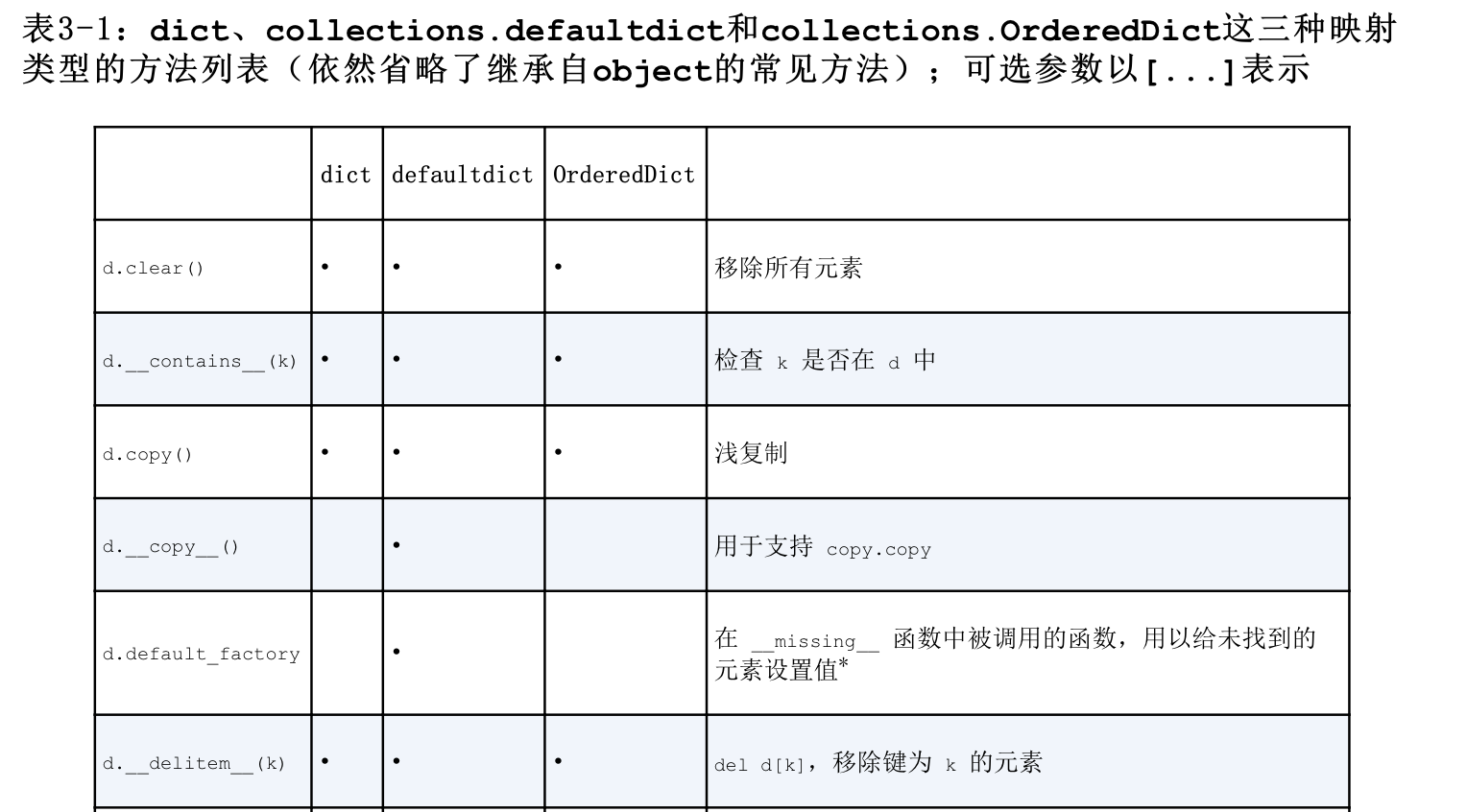
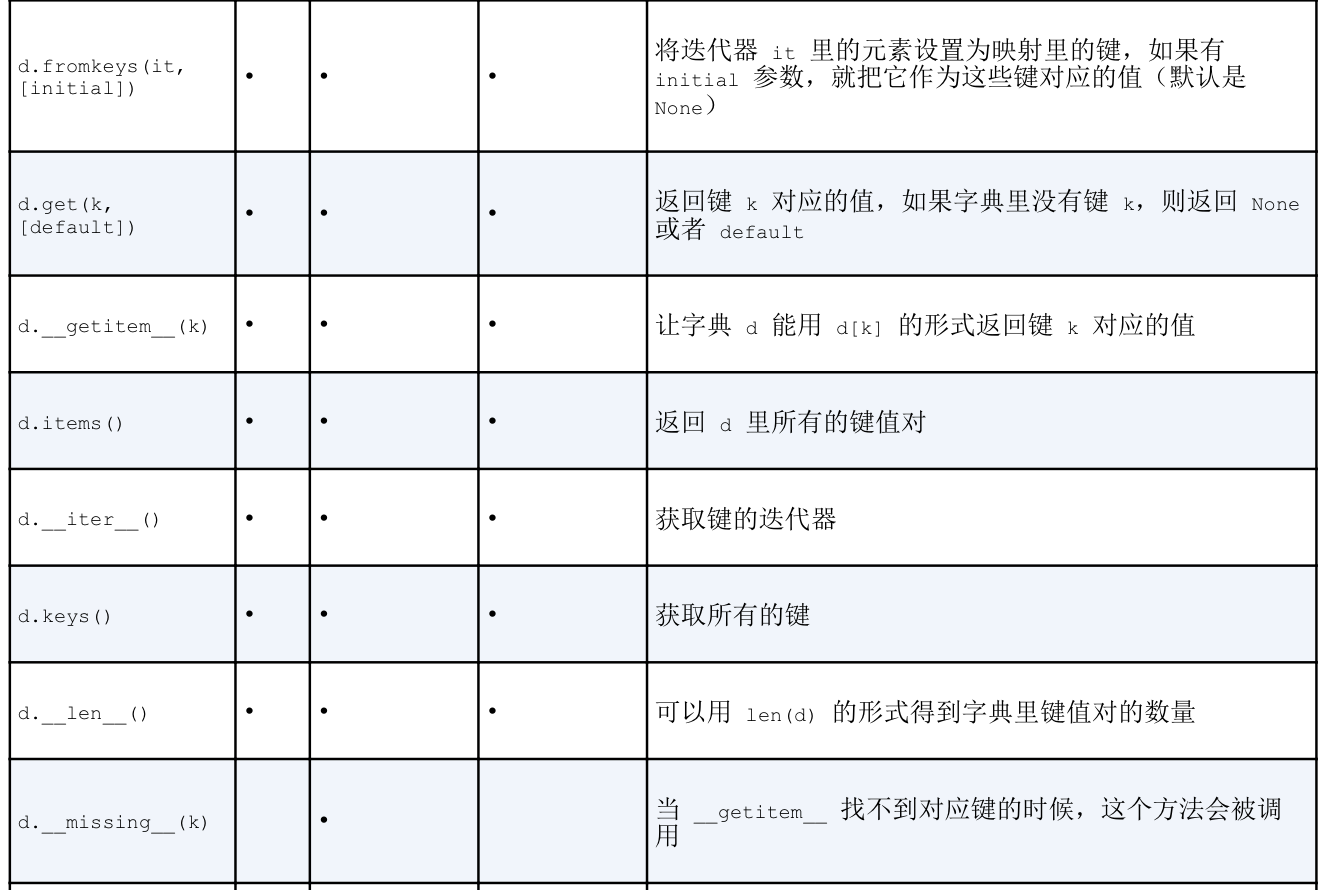

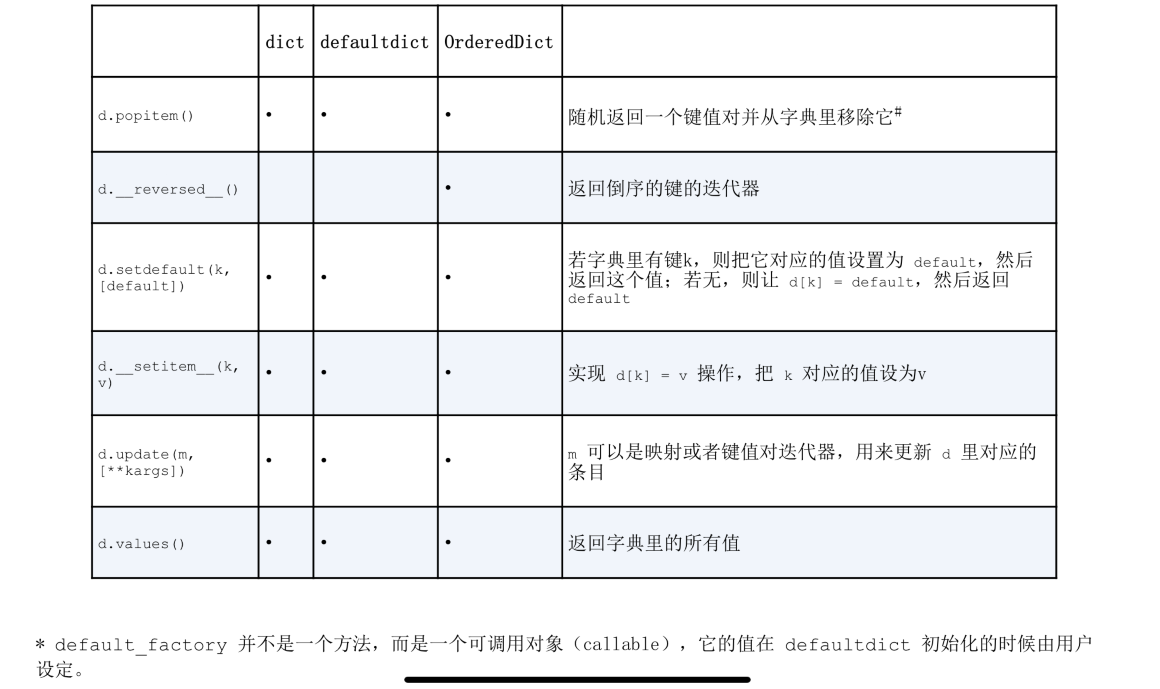
default_factory不是一个方法而是一个可调用对象, 他的值在defaultdict初始化中由用户设置
OrderedDict.popitem()会移除最先插入的元素**(先进先出), 如果.popitem(last=True)则会移除最后插入的元素(后进先出)**
d.update(m, [**kargs]), 在处理m时, 函数首先检验m是否有keys方法,
- 有–>
update会把它当作映射对象处理 - 无–>
update会把它当作含有(key-vaule)键值对元素的迭代器 python大多数映射类型的构建都采用了相似的逻辑
可调用对象
将类当作函数调用instance()
- 类中实现
__call__ - 快速调用带有某一实例化属性的类的函数
1 | class eval_some: |
3.3.1 更新字典kV
用setdefault处理找不到的键
d[k] --> getitem找不到键时, 会有异常抛出KeyError
- 符合python的快速失败哲学
- 可以使用
d.get(k, default)代替异常 - 当在更新某个键对应的值的时候, 以上俩个方式效率都很低
如果要更新字典的一个键值对(包括不存在)使用setdefault(key, default) [operate]这样只会query 1,如果使用if else []则会查询2~3次
1 | a = {"name": "Drink"} |
3.4 映射的弹性键查询
在映射中查找不存的key时, 我们希望可以返回一个default value而不是error, 以下俩途径可以实现弹性键查询
- 通过
defaultdict这个类而不是普通的dict - 自己定义一个
dict子类, 并在在子类中实现__missing__方法
3.4.1 defaultdict处理不存在的key
defaultdict是collections中的一个类, 在实例化它时,可以接受一个defaultfoctory不接受参数(一定是可调用的且不接受参数的方法类|函数)
在调用
d[key]中如果__getitem__找不到对应的key会调用__missing__查看是否定义了defaultfactory将
defaultfactory返回的值赋值给d[key]更新
dict
1 | from collections import defaultdict |
如果
defaultfactory=None在没有找到对应的key时会抛出KeyErrordefaultfactory只会在__getitem__中调用, 比如dict[key]才会被调用, 其中连接两者桥梁的时__missing__
3.4.2 特殊方法missing
所有的映射类型在找不到key的时候都会牵扯到missing, python基类虽然直到这个方法,但并没有定义这个方法, 不过, 如果一个class继承了dict并且这个类提供了missing方法,那么在
getitem找不到值的时候不会抛出异常
特点:
missing方法只会被getitem调用- 不会对
.get()__contains__方法产生影响
dict[key] -- __getitem__ -- __missing__
dict.get() -- get -- try except
如果要自定义一个映射类型, 更合适的策略是继承collections.UserDict
1 | # define the new mapping class by user based on dict |
像
k in dict.keys()操作在python3中是十分快速的, 即使映射类型对象很庞大, 因为:
dict.keys()返回的值是一个视图, 就像集合, 在里面查找一个元素是十分快的key in dict扫描的是一个list, 处理大数据效率低dict.keys()
3.5 字典的变种
都是基于collections库
除了bultin中定义的dict外, 其余字典的变种都是
collections库中的
UserDict
比较特殊的一种dict, 这个类其实是把builtin中的dict用纯Pyhton又实现了一遍
一般用于用户自定义子类的继承
OrderedDict
这个类型会在添加键的时候保持顺序, 因此键的每次迭代次序总是一致的
OrderedDict的popitem方法默认删除并返回的时字典里的最后一个元素(先进后出), 如果popitem(last=False)则会删除并返回第一个元素(先进先出)
ChainMap
该类型可以容纳数个不同的映射对象,然后在进行键查找操作时, 这些对象会被当作一个整体逐个进行查找,直到键被找到
在给有嵌套功能作用域的语言做解释器的时候很有用, 可以用一个映射对象来代表一个作用域的上下文
ChainMap可以将多个字典合并为一个独有的字典,这样的操作 并不是对源数据的拷贝,而是指向源数据,假如原字典数据修改,ChainMap映射也会改变;如果对ChainMap的结果修改,那么原数据一样也会被修改
使用update进行合并字典,是对源数据的拷贝
ChainMap可接受多个映射然后在逻辑上使它们表现为一个单独的映射结构;它只是维护了一个记录底层映射关系的列表,然后去重定义常用的字典操作如果有重复的键,会采用第一个映射中键对应的值
修改
ChainMap映射结构,会同时作用在自己和原始字典结构上可以使用字典的
update()方法,来替代上面的合并方案;但是这就需要创建一个新的字典对象(或者修改原字典,破坏了原始数据),并且原始字典做了修改,并不会反映到新建的字典上ChainMap使用的就是原始字典,因此原字典变,它也会改变。如果在使用 ChainMap 合并多个字典时,字典中有重复的 key 值,默认取第一个字典中 key 对应的 value ,从原理上面讲,ChainMap 实际上是把放入的字典存储在一个队列中,当进行字典的增加删除等操作只会在第一个字典上进行,当进行查找的时候会依次查找
(以查找的第一个key-value返回)
1 | m1 = {"name": "Drink", "age": 23} |
Counter
这个类型会给键准备一个整数计数器, 每次更新一个键的时候都会增加这个计数器.因此这个类型可以用来给可散列对象计数(str bytes frozenset 数值型)或者当成多重集来用–>多重集合就是集合里的元素可以出现不止一次, Counter实现了+ - 运算符来和并记录
还有像most_common(num)这类方法, 会按照次序返回映射里最常见的num个键和他们的计数
1 | counter = collections.Counter("asdxzcsdfwerewrfewzsqawd") |
3.6 子类化UserDict
自定义mapping类型,以
UserDict为基类更加方便,因为UserDict是原生的方法, 而dict可能会走写捷径,导致我们不得不在子类中重写这些方法, 而UserDict则不会出现这个问题
需要注意的是, UserDict并不是Dict的子类,但在data属性是基于Dict的实例实现的, 这个属性实际上是UserDict最终存储数据的地方
UserDict的子类在实现__setitem__避免了不必要的递归- 可以让
__contains__的代码更加简洁
1 | import collections |
UserDict继承的是MutableMapping,所以StrKeyDict里剩下的映射类型方法都是从UserDict MutableMapping 和 Mapping这些超类中继承的
Mapping类虽然是一个抽象基类ABC,但它提供了许多实用方法
1.MutableMapping.update
- 可以直接使用
dict.update(obj) - 定义在
__init__中, 实列化时可以接受多个不同类型的参数构造dict - 本质上调用的是
__setitem__–>self[key]=value
2.Mapping.get
.get()–>def get()–>try except
3.7 不可变映射类型
接受一个mapping类型, 返还一个动态只读视图, 在原数据上更改可以反映到视图上,但不能对视图进行写操作, 只能读取
types.MappingProxyType
1 | from types import MappingProxyType |
3.8 集合论
集合从2.3以module出现, 到2.6才成为built-in type, 包括
setfrozenset集合的本质是许多唯一对象的聚集(去重)
拥有极快的查找速度 ==> 散列表
空集 –> set()
{} –> dict 本质上是一个空字典
集合内元素必须是can hash即可散列的
- str
- bytes
- 数值类型
- frozenset
集合的操作
| –> ∪
& –> ∩ –> set.intersection(set)
- –> 差集
3.8.1 集合字面量「仅set」
除了空集合
set()外, 集合的字面量如同{1} {1, 2}
字面量语句构造集合的方法比set([1, 2, "3"])更快, 后者python需要新建一个列表, 最后吧这个列表传入到构造方法中, 如果是{1, 2, "3"}的字面量构造, python会利用一个BUILD_SET的字节码创建集合
使用反汇编函数查看字节码:
1 | from dis import dis |
python对于frozenset没有特殊字面量句法, 只能采用构造的方式
3.8.2 集合推导
同列表推导字典推导一样
- 创建一个新的序列
- 起到过滤条件的作用
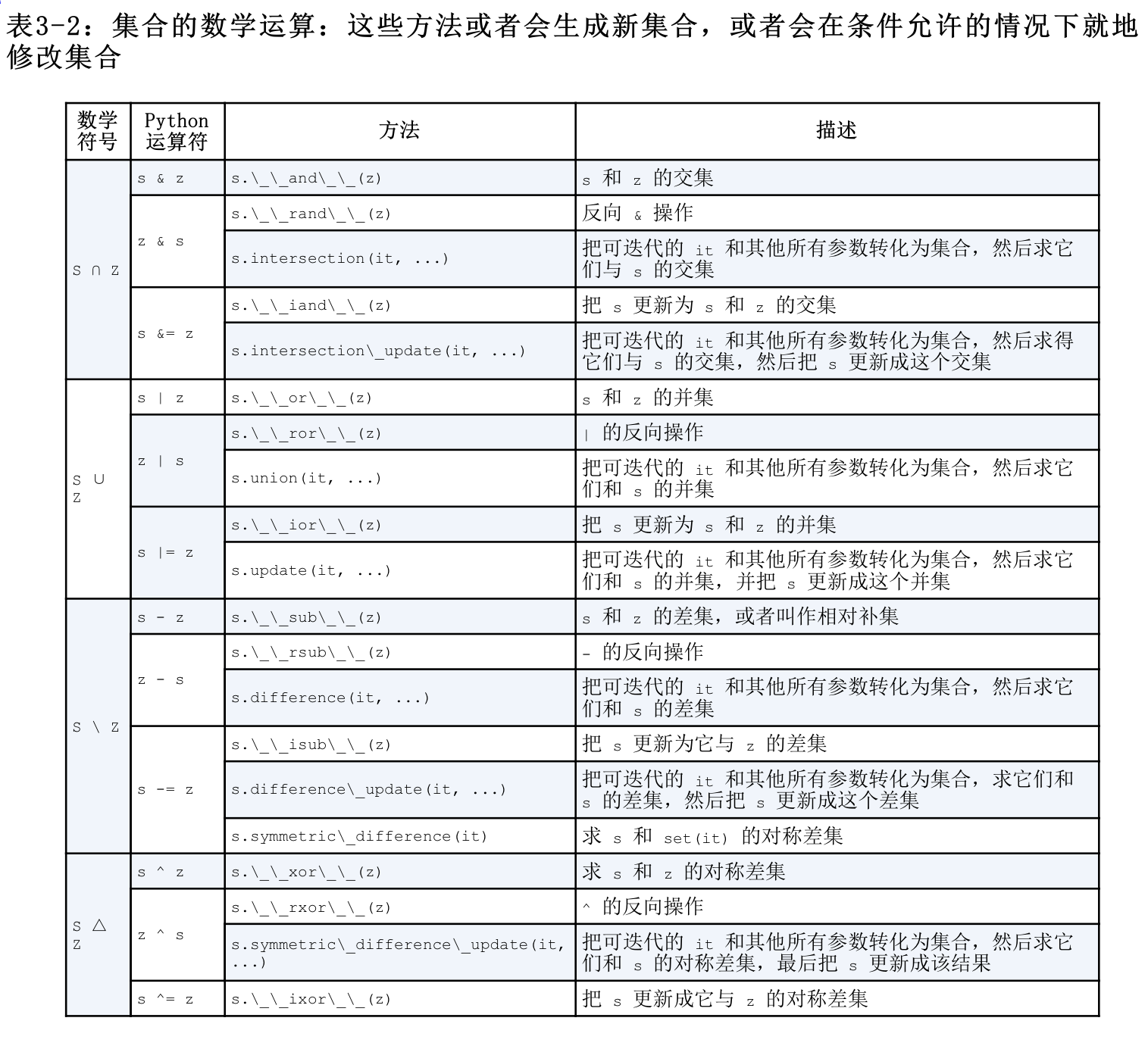
3.8.3 集合的操作
1 | a = {1, 2, 3} |
下表中, 缀运算符需要两侧的对象都是集合类型, 但是其他的方法则只要求所传入的参数是可迭代对象
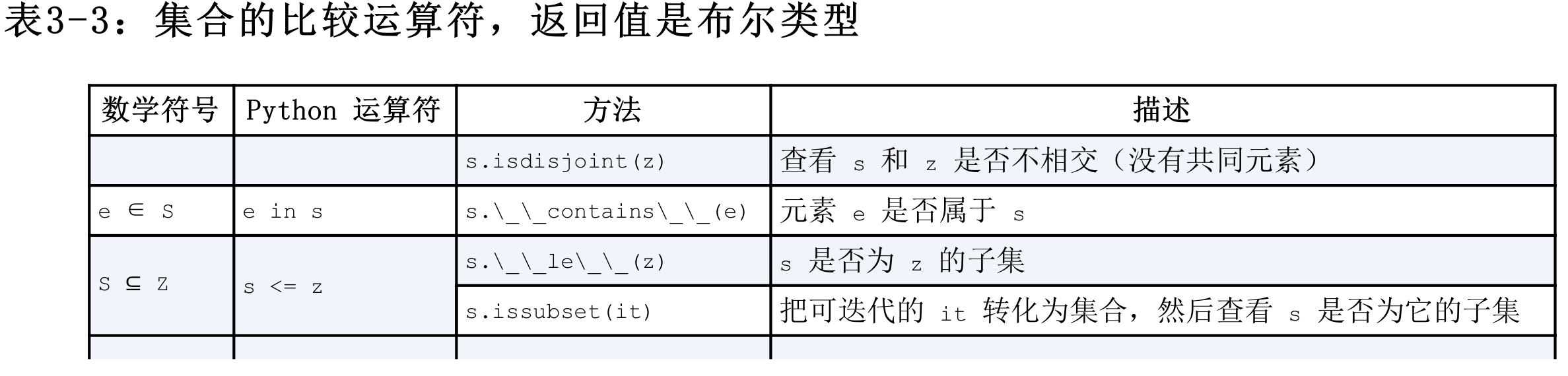
集合的比较运算符, 返回布尔值

集合的其他操作方法
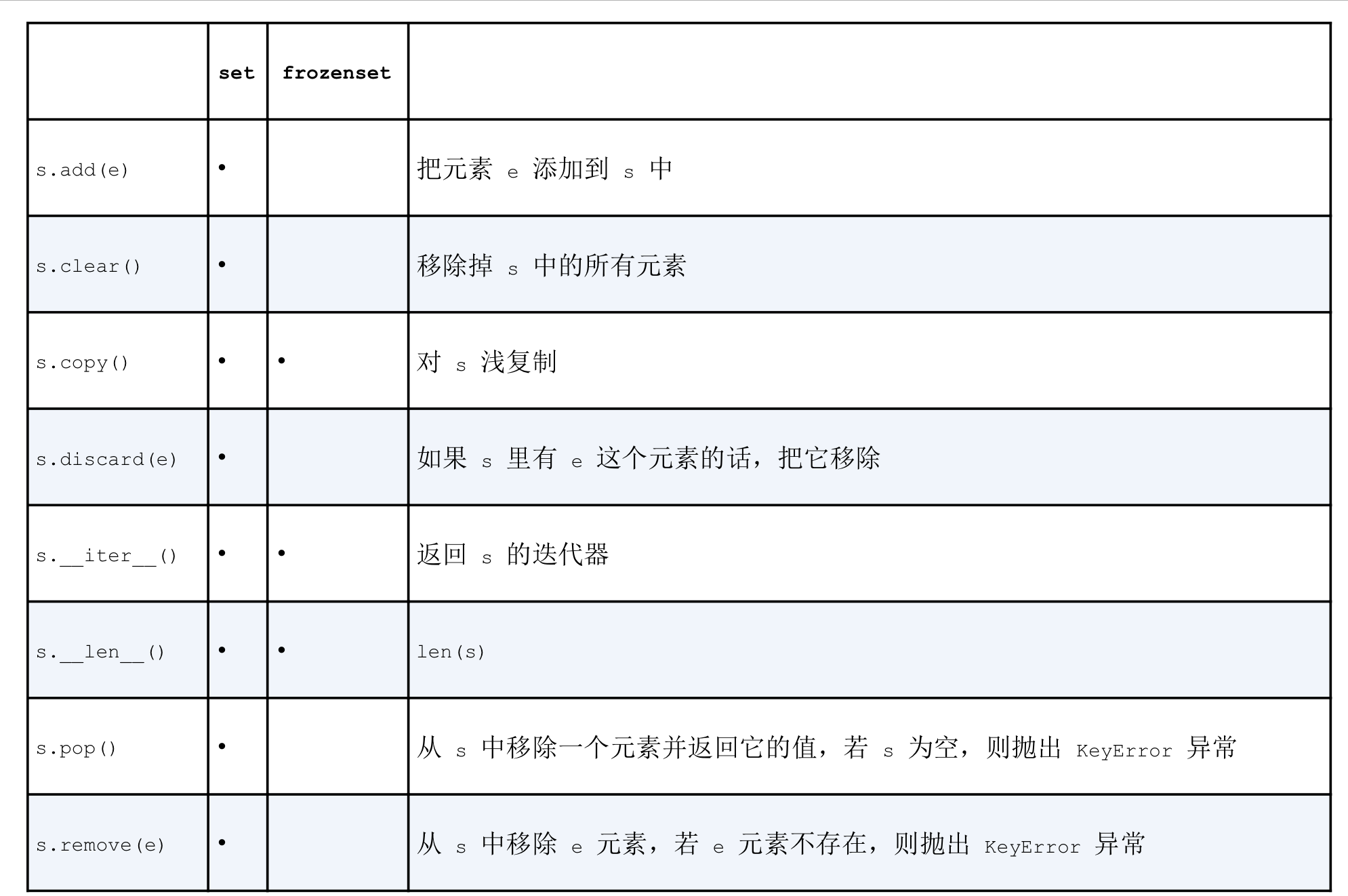
3.9 dict和set的原理
principles of dict and set, 了解python里的字典和集合类型,他们背后所涉及的hash table是必不可少的这节将会回答以下几个问题
python中的dict和set效率有多高?- 为什么他是无序且不稳定的?
- 为什么并不是所有的
python对象都可以当作dict的key或set里的number? - 为什么
dict的key和set的number的顺序是根据它们被添加的次序而定的,以及为什么在映射对象的生命周期中,这个顺序并不是一成不变的? - 为什么不应该迭代循环
dict或set的同时往里面添加元素?
1 | temp_list = [1, 2, 3, 4] |
3.9.1 效率实验
使用in set(&) 操作符,分别在set dict list查询是否含有某个元素
其中结果如下:
最快的是&
最慢的是list in
由于列表背后没有散列表来支持in运算符, 每次搜索都会扫描一次完成的列表 [说明了, dict和set在使用散列表存储的时候使用了类似排序的功能]
3.9.2 dict中的散列表
这一节只是笼统的描述python如何使用hashtable来实现dict, 其中Cpython对dict有过优化
散列表
本质上是一个稀疏数组(总是有空白元素的数组称为稀疏数组)
散列表中的单元叫做表元(bucket)
在dict的散列表中, 每个键值对占用一个表元,一个表元有俩部分, 分别是对值的引用和对键的引用
表元大小一致, 可以通过偏移量读取特定的表元
python会保证散列表中大约三分之一的表元是空的,如果达到阈值, 原有的散列表会被复制到一个更大的空间中
把对象放入散列表, 首先使用
hash()计算这个元素键的散列值
有关散列表的概念:
1.散列值和相等性
hash()==
hash()可以用于任何内置类型对象, 自定义对象调用自定义实现的__hash__- 如果俩对象在比较时是相等的, 则它们的散列值一定相等(但对象的类型和存储结构不一定相等)
- 为了让散列值可以当作散列表的索引, 越是相似但不相等的对象,他们散列值的差别就越大
从python3.3开始 str bytes datetime对象的散列值计算过程中多了随机加盐 所加盐值是python进程内的一个常量每次启动python解释器都会生成一个不同的盐值,目的是为了防止DOS攻击而采取的安全措施
2.散列表算法
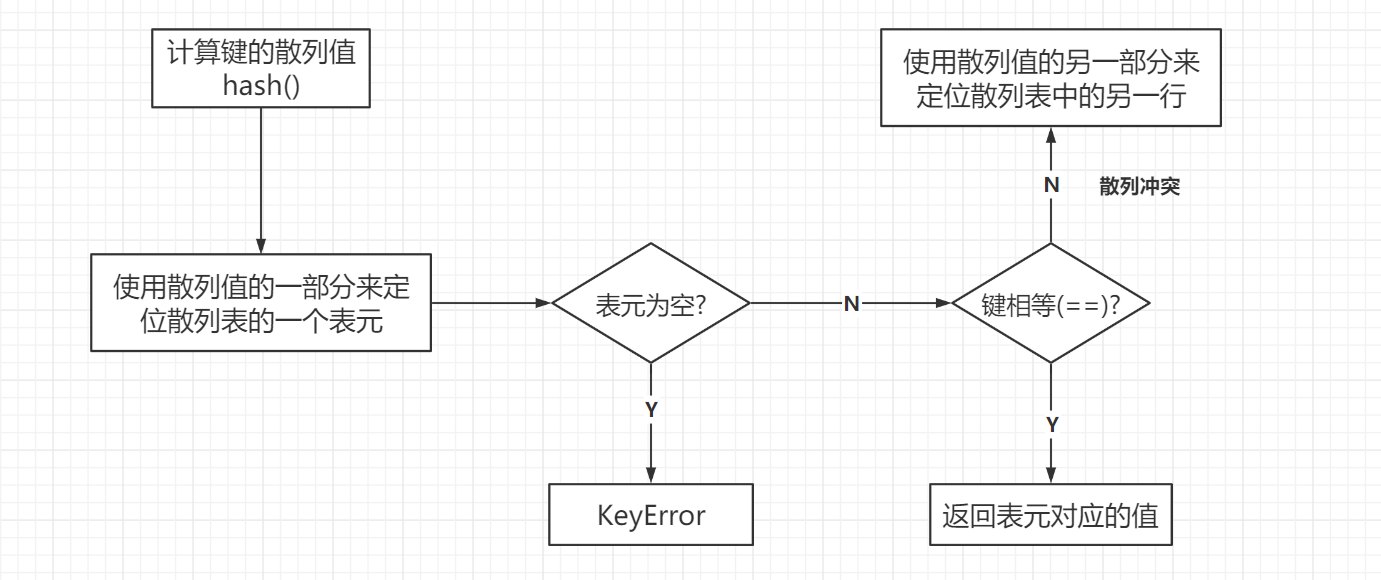
以dict[key]为例:
- python首先会调用
hash(key)计算key的散列值 - 把计算的散列值最低的几位数字当作偏移量, 在散列表中查找表元
bucket- 具体取几位要看散列表的大小
- 若对应的表元为空 –>
KeyError - 若非空 –> 表元里会有
key-value-pairs
- python会校验
key-value-pairs中的key与输入的key是否相等==- 相等 –> 返回对应的
value - 不等 –> 散列冲突
- 相等 –> 返回对应的
- 散列冲突: 因为散列表所做的是把随机的元素映射到只有几位的数字上,而散列表本身的索引又依赖于这个数字的一部分
- 为了解决冲突,算法会在散列值中另外再取几位数字用特殊方法处理后把新的数字当作索引寻找表元,并重复之前的操作
添加新元素:
发现表元为空时会放入一个新元素
更新元素:
找到表元后会更新元素
需要注意的是,python会按照散列表的拥挤程度来决定是否要重新分配内存为它扩容,如果增加散列表的大小,那散列值所占的位数和用作索引的位数会增加,减少了散列冲突
**注意:**Cpython中规定如果有一个整型对象,而且他能存进入一个机器字中,那么他的散列值就是它本身
3.9.3 dict的实现和限制
主要讨论hashtable给dict带来的优势和限制
1.键必须是可散列的
包括: str bytes frozenset 数值类型
一个可散列的对象必须包括
- 支持
hash()函数并且通过__hash__所得到的散列值不变(在他的生命周期中) - 支持通过
__eq__方法检测相等性 - 若
a==b那么hash(a)==hash(b) - 所有由用户自定义的对象默认都是可散列的,因为他们的散列值都是
id()来获取的,而且他们不相等
**注意:**如果自定义的类实现了_eq_,并且希望他是可散列的, 那么必须定义一个恰当的_hash_保证a==b时hash(a)==hash(b)另一方面,如果一个含有自定义_eq_依赖的类处于可变状态, 那么就不要在这个类中实现_hash_,因为他的实例是不可散列的
2.字典在内存中开销大
- 字典使用散列表实现
- 散列表是稀疏的
- 在自定义类中
_slots_属性可以改变实例属性的存储方式, 由dict-->tuple optimization优化往往和可维护相对立maintain
3.键查询很快
- 空间换时间
hash table实现了无视数据量大小的快速访问(在数据能放入内存的前提下)
4.键的次序取决于添加次序
- 在添加新键时, 可能会由哈希冲突, 此时新键会被安排到另一个表元(bucket)中
- 但是和俩个值相同的键添加顺序有关
- 虽然逻辑和面向用户表现形式上如此,在判断俩上依旧是相等的
1 | a = {"name": "Drink", "age": 23} |
5.添加新键会改变已有键的顺序
尽量不要边遍历边添加新键
- 添加新键
- python解释器为字典扩容
- 新键散列表并把已有元素添加到新表中
- 这个过程可能会发生散列冲突,导致新散列表中键的次序变化
- 如果在迭代一个字典的所有键的过程中同时对字典进行修改,那么这个循环可能会跳过一些键甚至是字典中已有的键
因此:不要对字典同时进行迭代和修改,如果扫描并修改一个字典,最好分成俩步 :
[迭代–得出要添加的内容–并把内容放到新字典]
[对原有字典进行更新]
不过在python3中对此进行了优化,.keys() .items() .values()方法返回的都是字典视图, 换句话说这些方法返回的更像set而不是list,此外视图还可以动态的反馈字典的变化
3.9.4 set的实现和限制
set 和 frozenset的实现也依赖于散列表
- 在散列表中只存放元素的引用(类似只存放key的引用)
- 集合中的元素必须是可散列的
- 集合很消耗内存
- 可以很高效的判断元素是否在集合中
- 元素的次序取决于被添加到集合中的顺序
- 在集合里添加元素会改变集合里已有元素的次序
本章小结
dict是python的基石, 除了dict外builtin里还提供了特殊映射比如collections里的defaultdict OrderDict ChainMap Counter UserDict以及types里的MappingProxyTypes
映射类型的重要方法
1.setdefault
- 更新字典里存档的可变值(比如列表)
- 避免重复搜索键
2.update
- 让批量更新字典成为可能
3.missing
- 可以自定当找不到对应的
key时, 对象如何处理
collections.abc模块提供了Mapping和MutableMapping俩大抽象基类,利用它可以进行类型查询或者引用,此外还有Set和MutableSet俩大抽象基类
Part4.TextAndBytes
human use text and computer use bytes.
本章节主要讨论:
- 字符 码位 字节表述
-
bytesbytearray和memoryview等二进制序列的独特性 - 全部
unicode和陈旧字符集的编解码器 - 避免和处理编码错误
- 处理文本文件的最佳实践
- 默认编码的陷阱和标准
I/O问题 - 规范化
Unicode文本 进行安全比较 - 规范化 大小写折叠和暴力移除音调符号的实用函数
- 使用
locale模块和PyUCA库正确地排序Unicode文本 -
Unicode数据库中的字符元数据 - 能处理字符串和字节序列的双模式
API
4.1 字符问题
字符串:一个字符序列, 本质上是一个序列; 问题是什么是字符?
2015年字符的定义为Unicode字符(面向人)
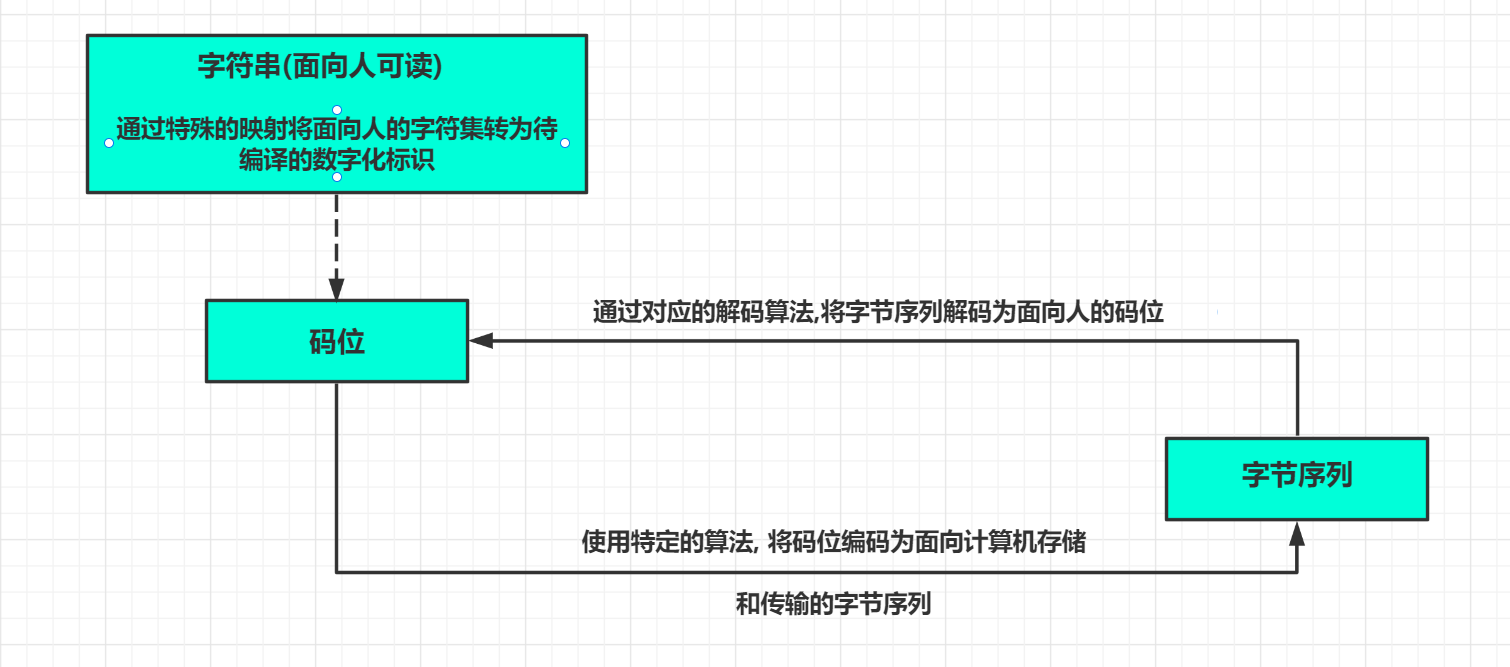
Unicode标准把字符的标识-和具体的字节表述进行了区分:
- 字符的标识即码位:是0
1114111的数字(10进制)在6个十六进制数字标识,并且加前缀unicode标准中以4U+ - 字符的具体表述取决于所用的编码:编码是在码位和字节序列之间转换时使用的算法
把码位转化成字节序列的过程时编码,反之是解码
简单的理解:
码位是数字映射后的准备编码的字符标识;
字节序列是通过一定编码规则(算法)编码后的用于计算机存储和传播的字节序列
1 | # init string |
python3的str类型基本相当于python2的unicode类型, 但是前者的bytes类型却不是把str类型换个名字那么简单
4.2 字节概要
python内置了两个基本的二进制序列类型其中有py3引入的不可变bytes类型和py2.6添加的可变bytesarray类型
bytes和bytearray对象的各个元素是介于0~255(含)之间的整数而不是py2的str对象那样的单个字符.
需要注意的是二进制序列的切片始终是同一类型的二进制序列
1 | # bytes对象可以从str对象加给定的编码方法构建 |
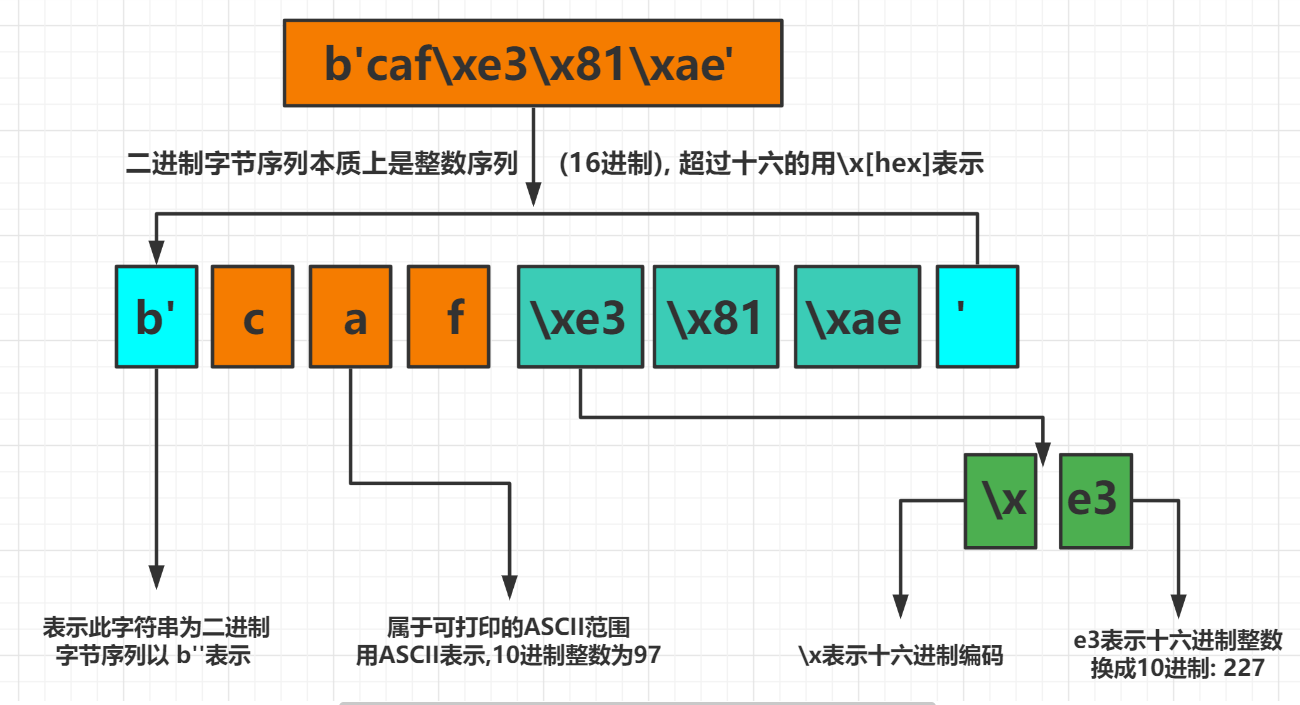
二进制序列本质上整数序列,但是他们的字面量表示含有ASCII文本,因此各个字节的值会有以下三种不同的方式显示 –> 例如
b'xxxxx\xx\xx\t'
- 可打印的ASCII范围内的字节(从空格到~)使用ASCII字符本身
- 制表符 换行符 回车符和\ 使用转义序列
\t\n\r\\ - 其他字节的值,使用十六进制转义序列(
\x00空字节)
1 | a = bytes.fromhex('31 4b ce a9') |
4.2.1 str方法
1.casefold
lower() 只对 ASCII 也就是 'A-Z'有效,但是其它一些语言里面存在小写的情况就没办法了。文档里面举得例子是德语中'ß'的小写是'ss':
1 | s = 'ß' |
汉语 & 英语环境下面,继续用 lower()没问题;要处理其它语言且存在大小写情况的时候再用casefold()
2.isdecimal
判断string是否是十进制, 返回bool空字符为False
3.isidentifier
Python 对各种变量、方法、函数等命名时使用的字符序列称为标识符
检查string是否是python标识符
标准为:
由 26 个英文字母大小写,0-9 ,_ 组成,不能以数字开头,且严格区分大小写
不能包含空格、@、% 以及 $ 等特殊字符,不能以系统保留关键字作为标识符一共有25 个
以下划线开头的标识符有特殊含义
对应keyword.iskeyword(str)检查是否是python保留的关键字
4.isnumeric
isnumeric() 方法检测字符串是否只由数字组成,数字可以是Unicode数字,全角数字(双字节) 罗马数字 汉字数字。指数类似 ² 与分数类似 ½ 也属于数字。返回bool
5.isprintable
判断是否是可打印字符,不可打印的有:
- 换行符制表符等
\t \n
6.translate
s.transelate(table)
table用str.maketrans(in-str, out-str)生成用于创建字符映射的转换表
转换表本质上整数映射
1 | print(transtable) |
以table作为基础替换s中所有命中的字符
1 | a = "i like something relaxing!" |
str类型的其他方法都支持bytes和bytearray类型
二进制序列并不是指字节序列全是二进制编码,而是指用于计算机存储和传播的二进制字节序列即字节序列,其本质上还是整数序列
- 在
ASCII中K表示十进制 1k表示十进制1
构建bytes或bytearray实例还可以调用各自的构造方法,传参如下:
- 一个
str对象(码位)和encoding关键字参数(编码规则) - 一个可迭代对象, 提供
0~255数值 - 一个实现缓冲协议的对象
(bytes bytearray memoryview array.array)此时把源对象中的字节序列复制到新建的二进制序列中
注意使用缓冲类对象构建二进制序列是一个底层操作,可能涉及类型转换
下面是将array.array转化成字节序列表示
1 | import array |
需要注意
使用缓冲类对象
(bytes bytearray array.array memoryview)创建bytesbytearray对象时, 始终复制的是源对象中的字节序列不过
memoryview对象允许在二进制数据结构之间共享内存从二进制序列提取结构化信息需要
struct模块
4.2.2 结构体和内存视图
struct模块提供了一些函数, 把打包的字节序列转换成不同类型字段组成的元组,还有一些函数用于执行反向转换,把元组转化成打包的字节序列.可以处理bytes bytearray memoryview对象
注意:
memoryview类不是用于创建或存储字节序列的, 而是共享内存,让你访问其他二进制序列 打包的数组和缓冲中的数据切片,而无需复制字节序列
memoryview 对象的切片是一个新 memoryview 对象,而且不会复制字节序列
1 | import struct |
如果经常处理二进制数据推荐阅读:
struct interpret bytes as packed binary data
4.3 基本的编解码器
python自带了超过100种编解码器(编码算法)用于在文本和字节之间相互转换
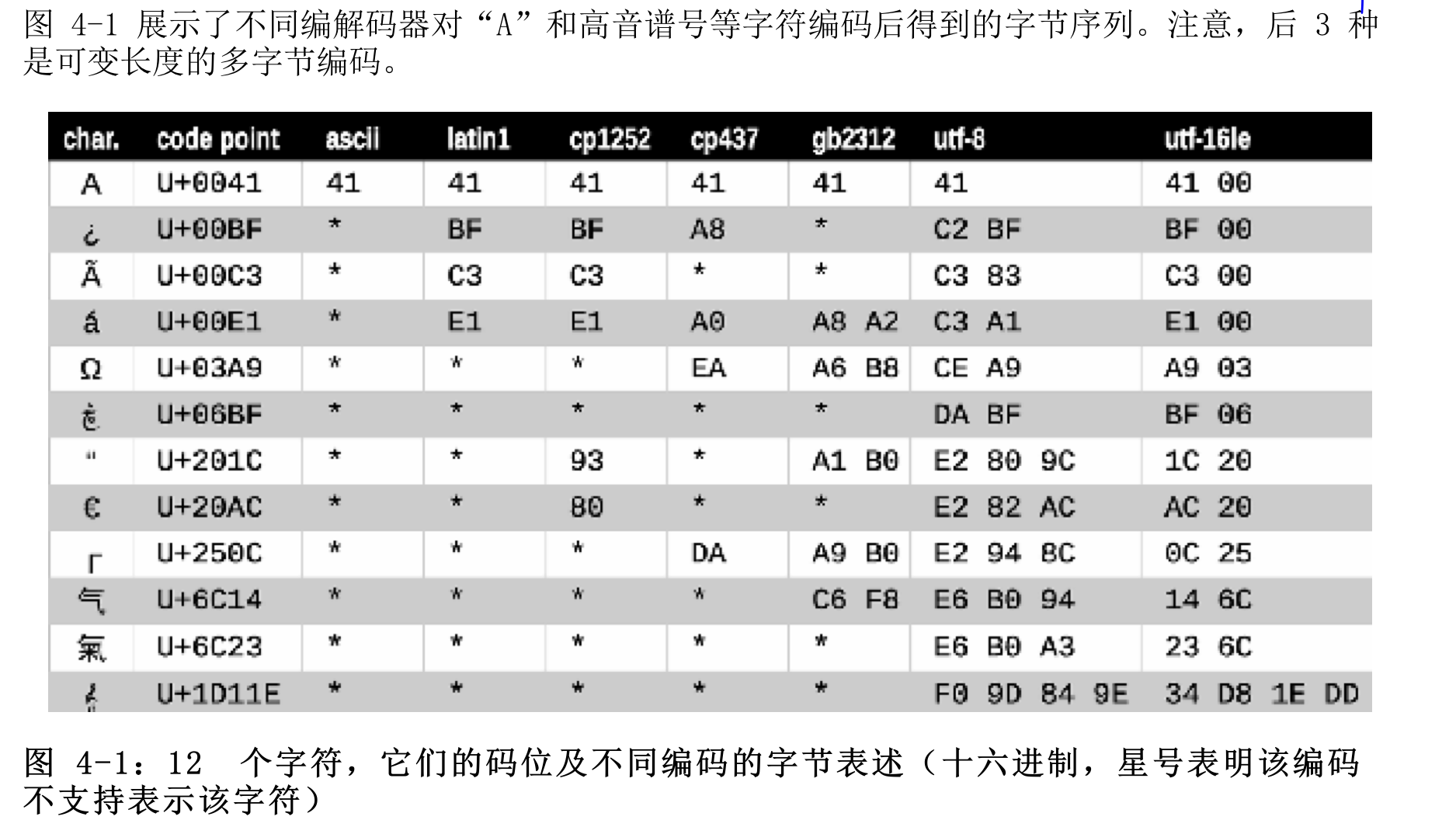
其中后三者是可变长度的多字节编码, 其余都是单字节编码
图中星号表示某些编码(ASCII和多字节编码GB2312)不能表示所有的Unicode字符, UTF编码的设计目的是处理每一个Unicode码位
4.4 编解码问题
编解码涉及到
unicode或者string或称码位与byte的编解码转换
编解码异常有三种:
1.UnicodeEncodeError
str转byte异常
2.UnicodeDecodeError
byte转str异常
3.SynatxError
如果在编解码中,源码的编码与预期不符, 在加载模块时会抛出语法异常
4.4.1 UnicodeEncodeError
4.4.2 UnicodeDecodeError
4.4.3 SyntaxError
多数非
UTF编解码器只能处理Unicode字符的一小部分子集, 把文本转化成字节序列时, 如果目标编码中没有定义某个字符就会抛该异常, 处理方式是把errors参数传给编码方法或函数,对错误进行特殊处理
不是每个字节都包含有效的ASCII字符,也不是每个字符序列都是有效
UTF-8或UTF-16因此,在把二进制序列转化成文本时, 如果假设是这俩个编码中的一个, 遇到无法转换的字节序列时会抛出UnicodeDecodeError
str.en|decode(encoding=””, errors=””)
errors接收四个参数
strict: 遇到无法编码的字符raise error
ignore: 忽略不能编码的字符
replace: 使用
?代替不能编码的字符xmlcharrefreplace: 把无法编码的字符替换成XML实体
需要注意的是errors接受的参数是可以扩展的, 你可以位errors参数注册额外的字符串方法codecs.register_error函数
- python3允许在源码中使用非ASCII标识符
1 | β = 1 |
4.4.4 找出字节序列编码
简单的说一般找不出字节序列的编码, 有些通讯协议和文件格式, 比如 HTTP和XML包含明确指明内容编码的首部. 可以肯定的是, 某些字节流不是ASCII, 因为其中包含大于127的字节值, 而且制定UTF-8和UTF-16的方式也限制了可用的字节序列.即使如此我们也无法根据特定的位模式来确定二进制文件的编码时ASCII或UTF-8
统一字符编码侦测包Chartdetect,可以识别30中编码
二进制序列编码通常不会指明自己的编码, 但是UTF格式可以在文本内容的开头添加一个字节序列标记
1 | import chardet |
4.4.5 BOM有用的鬼符
BOM (bytes-Order-Mark)字节序列标记, 指明编码时使用的是IntelGPU的小子节序
utf-16有俩种编码格式UTF-16LE小子节序UTF-6BE大字节序- 小子节序各个码位的最低有效字节在前面, 大字节序相反(Unicode码位)
- 因此在
utf-16编码中使用开头的BOMb'\xff\xfe'十进制(255 254)表示小子节编码 utf-8无论设备使用哪种字节序,生成的字节序列始终一致, 因此不需要BOM
4.5 处理文本文件
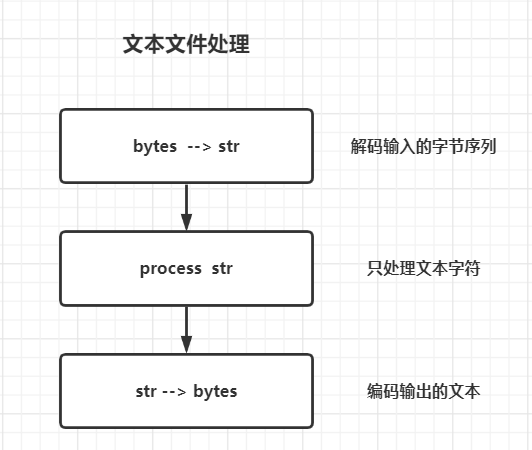
处理文本文件最好的方式是三明治处理法, 首先将输入的字节序列转码成字符串, 在对字符串进行处理, 最后把处理好的字符串编码成字节序列进行输出
Python3中的Open函数会在读取文本进行必要的解码, 在以文本模式写入文件时也会进行必要的编码, 所以my_file.read()方法得到的以及传递给my_file.write(text)方法的都是字符串对象
1 | # 使用utf-8编码打开(创建)txt文件, 模式位写 |
除非想要判断编码否则不要使用二进制模式打开文本文件, 即便想要查看编码类型也不要重复发明轮子, 可以使用chardet
通常不建议使用默认编码方式取处理二进制或文本流
编码默认值
1 | import locale |
1 | locale.getpreferredencoding() --> 'cp936' |
sys.getfilesystemencoding()用于编解码文件名而非文件内容, 把字符串参数作为文件名传给open()函数会使用它, 如果是字节序列则直接传给OS API
locale.getprefferedencoding()返回的编码即是打开文件的默认编码,同时也是重定向文件的sys.stdout/stdin/stderr
不要依赖默认编码尤其是windows用户
4.6 规范化Unicode字符
因为Unicode有组合字符(变音字符和附加到前一个字符上的记号, 打印时作为一个整体)所以字符串比较起来比较复杂
比如é这个词, 是e后加U+0301得来的, 在unicode中称为标准等价物, 但是python看到的是不同的码位序列, 因此判断两者不相等, 这时就需要一个统一的标准, 来规范化Unicode就像规范两种方言一样
使用unicodedata.normalize函数
第一个参数:
- NFC (Normalization Form C)
使用最少的码位构成等价的字符串
- NFD
把组合字符分解成 [基字符] 和 [单独的组合字符]
1 | s1 = "café" |
用户输入的文本默认是NFC格式, 在保存文本前, 最好使用normalization(“NFC”, text)清洗字符串
需要注意的是, 在使用NFC清洗字符串时, 有些单字符会被规范成另一个单字符, 比如电阻的单位Ω会被规范成欧米茄, 在视觉上是一样的, 但在比较时并不相等
NFKC
NFKD
这俩个规范化方法是兼容性规范化, 这些规范化更适合用在用户搜索或索引上, 需要注意的是, 经过NFKC或者NFKD兼容性规范化后的字符可能会丧失原本的意义, 尽量不要用于数据的持久化
1 | s3 = "¼" |
4.6.1 大小写折叠
即将所有的字符转化成小写, 相比于lower()只支持Unicode, casefold()支持更多的大小写转化, 尽管如此, 两者不同的字符仅有116个码位, 占比0.11%
4.6.2 规范化文本匹配实用函数
NFC和NFD可以很合理的比较Unicode字符串, 并且NFC是最好的规范化形式, 不区分大小写应该使用casefold()
1.去掉变音字符号
unicodedata.combining (unichr) 将分配给Unicode字符 unichr 的规范组合类 返回 为整数。 如果未定义组合类,则返回 0 。
1 | from unicodedata import normalize |
2.比较字符是否相等|忽略大小写
1 | from unicodedata import normalize |
4.7 Unicode文本排序
对于ASCII字符串来说比较的是码位, 但在非ASCII字符时会使用locale.strxfrm函数, 这个函数会把string转化成适合的区域进行比较
需要注意的是, 一般情况下, 变音符不会对排序造成影响, 如果有影响, 变音符号常常排在常规词后面
在使用locale.strxfrm函数作为排序key前, 要先调用setlocale(LC_COLLATE, your_locale)
需要注意:
- 区域设置是全局的, 不建议库中调用, 且应用或框架应该在进程中调用
- 操作系统必须支持区域设置
使用unicode排序算法排序
pyuca
Python Unicode Collator Algorithm
1 | import pyuca |
4.8 Unicode 数据库
本质上已经一个关于unicode以及个中映射关系的数据库, 就如码位与string bytes的映射一样, 同样基于此提供了许多双模式API对外调用, 出名的有unicodedata
regex库正在替代re库
双模式API是一个趋势: 即支持字符和字节参数,并根据参数的格式做出自适应的调整
4.9 支持str和bytes的双模式API
标准库中一些函数能接受字符串或字节序列作为参数, 然后根据类型自适应做不同的行为, 其中re和os为例
4.9.1 正则str和bytes
| unicode | bytes | 次数|注 | |
|---|---|---|---|
| * | {0,} | ||
| + | {1,} | ||
| ? | {0,1} | ||
| \d | 匹配任何一个十进制数字, 包括[0-9]和其他数字字符 | 只匹配[0-9] | 和re.ASCII |
| \w | 任何Unicode字符, 所有语言|数字|下横线 | [a-zA-A0-9] | 和re.ASCII一样 |
1 | import re |
4.9.2 os中的字符串和字节序列
GNU/linux内核不理解Unicode, 因此文件名中使用字节序列都是无效的
为了方便处理字符串或字节序列形式的文件名或路径名, os模块提供了特殊的编码和解码函数
fsencode(filename)
当filename是str时使用sys.getfilesystemencoding()编码成bytes
fsdecode(filename)
当filename是bytes时使用sys.getfilesystemencoding()解码成str
在unix及其衍生平台中使用
surrogateescape错误处理方式, 避免碰到意外字节卡住, windows使用strict, 这种处理方式在py3.1时被引进
这种错误的处理方式实际上是将无法编码的字节替换成Unicode中U+DC00到U+DCFF之间的码位(low surrogate area), 这些码位是保留的,没有分配字符, 只供程序内部使用
4.10 本章小结
1.一个字符不等于一个字节, 两者的对应关系取决于编码所用的算法
2.chardet包可以在没有元数据的情况下检测编码的大概方法
3.在str-bytes的编解码中, 避免使用系统默认编解码
4.文本比较由于编解码的不同, 在比较之前需要进行规范化和大小写折叠
5.双模式API的自适应调整是以后的趋势
杂谈
Q1:纯文本是什么?
A: 由特定标准的码位序列组成的没有任何字节表示除文本之外的信息的结构化或非结构化计算机编码文本
Unicode从广义上讲比较复杂, 因为要面对多种实际情况, 但在日常使用中不需要有这种担心
Q2:在RAM中表示字符串
A: 在内存中, 使用固定数量的字节序列存储字符串的各个码位, 在py3.3之前, 编译Cpython时可以配置在内存中使用16|32位, 存储各个码位
- 16: 窄构建 sys.maxunicode 65535
- 32: 宽构建
从py3.3后, 创建str对象时, 解释器会检查里面的字符并自适应选择最适合的内存布局
Part5 Fun is Obj
5.0 1st Fun
在python中函数被称为一等对象
- 在运行时创建
- 能赋值给变量或数据结构中的元素
- 能作为参数传给函数
- 能作为函数的返回结果
我们熟悉的int float string dict都属于一等对象
在python中所有函数都是一等对象
DocStrings 文档字符串是一个重要工具,用于解释文档程序,帮助你的程序文档更加简单易懂。
我们可以在函数体的第一行使用一对三个单引号 ‘’’ 或者一对三个双引号 “”” 来定义文档字符串。
你可以使用 doc(注意双下划线)调用函数中的文档字符串属性。
1 | def test(n): |
5.2 Higher Order Fun
接受函数为参数或者把函数作为结果返回的函数都是高阶函数(Higher-Order-Functions), 常见的有map sorted filter reduce apply(已经过时|使用不定量的参数调用函数, 已经使用解包代替)
为了使高阶函数具有更多的可读性, 一般会在高阶函数中使用匿名函数
reduce() 函数会对参数序列中元素进行累积。
函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
注意:Python3.x reduce() 已经被移到 functools 模块里,如果我们要使用,需要引入 functools 模块来调用 reduce() 函数:
- 此函数多用求和
- 现在已经出现
sum()内置函数代替此函数
1 | from functools import reduce |
5.3 匿名函数
lambda用于创建匿名函数
- 使用
lambda创建 - 多用作高阶函数的传参函数
lambda函数十分简单, 无法在定义体中赋值, 也不能使用whiletry等函数- 建议除了给高级函数作为传参函数外, 不要过度使用匿名函数
需要注意: lambda和def一样都会创建一个函数对象
1 | import functools |
5.4 可调用对象
除了用户自定义的函数, 调用运算符
()还可以用在其他对象上, 如果要判断一个函数是否可以调用, 可以使用callable()
python中的可调用对象可以分为以下几类:
- 自定义的
def或lambda - 内置函数:
Cpython实现的函数如lentime.strftime - 内置方法: 使用
C语言实现的, 比如dict.get - 类定义体中定义的函数
- 类: 调用类会运行类的
__new__创建一个实例, 之后运行__init__初始化实例, 最后把实例返回给调用方 - 类的实例: 在类中定义了
__call__ - 生成器函数:
yield的关键字函数或方法, 生成器函数往往返回生成器对象
注意的是: 生成器函数在很多方面与其他可调用对象不同, 生成器函数还可以作为协程来使用
5.5 定义的可调用类型
python其实模糊了类和函数的界限, 要实现内部call的magic method, 在实现这个magic mthod时需要在内部维护一个状态, 让它在调用之间可用, 通常使用俩种方法 –> 闭包 | 装饰器
1 | # Callable Obj |
5.6 函数内省
内省: 即通过函数名, 可以得到函数的更多信息, 通常需要借助
fun_name.__doc__dir(fun_name)
5.7 定位参数|关键词参数
1 | def tag(name, *content, cls=None, **attrs): |
name: 定位参数, 当没有key时按照位置赋值
*content: 接受除定位参数后的所有参数, 一般是一个可迭代对象, 并将这些参数解包成元组
cls=None: 关键词参数, 一般需要设置一个default_value
**attrs: 关键词参数, 可以接受多个关键词, 通常使用字典封装
定位参数
arg*argscommon –> tuple(iterator)
关键词参数
key=value**dictcommon –> dict(Obj)
py3接受了一个特性, 只接受关键词参数|即只接受特定的key
1 | def f(a, *, b): |
5.8 获取参数的信息
获取函数对象的参数信息
__code__可以获取参数的名字以及其他属性, 它本身返一个对象, 也有其他属性,__defaults__返回一个元组, 里面存储的是函数定位参数的缺省值,__kwdefaults__返回一个字典, 里面存储的关键词参数的缺省值
python中的代码对象是实现代码自省的重要概念, 代码对象通过
fun.__code__访问
1 | def temp(x=1, y=2, *, z=3): |
代码对象
代码对象 code object 是一段可执行的 Python 代码在 CPython 中的内部表示。
可执行的 Python 代码包括:
- 函数
- 模块
- 类
- 生成器表达式
当你运行一段代码时,它被解析并编译成代码对象,随后被 CPython 虚拟机执行。
代码对象包含一系列直接操作虚拟机内部状态的指令。
这跟你在用 C 语言编程时是类似的,你写出人类可读的文本,然后用编译器转换成二进制形式,二进制代码C 的机器码或者是 Python 的字节码被 CPU对于 C 语言来说或者 CPython 虚拟机虚拟的 CPU 直接执行。
代码对象除了包含 指令,还提供了虚拟机运行代码所需要的一些 额外信息。
在Python 2中,函数的代码对象通过 函数.func_code 来访问;而 Python 3 中,则需要通过 函数.__code__ 来访问。
Python 3 的代码对象增加了一个新属性 co_kwonlyargcount,对应强制关键字参数 keyword-only argument。
1 | def clip(text, max_len=80): |
即使我们通过函数对象__code__实现了函数自省, 但是其数据和效率并不高, 而且所获取到的信息可读性比较差
inspect模块
为了解决通过函数对象实现函数自省的效率和可读性问题, 我们可以通过
inspect模块
1 | from inspect import signature |
inspect.signature函数返回一个inspect.Signature对象, 这个对象有个很重要的属性是parameters, 是一个有序映射, 可以把参数名和inspect.Parameters对应起来.
Signature.Parameters
1 | # 查看inspect.signature.parameters的数据 |
各个Parameters也有自己独立的属性(封装在inspect.signature.parameters的有序映射里的对象体)
OrderedDict([('text', <Parameter "text">)]每个<Parameter>
kind : 函数对象的变量种类
name: 函数对象的变量名字
default: 函数对象的默认值
annotation: 注解属性|提供函数签名元数据
Signature.bind
inspect.Signature对象有一个bind方法, 可以将任意参数绑定到签名中的形参上, 所用的规则与实参到形参的匹配方式一样, 可以使用此方法进行调用函数前的验参(验证是否少参|多参)
1.inspect.Signature获取函数签名
2.讲特定函数签名通过Signnature.bind(**params)绑定进行验参
3.终端输出是否存在少参多参的情况
1 | def check_sign(name, age, sex, *, book="Drink", title): |
5.9 函数注解
函数注解是python3的一种语法, 用于声明函数中的参数和返回值附加的元数据, 注解并不会对代码逻辑做任何处理, 只是将其作为[可视化]的元数据存储在函数对象的
__annotations__属性里(表现形式是字典)
注解如下:
1 | # 无注解形式 |
- 注解加在
par:后, 一般声明参数类型 - 如果有默认值, 注解放在
par:和=之间 - python对注解所作的唯一件事是将其放在fun obj的
__annotation__属性里 - 注解对python解释器没有任何意义, 注解只是元数据,供
IDE框架和装饰器使用
1 | def test_ann(name: str, age: int, book: str = 'StarFire') -> str: |
1 | sign = signature(test_ann) |
1.signature函数返回一个Signature对象, 这个对象拥有return_annotation属性和parameters属性
2.return_annotation返回函数对象注解
3.parameters属性返回一个字典, 其中字典的key是参数, value是Parameter对象
4.每个Parameter对象有独属于自己的属性
5.10 函数式编程
Python的不目标并不是称为函数式编程语言, 但是
operator和functools等包的支持让其函数式风格十分快捷
Operator
其中绝大多数方法, 用于<算术运算>和<代替匿名函数从序列中取出元素或读取对象>, 即大多数其方法式实列化的匿名函数
其用法就如该目录一样即提供函数式编程|换句话说是所返回的实例本质上式函数|创建函数
1.算数运算
1 | from operator import mul |
2.itemgetter取值
1 | from operator import itemgetter |
3.attrgetter取值
1 | from operator import attrgetter |
1 | name id score age |
4.methodcaller
methodcaller(fun_name, fun_args)
fun_name: str
fun_args: *args **args
本质上式访问的参数的类属性(get atteration)
1 | # methodcaller |
5.10.2 使用functools.partial冻结参数
又称为偏函数, 即根据一个函数通过
functools创建一个可调用对象, 其中实现了原函数的功能, 但是只接受其参数的子集, 否则抛出exception
functools提供了一系列的高阶函数, 其中使用频率最多的是reduce和partial以及其变体partialmethod
使用partial冻结参数类似于将函数的部分参数设置了一个可变的缺省值
基于一个函数创建一个新的可调用对象, 并把原函数的某些参数固定, 使这个函数可以接受一个或者多个参数的函数改编成需要回调的API
1 | from operator import mul |
partial的第一个参数接受一个可调用对象, 后面需要跟任意一个要绑定的定位参数和关键字参数
functools提供的高阶函数除了reduce partial partialmethod之外, 还有可用于缓存的lru_cache以及装饰器singledispatch和wraps以及构造选择的函数itemgetter attrgetter
5.11 本章小结
函数的一等性
- 可赋值给变量
- 传给其他函数
- 存储在数据结构中
- 方位函数的属性
- 供框架和一些工具使用
规约函数
函数调用规约,是指当一个函数被调用时,函数的参数会被传递给被调用的函数和返回值会被返回给调用函数。
偏函数
即根据一个函数通过functools创建一个可调用对象, 其中实现了原函数的功能, 但是只接受其参数的子集, 否则抛出exception
可调用对象
0.函数即是对象, 对象也是函数
1.lambda实现的方法
2.自定义或实现__call__的函数或对象
Part6 Imp DP Use 1 FunObj
6.0 抽象基类
定义一个接口或抽象类,并且通过执行类型检查来确保子类实现了某些特定的方法
运用 abc模块实现抽象基类
抽象方法: 表示基类的一个方法,没有实现,所以基类不能实例化,子类实现了该抽象方法才能被实例化。
1 | from abc import abstractmethod, ABCMeta |
- 抽象类的一个特点是它不能直接被实例化
- 抽象类的目的就是让别的类继承它并实现特定的抽象方法
Implement design patterns using first-class functions
上下文
把一些计算委托给实现了不同算法的可互换组件, 提供服务
策略
实现不同算法的组件共同的接口
具体策略
策略的子类, 用于实现不同的算法
1 | from abc import ABC, abstractmethod |
需要注意的是: 我们把Promotion定义为抽象基类(ABCMeta), 这么做是使用@abstractmethod装饰器除此之外还可以使用class Promotion(metaclass=ABCMeta)实现
1 | joe = Customer("john doe", 0) |
可以完全使用一等对象函数来实现这种策略, 并且代码更少
6.1 函数实现策略模式
在上面的例子中, 每一个实例化的抽象类
Promotion都只实现了一个方法, 我们对此重构如下
使用作为一等对象的函数, 可以使某些设计模式进行简化
什么是策略模式: 定义一系列算法, 把他一一封装起来, 并且可以使他们相互替换(使算法可以独立于使用它的客户而变化)
策略模式对类的编排
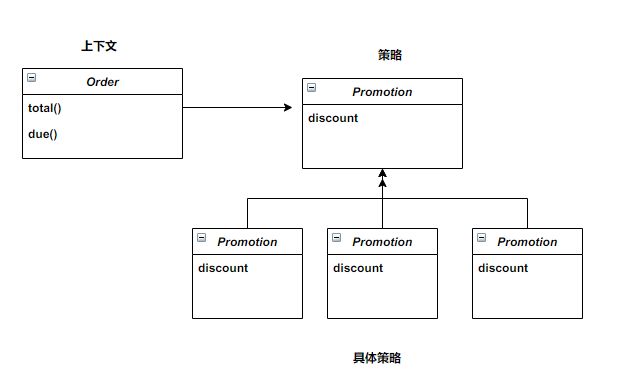
策略模式示例:
电商策略模式:
- 1000积分的顾客, 每单5%折扣
- 同一个订单, 单个商品数量达到20个, 10%折扣
- 订单中不同商品达到10, 7%折扣
假设每个订单只享受一个折扣
使用order类和函数实现的折扣策略
把具体的策略换成简单的函数, 去除抽象类
1 | from collections import namedtuple |
- 计算折扣只需要调用
self.promotion() - 再次表明了函数是一等对象:可以作为参数传递
- 取消了抽象类
- 各个策略都是函数
- 为了把策略用到实例上, 只需要传入对应的策略函数即可
策略对象通常是很好的享元(flyweight)
- 享元是可以共享的对象, 可以同时在多个上下文中使用
- 享元不需要在每个上下文实例化, 减少消耗
显然易见, 即使是使用了函数作为策略实现, 但是在选择策略时,任然时人工选择, 接下来我们考虑实现 元策略, 即让它自动化实现最优方案
1 | # 实例化函数:并非将其输入为string, 而是创建一个list包含了实例化的函数对象, 方便调用 |
promos列出函数实现的各个策略- 于其他
*_promo函数一样,meta_promo函数的参数是一个order的实例 - 使用生成器表达式, 将
order作为参数传给fun list
这里的promos是一个存储函数对象的列表, 当你深刻意识到了函数的一等对象性, 你就不难发现, 这样构建函数列表的simple and right
1.作为参数传递
2.可以被数据结构化存储
如下例所示:
1 | def temp(): |
6.1.1 find all strategy in module
在python中, 模块也属于一等对象, 并且标准库提供了许多处理模块的函数
Globals()
返回一个字典, 表示当前的全局符号表, 这个符号表始终针对当前模块(对函数或方法来说是定义他们的模块而不是调用他们的模块)
动态收集促销品折扣函数更简单的一个方式是使用简单的装饰器
6.2 命令模式
命令模式也可以通过把函数作为参数而传递
主要解决的是解耦调用者和接收者, 通过中间对象
command对象实现|如果要实现保存函数状态, 可以使用函数闭包
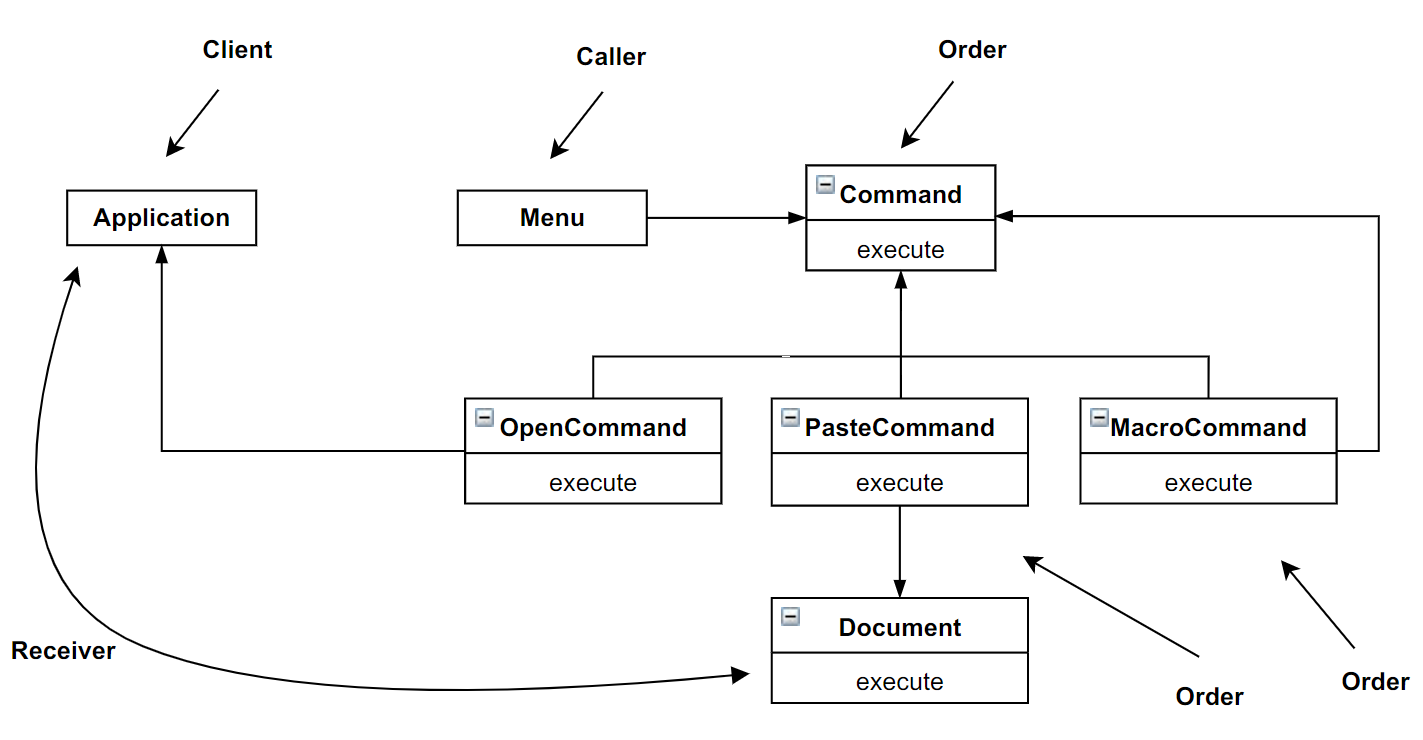
1 | class Macrocommand: |
6.3 本章小结
Recommand Books
- Learning python design patterns
Part7 Decorators And Closuer
装饰器用于在源码中标记函数, 用于增强函数行为, 装饰器的基础时闭包(回调式异步编程和函数式编程的基础)
7.0 Target
- 如何计算装饰器句法
- 如何判断变量不是局部的
- 闭包存在的原因和工作原理
- nonlocal解决的问题
- 行为良好的装饰器如何实现
- 标准库中常见的装饰器
- 实现参数化装饰器
7.1 DecoratorBasic
装饰器是一个可调用对象, 其参数是一个被装饰的函数, 其结果可能会处理被装饰的函数并将其返回, 或者将其替换成一个函数或可调用对象
在运行时改变程序的行为
装饰器
- 接受: 函数
- 返回: 处理后的函数|替换的函数 |可调用对象
特性:
- 能把被装饰的函数换成其他函数
- 装饰器在加载模块时立即执行
- 在被装饰函数定义之后立即运行
1 | def deco(func): |
7.2 Py何时执行装饰器
在被装饰函数定义后立即执行, 通常是在导包时(加载模块)中执行
- 在
import或running code时装饰器会首先运行, 被装饰的函数只有在调用时才运行 - 通常情况下, 装饰器独自写成一个模块, 被其他模块通过
import调用 - 大多数情况下装饰器会在内部定义一个函数
7.3 装饰器改进策略模式
使用装饰器改进策略模式
1 | promos = [] |
- 策略函数不需要一个特别名称
- 装饰器突出了被装饰的函数的作用, 可以临时禁用或者注释, 只需要注释掉装饰器即可
- 可以在其他模块中定义促销函数, 只需要添加装装饰器
转装饰器如果使用内部函数, 必须依赖于闭包实现
7.4 变量作用域规则
variable scoping rule
1.python在定义函数中, 默认函数中的变量都是local, 如果在执行中没有在local中找到对应的变量, 或者变量没有绑定值, python将会通过code crash的方式告诉用户, 而非像JavaScript一样找global代替
- 在函数体中没有进行赋值操作
1 | def test(a): |
- 在函数体中进行了赋值操作
1 | def test(a): |
两个函数的字节码如下
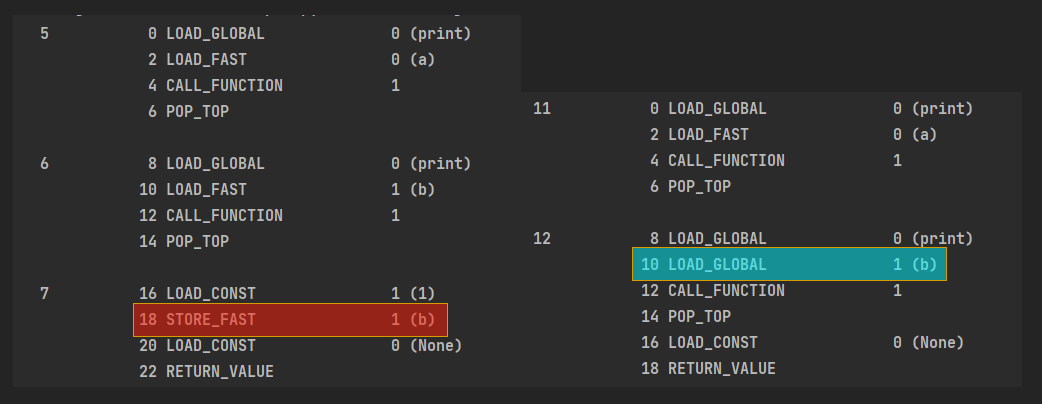
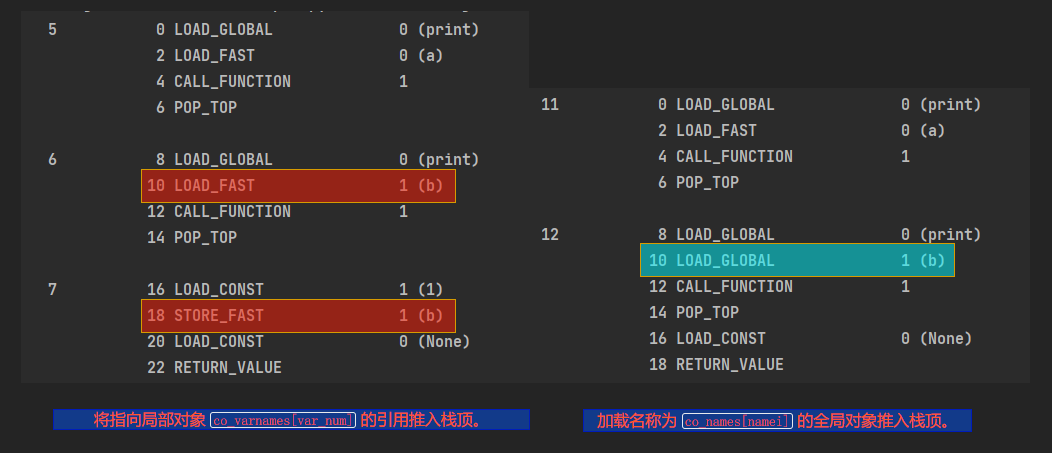
可以看到俩这的差别, 一个是将b视为FAST另一个视为GLOBAL
将fun_block中的变量加载为global可以使用global关键词声明variable
7.5 闭包
只有涉及到嵌套函数时才会有闭包, 通常情况出现在定义的函数体中使用了
lambda函数, 或者定义的装饰器内部含有函数
闭包的本质: 闭包是指延伸了作用域的函数, 其中包含函数定义体中引用, 但是不在定义体中定义的非全局变量, 闭包的关键问题不是匿名函数, 而是它能访问定义体之外定义的非全局变量
函数中创建的变量是一个局部变量。
局部变量的生命周期是等局部作用结束之后就会被释放掉。
如果内函数使用了外函数的局部变量,那么这个变量就与闭包函数发生了绑定关系,就延长该变量的生命周期。实际上就是内存给它存储了这个值,暂时不释放。
要实现一个函数不断计算系列值的均值
需要记录器历史值
方法一 类实现
使用类中和属性存储历史数值
1 | class Averager: |
方法二 高阶函数实现
1 | # 定义一个函数(类) |
我们可以在fun.__code__(表示编译后的函数定义体)属性中查看变量作用域
需要注意的是
series是make_averager函数的局部变量, 因为在函数的定义体中已经初始化了series: series = [], 可是在调用avg(10)时, make_averager函数已经返回了, 而且它的本地作用域也消失了

在averager函数中, series是自由变量freevariable, 指未在本地作用域中绑定的变量
averager的闭包延伸到那个函数的作用域外, 包含自由变量series的绑定
1 | # 查看局部变量 |
series的绑定在返回的avg函数的__closure__属性中, avg.__closure__中的各个元素对应的avg.__code__.co_freevars中一个名称, 这些元素都是一个cell对象, 可以通过cell_contents属性访问保存的值
1 | avg.__code__co_freevars |
闭包本质上是一个函数, 它会保留定义函数时存在的自由变量的绑定, 这样在调用函数时, 虽然定义作用域不可用了, 但是使用那些绑定
需要注意的是, 只有嵌套在其他函数中的函数才可能需要处理不在全局
7.6 NoncalDeclaration
改进计算累加均值的方式, 只记录总值不再记录历史数据
nonlocal declaration not allowed at module level
1 | def make_average(): |
由于str int tuple属于不可变类型, +=本质上var = var + other, 因此这样会隐式创建一个局部变量, 这样count total就无法作为自由变量存在于闭包中, 因此在实例化函数对象时会失败
1 | def make_average(): |
nonlocal会把变量标记为自由变量, 即使在函数中为变量赋予了新值, 也会称为自由变量
nonlocal的作用可以简单理解为: 允许在闭包定义的变量从局部变量转变为自由变量, 从而实现调用定义体外的变量. 从宏观上看延长了变量的生命周期(调用完函数即释放), 并使变量具有记忆
7.7 实现一个简单的装饰器
1.decorator(func)等价于
1 |
|
2.被装饰器装饰的函数, 其引用指向对应装饰器的对应内部函数
实例
这里实现了装饰器一个典型的行为, 把被装饰的函数替换成新函数, 两者接受一样的参数, 并且返回被装饰的函数本应该返回的值, 同时在这一个过程中会进行额外的操作
1 | import time |
需要注意的是:
1.装饰器会抹去被装饰器的__name__和__doc__属性, 可以使用functools.wraps装饰器把接受参数(func)的属性复制到被装饰函数中
1 | def clock(func): |
7.8 标准库中的装饰器
标准库中常见的装饰器函数有:
propertyclassmethodstaticmethod
lru_cachesingledispatch
7.8.1 lru_cache备忘
functools.lru_cache实现了备忘(memoization)的功能, 是一项优化技术, 它将耗时的函数结果保存起来, 避免传入相同参数时重复计算
LRU(least Recently Used)最近使用, 表示缓存不会无限增长, 一段时间不用会自动丢掉
lru_cache装饰器非常适合递归函数使用, 而且从web中获取信息也有很大优势
1 | import functools |
- 显示调用了10次
- 不加装饰器会调用(19次)
- 必须像常规函数一样调用
lru_cache(), 加括号的原因是其可以接受配置参数 - 叠放装饰器
@lru_cache()在@clock之前 - 需要注意的是
lru_cache可以使用两个可选参数, 签名如下:
1 | from inspect import signature |
maxsize:指定最大存储缓存数目, 满了之后旧的会被丢弃(为了最佳性能, maxsize应该设置成2的幂)typed: 为True时会把不同参数类型得到的结果分开保存(即会把通常认为相等的浮点和整形分开保存)lru_cache使用字典储存结果,key根据传入的定位参数和关键字参数创建, 所以被lru_cache都必须时hashable
1 |
|
7.8.2 单分派泛函数
分派函数: 对于不同的传参类型进行不同的处理输出, 一般使用(if-else), 时间一长就会显得十分笨拙, 而且各个模块的耦合度逐渐增高
泛函数: 根据第一个传参类型进行自适应处理输出函数组
单分派函数: 只根据第一个传参类型进行自适应判断的泛函数
多分派函数: 根据多个参数进行自适应判断的泛函数

python3.4新增的functools.singledispatch装饰器会多个函数组合成一个函数组, 甚至可以为无法修改的类提供专门的函数, 使用@singledispatch装饰的普通函数会被成泛函数
1 | from functools import singledispatch |
只要可能, 注册的专门函数应该处理抽象基类(numbers.Integral) 和(abs.MutaleSequence), 不要处理具体实现(int | list) , 这样代码具有更高的兼容性
@singledispatch装饰器不是把java重载函数带入pyhton. 实际上在一个类中为同一个方法定义多个重载变体,比在函数中使用if-elif-elif块更好用, 但是他们有个共同的缺陷, 都将代码单元(类或函数)承担了太多责任, 装饰器的好处是支持模块化扩展:各个模块可以为它支持的各个类型注册一个专门的函数
装饰器是函数, 因此可以组合起来使用类似于泛函数
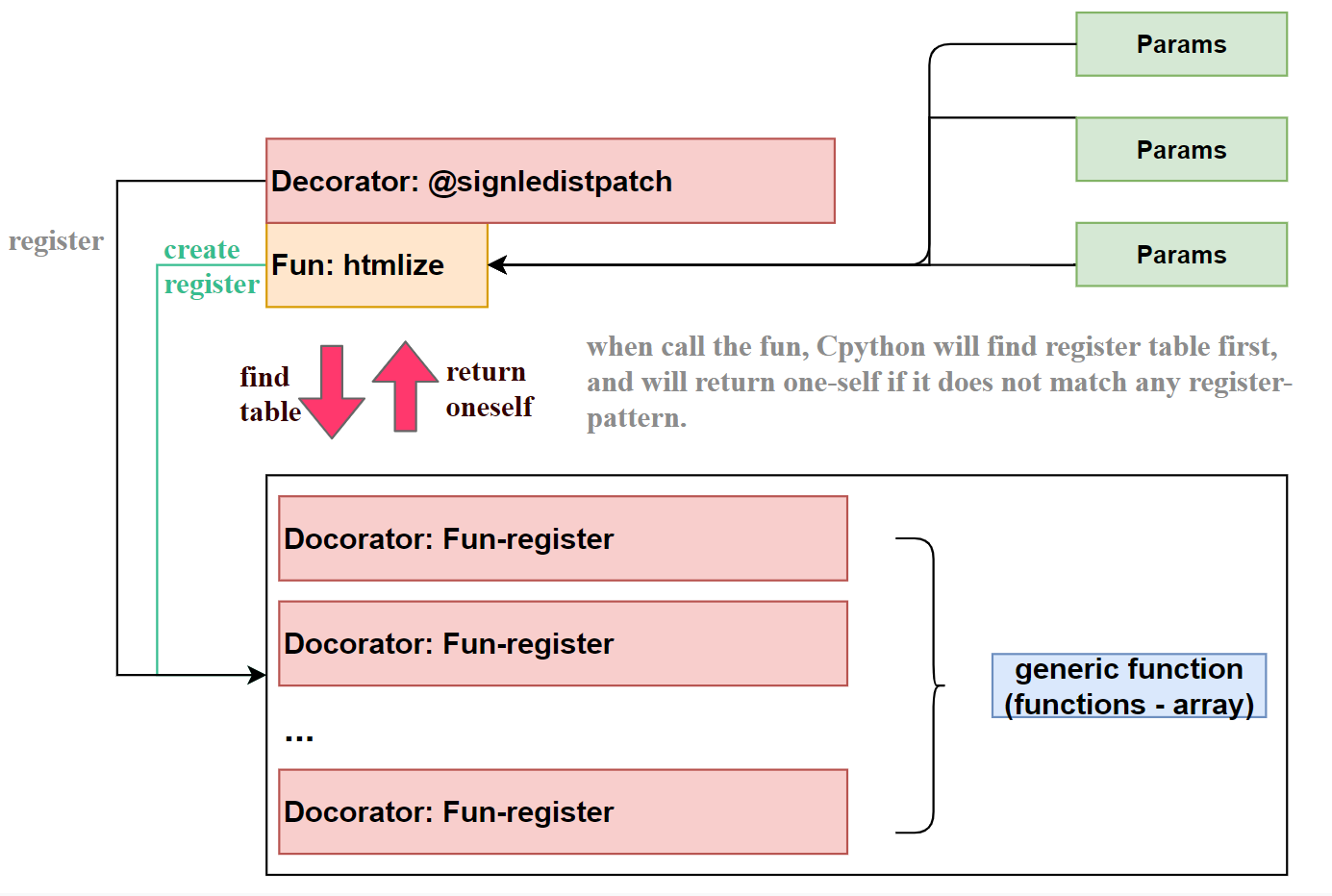
连接两者的桥梁是[fun oneself] – params – [regsiter fun]
7.9 StackDecorator
有时需要对一个函数进行多次装饰以满足现实的需求
7.10 参数化装饰器
解析源码中的装饰器时, python会把被装饰的函数作为第一个参数传递给装饰器, 如果想将其他参数传递给装饰器, 我们需要创建一个装饰器工厂函数把参数传递给工厂函数, 他将返回一个带参装饰器(函数), 再将这个装饰器运用即可
装饰器的参数化必须通过函数工厂的模式实现
7.10.1参数化注册装饰器
启用或禁用register执行的函数注册功能, 提供一个active参数, 设置为false, 不注册被装饰函数, 从概念上看, register函数不是装饰器, 而是装饰器工厂函数
如果装饰器工厂函数带有 [定位参数], 在使用装饰器时, 必须使用()带参, 否则装饰器并不会运行
1 | registry = set() |
- @register工厂函数必须作为函数调用,并且传入所需参数
- 即使不传入参数, register也必须作为函数
@register()调用, 即要返回真正的装饰器decorate, 而不是作为函数对象调用@register - 我们需要调用装饰器工厂函数返回的装饰器函数, 而不是调用装饰器对象
关键在于使用@register(param)返回一个函数作为装饰器而不是使用@register的函数对象装饰
使用@register装饰器, 装饰函数时等价于register()(func)
本质上是register()返回一个函数对象在将(func)返回带入返回的函数对象**(装饰器)**
参数化的装饰器原理相当复杂, 参数化装饰器通常会把被装饰的函数替换, 而且结构上要多一层嵌套(形成装饰器工厂函数)
7.10.2 参数化的clock装饰器
在调用装饰器时, 是否使用函数化调用
@decorate()取决于两个方面1.装饰器是否需要传参
2.是否需要调用装饰器函数(否则调用装饰器函数对象)
1 | import time |
装饰器最好的是通过__call__方法的类实现
7.11 本章小结
阅读清单
Implement Decorator [Graham Dumpleton ]
singledispatch [Guido van Rossum]
Closures [Fredrik Lundh]
杂谈
把函数作为一等对象, 就必须要考虑一个问题: 作为一等对象的函数在某个作用域中定义, 但可能会在其他作用域中调用, 如何计算自由变量呢? python给出的答案是”词法作用域”(根据定义函数的环境计算自由变量)
Part8 ObjectOriented
本章目标如下:
- variable is mark not box that stores data in python
- object reference
- mutable | varibility
- garbage collection
- tuple is unmutable data structure but it`s element can change
- shallow copy and deep copy
- object mark | value | weak reference | strong reference
- del
8.1 变量不是盒子
- 变量不存储数据, 其是marker, 用来标记数据
- 多个变量标记同一个对象, 称为alias
- 赋值=, 先执行右边的对象计算, 对象在右边创建或获取, 在此之后创建变量并将变量标记(绑定)到对象上
8.2 标识|相等性|别名
标识: 对象在内存中的地址, 一个对象一旦创建, 在其生命周期内, 其标识不会改变, 返回标识的整数表示:id() 判断标识是否相等: is
别名: 多个变量绑定到同一个对象上, 这些变量统称为这个对象的别名, 别名具有等幂性(is == id)三等
相等性: python有两种相等性 数值相等通过对象定义的__eq__ or __len__定义以及内存地址相等__id__, 两者的运算符分别是== is
1 | a = {1, 2, 3} |
对象的id在不同的实现中有所不同, Cpython中表示内存地址, 但其他的解释器中可能是别的值, 其本质是保证id唯一且在对象的声明周期内不可更改
8.2.1 is | ==
is: 比较两个对象的标识
==: 比较两个对象的值(存储的数据)
在变量与单例值的比较中使用is如与None的比较(查看变量绑定的值是否是None)
多数情况下, is运算比==快很多, 因为前者不能重载, 两者本质上的魔法方法是__id__和__eq__ + define by oneself
8.2.2 元组的相对不可变性
relative immutability of tuple
元组和多数python collection一样其内部存储的都是对象的引用, 如果引用的元素本身是可变的, 即使元组不可变其元素依然可变
元组的相对不变性指的是:tuple数据结构的物理内容(保存的引用)不可变[id()], 与引用的对象无关
str bytes array.array等单一类型序列是扁平的, 他们保存的不是引用而是在连续的内存中保存数据本身
元组中不变的是元组的标识id(), 与其内部的对象引用本身无关, 因此有些元组是不可以散列的
1 | t1 = (1, 2, [1, 10]) |
8.3 默认做潜复制
shallow copy by default
Python operations perform shallow copies by default, no special declaration is required
复制列表(或多数内置的可变集合)最简单的方式是使用内置的类型构造方法
1 | a = [1, [2, 3], (4, 5, 6)] |
构造方法或[:]都是浅复制(复制了最外层容器, 副本中的元素是源容器的引用), 如果容器内部的元素都是不可变的, 那么不会出现异常且会节约内存, 如果容器内的元素有可变类型的, 对容器内的元素进行操作会有异常现象
浅复制容易操作, 但对于可变类型来说会出现异常情况
8.3.1 DeepCopy
sometime, we will use deep copy to avoid exception.
1 | import copy |
一般情况下深复制不是一件简单的事情, 因为有嵌套引用的存在, 但有时深复制可能太深, 对象会引用不该复制的外部资源或单例值, 我们可以是实现__copy__() __deepcopy__() magic method 来自定义copy以及deepcopy的行为
8.4 函数的参数作为引用时
python唯一支持的参数传递方式是<共享传参>, 并且大多数面向对象语言都采用这一模式
共享传参指函数的各个形式参数获得实参中各个引用的副本, 换句话说函数内部的形参是实参的别名, 这种方式可能会修改作为参数传入的可变对象, 但是无法修改那些对象的标识(不能把一个对象替换成另一个对象)
函数对改变任何传入的可变参数
1 | def f(a, b): |
8.4.1 不要使用可变类型作为参数的默认值
可选参数设置默认值可以使API在进化的同时保证向后兼容, 但是我们应该避免使用可变参数作为参数的默认值
1 | class HanutedBus: |
在实例化对象时, 如果passengers为空, self.passengers变成了passengers参数默认值的别名, 这是因为默认值在定义函数时计算(通常在加载模块中), 因此默认值变成了函数对象的属性
我们可以通过审查HauntedBus.__init__对象, 查看其中的__defaults__属性中的haunted passengers
1 | print(dir(HanutedBus.__init__)) |
通过验证得出bus2.passengers是一个别名, 它绑定到了HauntedBus.__init__.__defaults__属性的第一个元素上:
1 | HauntedBus._-init__ --> return >>function |
8.4.2 Defense Var Paras
预防可变参数是指: 是否将在函数|类中对参数的处理体现到函数外部
- 防御可变参数最好的方式是: 类或函数自己维护参数, 通过
built-in constructor构造自己的参数
1 | class HanutedBus: |
除非希望这个方法修改传入的参数对象, 否则在类中直接把参数赋值给实例变量之前一定要深思, 因此这样会为参数对象创建别名, 如果不确定就使用<创建副本>的方式取变量
8.5 Del & GC
del: 删除名称, 通过删除名称减少对象引用, 进而会导致删除对象(引用为0)
对象不会自行销毁; 然而无法得到对象时, 可能会被当作垃圾回收
对象销毁情况:
- 对象引用为0
- 对象仅存在相互引用(垃圾回收程序会判断两者都无法获取进而销毁)
- 重新绑定对象导致引用为0
- 无法得到对象
__del__特殊方法不会销毁实例, 不应该在代码中调用, 但在即将销毁实例时Python解释器会调用__del__给实例释放外部资源的机会
Cpython垃圾回收算法:
引用计数
- 每个对象都会统计有多少引用指向自己
- 当引用数为0时, 调用
__del__(如果定义了)并销毁对象 - 释放分配给对象的资源(内存)
分代垃圾回收算法 [Cpy2.0]
- 检测引用循环中涉及的对象组
- 如果一组对象之间全是相互引用, 即使在出色的引用方式也会导致组中的对象不可获取
更复杂的收回算法
- 也有不依赖引用的垃圾回收算法, 这意味者对象引用数量为0时, 可能不会立即调用
__del__方法
使用弱引用可以监控对象的生命周期
1 | import weakref |
8.6 weakrefence
弱引用不会增加对象的引用数量, 不会妨碍对象被当作垃圾回收, 往往用在缓存中
1 | import weakref |
wref重新监测弱引用对象是否被释放|未释放返回对象|否则返回Nonewref()获取最近监测的弱引用对象
需要注意的是: weakref.ref类是一个底层接口, 供高级用途使用, 多数程序最好使用weakref集合和finalize
WeakKeyDictionaryWeakValueDictionaryWeakSetfinalize(在内部使用弱引用)- 不建议手动创建并处理
weakref.ref实例
8.6.1 WeakValueDict
此类实现的是可变映射, 里面的
value是对象的weakreference, 当被引用的对象被当作垃圾回收后, 对应的键会自动删除, 因此其常常用作缓存cache
1 | import weakref |
- 在
del catalog后查看stock发现仍有一个white没有deleted - 这是因为还有一个临时变量
cheese引用了cheese("white") - 可以通过
global()验证, 临时变量如果是局部变量则会在函数返回时被销毁, 但是在此次例子中,cheese是for loop中的全局变量, 需要手动(显式)删除
与WeakValueDictionary相对应的是WeakKeyDictionary, 后者的键是弱引用, 其用途为:
- 可以为应用中其他部分拥有的对象附加数据, 这样无需为对象添加属性(这对覆盖属性访问权限的对象尤其有用)
WeakSet
保存元素弱引用的集合类, 元素没有强引用时, 集合会将它删除, 如果一个类需要知道所有实例, 一种好的方案是创建一个weakset类型的类属性, 保存实例的引用, 直到实例被回收, 否则其存在时间和python进程一样长
8.6.2 Limitions(WF)
the limitions of weak reference
不是所有python对象都可以作为弱引用的目标, list dict实例就不可, 但是它们的子类可以解决这个问题
具体限制如下(受于Cpython的实现细节, 其他解释器可能有所不同), 这些局限时内部优化导致的结果
- list -> 其子类可以弱引用
- dict -> 其子类可以弱引用
- int -> 不可引用|子类也不可
- tuple -> 不可引用|子类也不可
1 | class MyList(list): |
8.7 Py对不可变类型的实现
Cpython为了优化将不可变类型的copy[:]等不创建副本而是指向同一个引用- 收到影响的有
tupleintstrbytesfrozenset
1 | a = "121" |
共享字符串字面量是一种优化措施, 称为驻留
这些trick的目的时节省内存提升解释器的速度
8.8 Summary
Python对象三要素
| 标识(id) | 不可变 | 一般是整数内存地址, 通过id()获取, is比较 |
通过构造创建副本id()不同 |
| 类型(type) | 可变但不推荐变化 | 通过__class__属性指定其他类 |
|
| 值(value) | 可变 | 通过==比较 |
赋值 | 引用 |
一般俩个变量具有相同的值== -> True, 有两种情况, 副本或者别名(共同引用), 对于不可变对象没啥区别, 如果涉及到可变变量需要小心
变量保存的是引用
- 简单的赋值不创建副本, 副本一般通过
[:]构造list()..copy.deepcopy()- 副本和引用不同的区别是, 是否开辟了内存创建了一个新对象(id不同)
+=*=的增量赋值, 如果左边的变量绑定的是不可变对象, 则会创建一个新对象赋值, 否则是就地修改- 对现有的变量赋予新值, 不会修改之前绑定的变量(重新绑定: 现有的变量绑定了其他对象), 需要注意的是, 如果该变量是该对象的唯一绑定那么, 绑定后该对象会被当作垃圾回收
- 以别名的形式给函数传参, 函数会修改通过参数传入的可变对象, 除非在函数中创建副本或传入不可变对象
- 使用可变类型作为函数参数的默认值有很大风险, 不推荐使用
- 在某些情况下需要保存对象的引用, 但不留存对象本身, 可以使用弱引用
Other
== 比较数值
is 比较引用
可变性
1.python是面向对象编程语言, 在定义类的属性时可以是可变的或不可变的
2.可变对象会导致多线程编程难以实现, 因为一个线程修改了数据如果没有及时同步就会损坏数据, 但是过度同步会导致死锁
对象析构和垃圾回收
python没有直接销毁对象的机制, 而是通过引用, 避免销毁时存在强引用
Cpython主要用过引用计数实现垃圾回收, 但是在碰到循环引用时容易泄露内存**(由于疏忽或错误造成程序未能释放已经不再使用的 内存)在Cpython2.0后引入了分代垃圾回收**(可以将引用循环中不可获取的对象销毁)
注意
1 | open("test.txt", "wt", encoding='utf-8').write("123") |
这行代码是安全的, 因为文件对象的引用数量会在write后归零, Python在销毁内存中表示文件的对象前, 会先关闭文件, 但是我们仍然提倡使用显示关闭文件, 即使用with语句, 他能保证文件一定会被关闭, 即使打开文件时抛出了异常也无妨
考虑到(其他环境|语言):
- 回收程序复杂
- 销毁对象和关闭文件时间可能会更长
1 | with open("test.txt", "wt", encoding='utf-8') as fp: |
参数传递:引用传递
传递方式有两种:
按值传递:函数得到的是参数副本
按引用传递: 函数得到的参数的指针(引用)
在python中, 函数得到是参数的副本,但是参数始终是引用, 即参数引用的副本(共享参数)
Part9 Python-Style Obj
Never use two leading underscores, it is annoyingly selfish
本章我们将自定义类并实现内置对象的结构和行为包括:
- 支持用于生成对象其他表示形式的内置函数
repr()bytes() - 使用一个类方法实现备选构造方法
- 扩展内置的
format()和str.format() - 实现只读属性
- 将对象变为可散列的, 以便在
set或作为dict的key - 利用
__solt__节省内存 - 使用
@classmethod和@staticmethod装饰器 python的私有变量和受保护属性的用法约定和局限
9.1 Obj Representation
每种面向对象语言都有一种获取对象的字符串表示形式的标准方式, python提供了
str()repr()
| 对象表示函数 | 表示类型 | 内置函数 | 返回类型 |
|---|---|---|---|
| str() | 字符串表示 | __str__() |
str (Unicode-str) |
| repr() | 字符串表示 | __repr__() |
str (Unicode-str) |
| bytes() | 字节序列表示 | __bytes__() |
bytes |
| format() | 特殊格式的字符串表示 | __format__() |
str (Unicode-str) |
| str.format() | 特殊格式的字符串表示 | __format__() |
str (Unicode-str) |
9.2 Vector Class
1 | import math |
9.3 Alternative Constructions Method
实现将
Vector的字节序列转成Vector实例
1 | # 类方法使用classmethod装饰器修饰 |
9.4 classmethod|staticmethod
@classmethod
类方法装饰器|定义备选构造方法, 用它装饰的第一个函数参数必须是cls本身, 而非self类实例, 常用于创建新的类实例
@staticmetho
静态装饰器, 装饰的函数将会与类失去交互, 常用在和类相关联的函数定义中, 但实际效果和定义在类的上下文一样, 意义更在于一种提示
1 | class Demo: |
9.5格式化显示
内置的
format()和str.format()方法本质上调用的是.__format__(format_spec)
格式规范微语言
{0.mass:5.2e}
0.mass: 在代换字段句法种是字段名,:: 分隔符5.2e: 是格式说明符
格式规范微语言为一些内置类型提供了专用的表示代码, 比如
b-> 二进制x-> 十六进制的int型f表示float类型%百分数
1 | print(format(42, "b")) |
格式规范微语言是可扩展的, 各个类可以自行决定如何解释format_spec参数, 并且一个类如果没有定义__format__方法, 从Obj继承的方法会返回str(my_obj)
格式规范微语言的本质上将类的部分参数以一定的格式显示
9.6 可散列的类
可散列的类是指类实现了
__hash____eq__方法, 且类的实例在其生命周期内hash()不变, 有时还要实现属性的只读
1.eq
使用
==或其他方式判断两个类实例是否相等
1 | def __eq__(self, other): |
2.hash
最好使用位运算符异或运算, 混合各分量的散列值
1 | def __hash__(self): |
3.属性只读
init属性时使用
self.__x双前导保证属性的私有在获取属性时, 返回私有属性并添加装饰器
@property把读值标记为特性
1 | def __init__(self, x, y): |
@property
python @property 装饰器使一个方法可以像属性一样被使用,而不需要在调用的时候带上()
4.不变性
我们有时需要实现类中的某些属性具有不可变性, 以便实现
__hash__中的id()不变
创建hashable类型, 不一定要实现[@property]特性, 也不一定要保护实例属性, 只需要正确的实现__hash__和__eq__方法即可, 但是, 实例的散列值绝不应该变化, 因此我们借机实现了只读属性
9.7 私有属性和受保护属性
首先明确两个概念, python虽然可以设置所谓的私有属性通过
two leading underscores但其并不是真正的private attribute而是一种的name mangling<命名改写>, 仅仅是一种保护装置, 通过将属性name mangling成_CLS__attr, 保护属性在继承或获取时隐藏, 但是我们依然可以使用instance._cls__attr获取属性或者对属性进行update
python不像Java使用private修饰符创建私有属性, 但是python可以通过self.__attr将属性通过name mangle改写成fake-private-attr, 起到保护作用
这样改写在一些人看来是自私的, 也有人建议通过命名soft-constraint进行约束, 即约定one leading downscore -> self._x, 如果担心命名冲突应该明确使用_Cls_attr进行属性命名
name mangle <名称改写>是一个安全措施, 其保护的是意外改写, 不并不防止故意改写
1 | from array import array |
python解释器不会对单个下划线的属性名做特殊处理, 这仅仅是一种约定, 程序员应该遵守约定, 不再类外部访问这种属性, 就像使用全大写字母编写常量- 但是在顶层名称使用一个前导下划线的话, 确实会有影响, 对
from mymod import *,mymod中前缀为下划线的名称并不会导入, 但是依然可以使用from mymod import _private_func导入 python文档中在类中使用self._x single downsoce很常见, 表示此属性为类的私有属性(很少有人称为受保护属性), 尽在内部使用(尽管是一个口头约定)
总结:
私有属性: 使用self.__x, 通过name mangle实现, 为了防止类在inherit时属性丢失以及外部访问, 但是它从本质上是一个取巧装置, 我们依然可以通过_Cls_attr外部访问并修改值
受保护属性: 使用self._x, 完全通过口头约定, 的soft sonstraint
9.8 使用slots类属性节省内存
默认情况下,
python在各个实例中名为__dict__的字典里存储实例属性, 这样做的目的是为了使用底层的散列表提升访问速度, 但是字典会大量消耗内存, 如果要处理数百万个属性不多的实例, 通过__slots__类属性, 能节省大量内存, 其本质上是使用tuple存储实例属性而不是dict
继承自超类的__slots__属性没有效果, Python只会使用各个类中定义的__slots__属性
定义__slots__的方法是, 创建一个类属性, 使用__slots__这个名字, 并把它的值设为一个字符串构成的可迭代对象, 元素为每个实例属性, 建议使用元组避免信息发生变化
1 | class Temp: |
- 类中
__slots__属性是告诉解释器, 类中的所有实例属性都在此, 这样python会在各个实例中使用类似元组的结构存储实例变量, 从而避免使用消耗内存的__dict__属性, 这样可以节省大量内存, 缓解服务器压力 (56%) __slots__不仅可以降低内存消耗, 而且运行速度也会提升__slots__定义属性后, 实例不再有所列之外的属性, 这是slots的副作用, 其本质目的是为了提升内存使用率, 而不是为了约束内存, 也不推荐这样使用- 如果在
__slots__中添加__dict__, 那节省的内存会再次被吃掉, 实例会在元组中保存属性, 此外还支持动态创建属性, 这些动态属性会出存在__dict__中 - 如果要使对象支持弱引用
weak ref, 必须在__slots__中添加__weakref__ - 如果套处理数百万个数值对象, 应该使用
Numpy数组, 其能够高效使用内存并对数值处理函数进行了高度优化
1 | class vector: |
slots的问题
__slots__: 静态属性不可滥用, 其存储的使静态属性,
__dict__:存储动态属性本质上是为了优化内存, 而不是约束属性获取
如果要同时实现对象的弱引用, 需要在其中添加
__weakref__每个子类都要继承
__slots__属性, 因为解释器会忽略继承可以创建 禁止创建动态属性 和 不支持弱引用的类
9.9 OverrideClsAttr
在定义
class的属性时, 可以在__init__之外定义class属性而非instance属性, 并且这个属性可以直接通过cls.attr访问, 即是没有初始化实例对象, 也会生成对应的cls.attr
- 类属性作为实例属性的默认值, 一旦被实例化, 类属性从用法上将转化为实例属性
- 修改类属性必须通过类修改, 实例无法修改类属性
- 类属性也可以在子类中实现
Override
1 | class Temp: |
python中class与instance关于attribute的注意事项
- 在定义
cls属性时, 相当于给instance属性做了default value, 当两者属性key冲突时, 解释器取instance属性 - 在未定义
instance属性并slef.attr获取时, 解释器回去取cls属性(default value) instance可以更新自己的cls属性- 可以通过在类中添加
__slots__声明, 将属性变为静态属性, 即只能通过cls对属性进行更新,instance拿到的是only-read - 类属性有个特点: 被实例化后变成<实例属性>
- 可以通过在类中添加
1 | class Temp: |
9.10 Summary
本章主要实现了python style的对象
有关对象的magic method
- 将对象用
strbytes展示:__str____repr____format____bytes__
备选构造方法
通过对方法使用@classmethod装饰器, 将接收cls参数, 并重构cls返回一个类**(cls)**
1 | ... |
可散列对象
- 实现
__hash____eq__ - 要保证对象在其生命周期内
hash(obj)不会变化, 通常会选择cls中的部分属性, 将其private_attr并以特性@property变为私有只读属性, 并用异或^ + hash(attr)实现__hash__
节省内存
- 使用
__slots__节省类的内存使用, 但是其本身也有其他作用- 不能隐式继承
- 声明的是静态属性与
__dict__相反(动态属性) - 会阻止不再声明内的属性的访问
- 如果要同时实现对象的弱引用, 需要在其中添加
__weakref__
属性的覆盖
- 类属性是实例属性的前置默认值, 类被实例化后, 类属性在表现形式上为实例属性
- 类属性无法通过实例修改
- 类属性在继承或实例化后可以
Override - 类属性 +
__slots__可以实现only-read
__index__
作用: 将对象强制转化成整数索引
用途: 在特定的序列切片场景使用, 满足
Numpy需求, 或需要新键一种数值类型, 并想把它作为参数传递给__getitem__方法
特性 -> [私有属性一起使用]
@property
def attr()
将类中的方法以属性的方式访问, 如果方法和类同名, 可以避免属性被意外更新
(avoid accidental updates)和私有属性一起使用
在python中我们可以大胆定义属性, 在之后使用特性, 避免属性被意外更改
1 | class Test: |
将@x.setter开打后
1 | 1 |
将属性变为公开属性 self.__x => self.x初始化不成功
1 | RecursionError: maximum recursion depth exceeded |
私有属性的安全和隐私
严格意义上私有属性没有所谓的安全和隐私
私有属性:
self.__x- soft constraint
- 通过
instance._Cls__private访问和修改
受保护属性
self._x- 口头约束
- 直接访问和修改