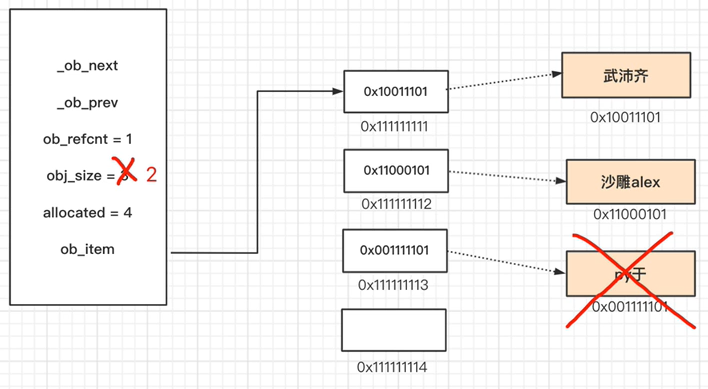
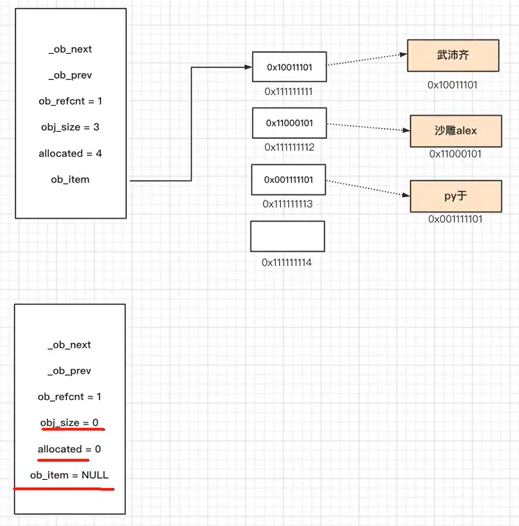
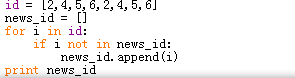
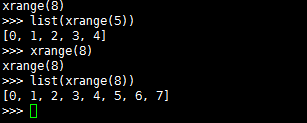
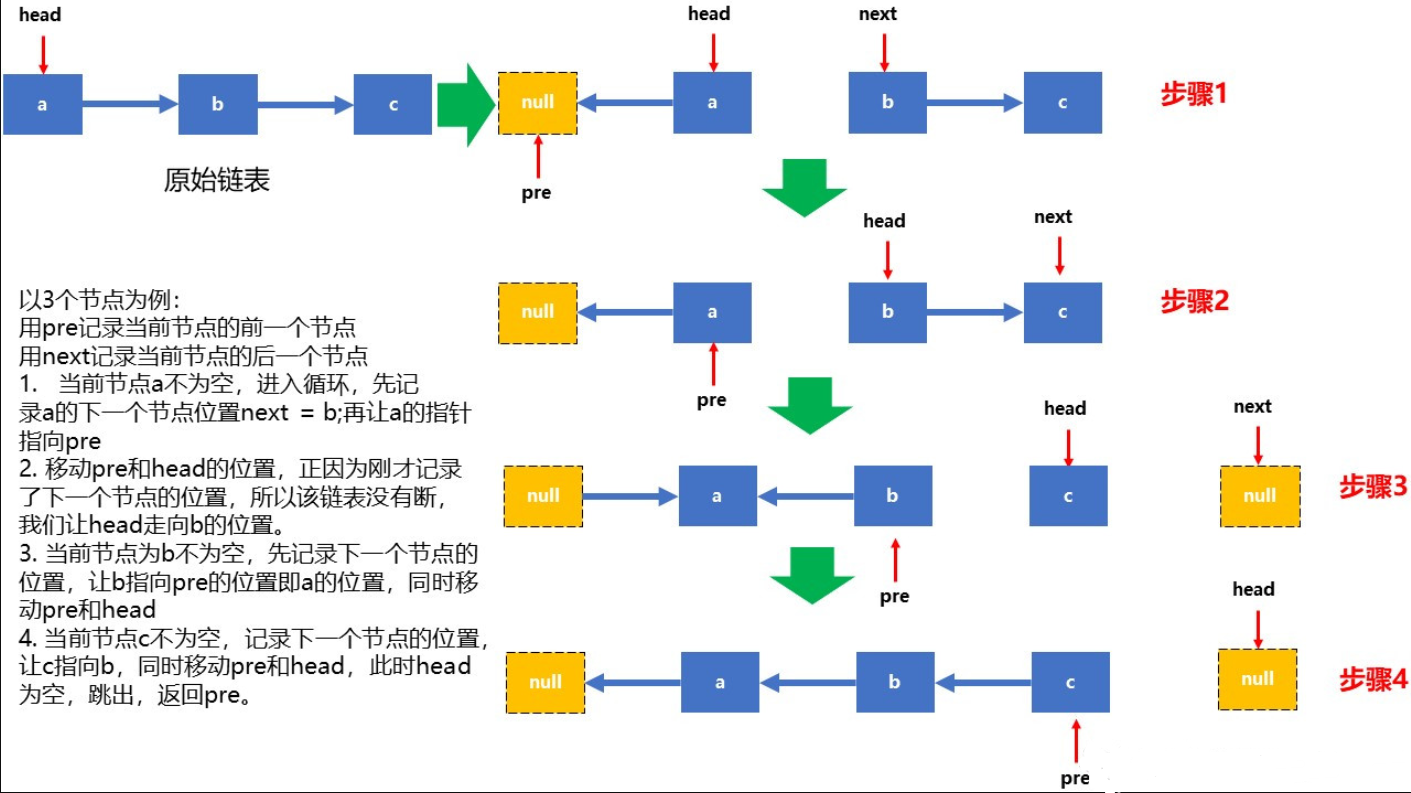
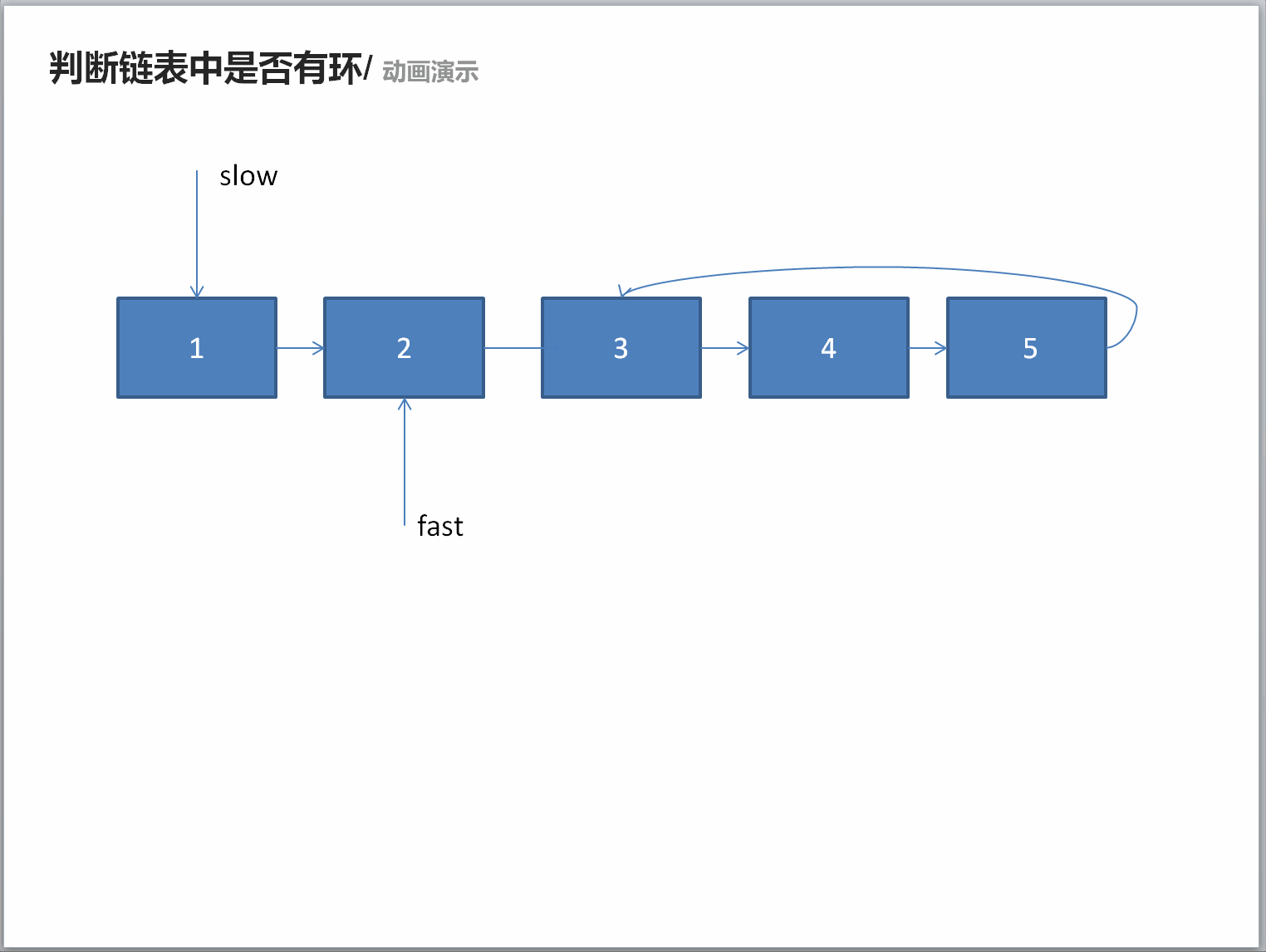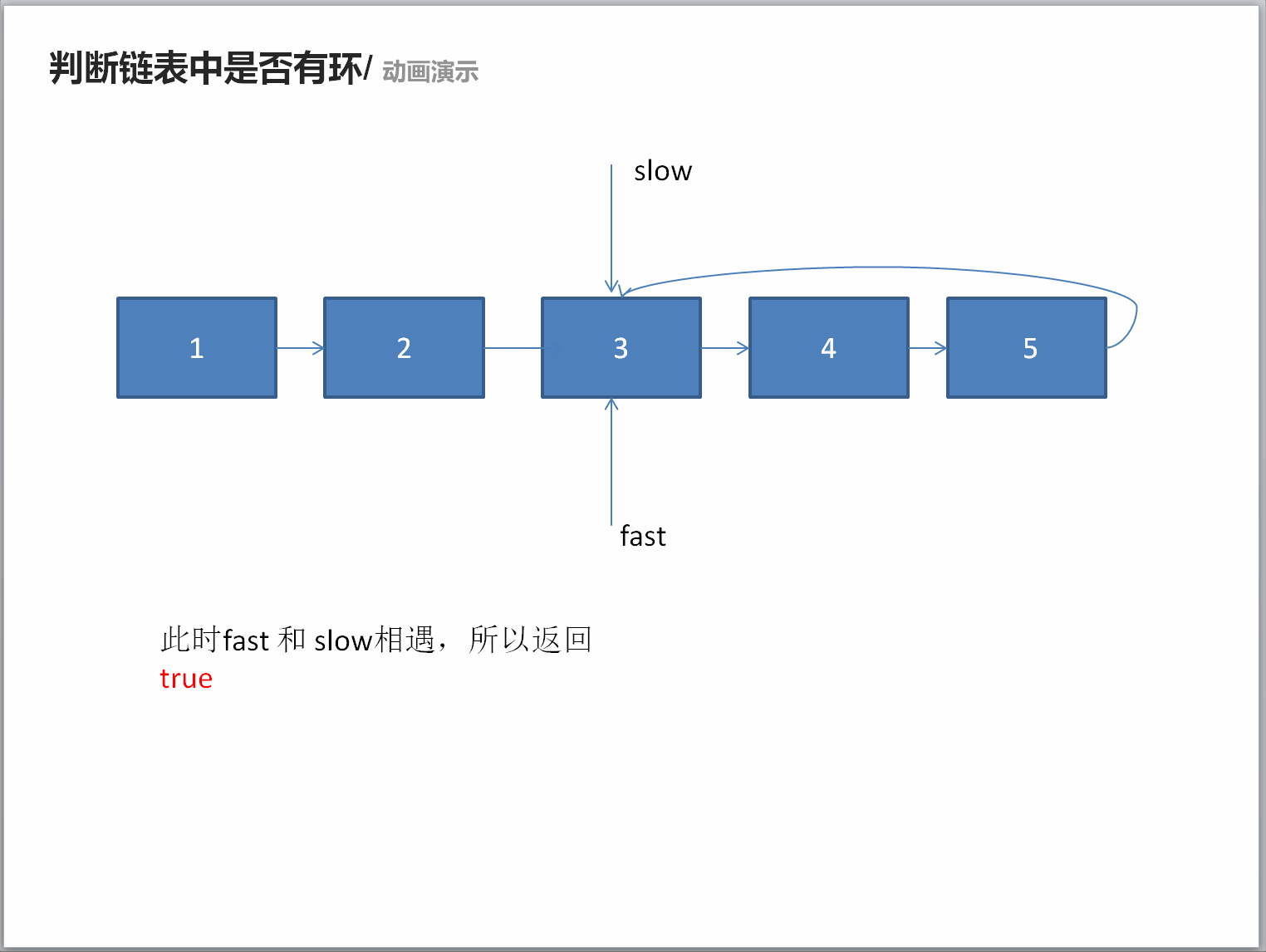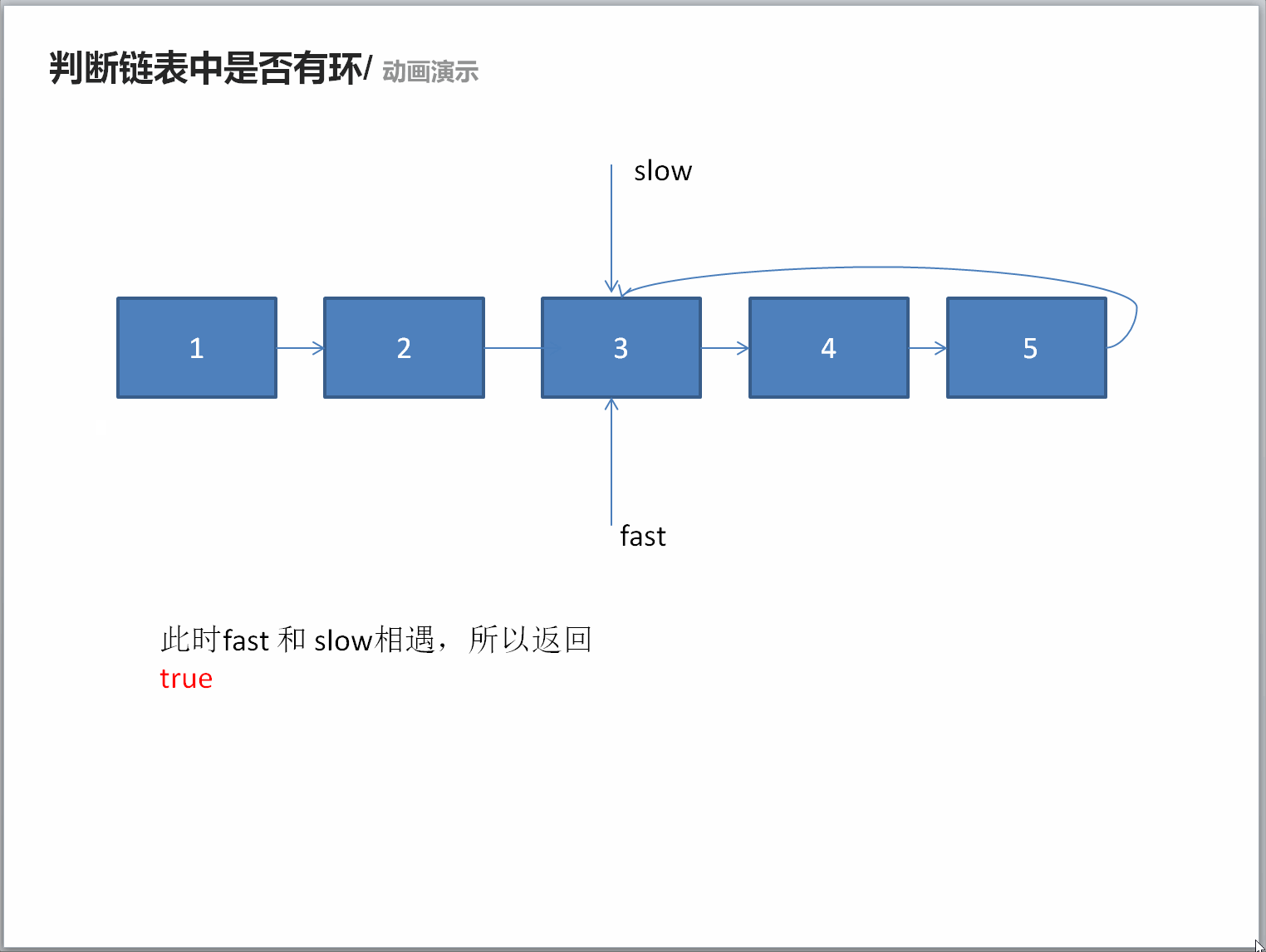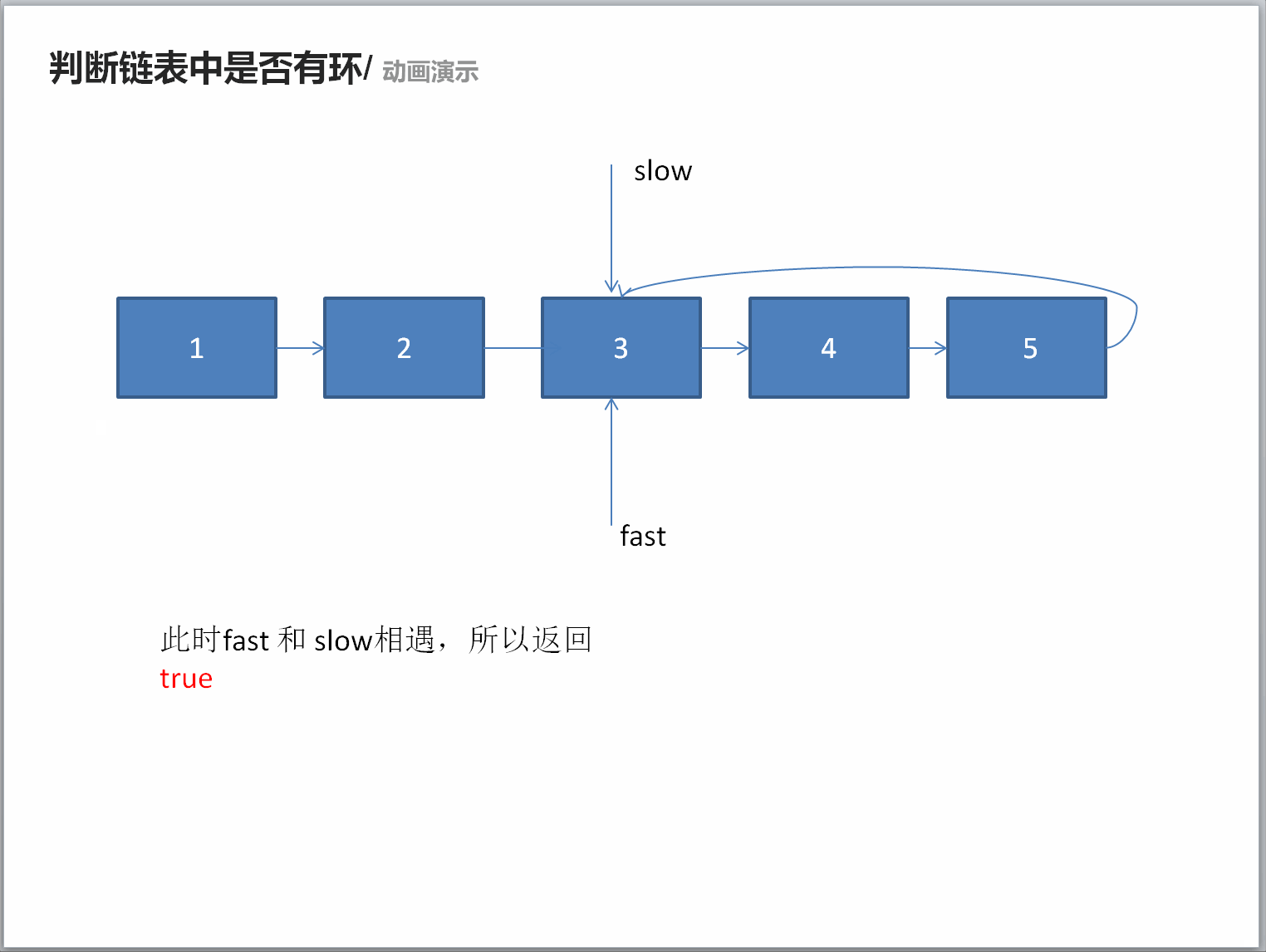
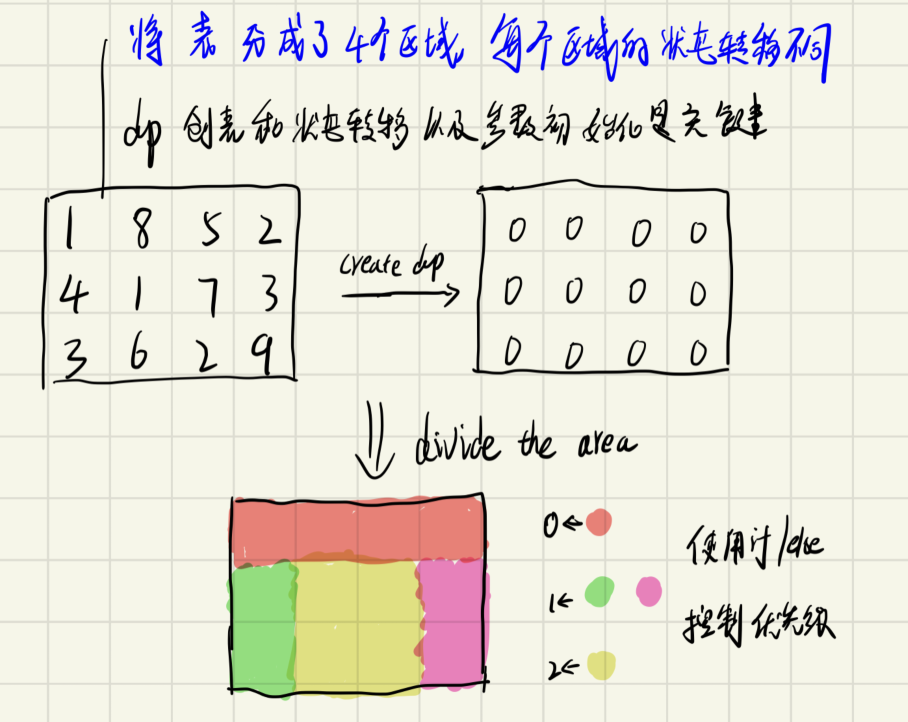
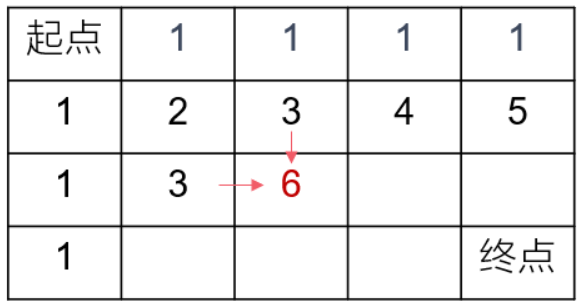
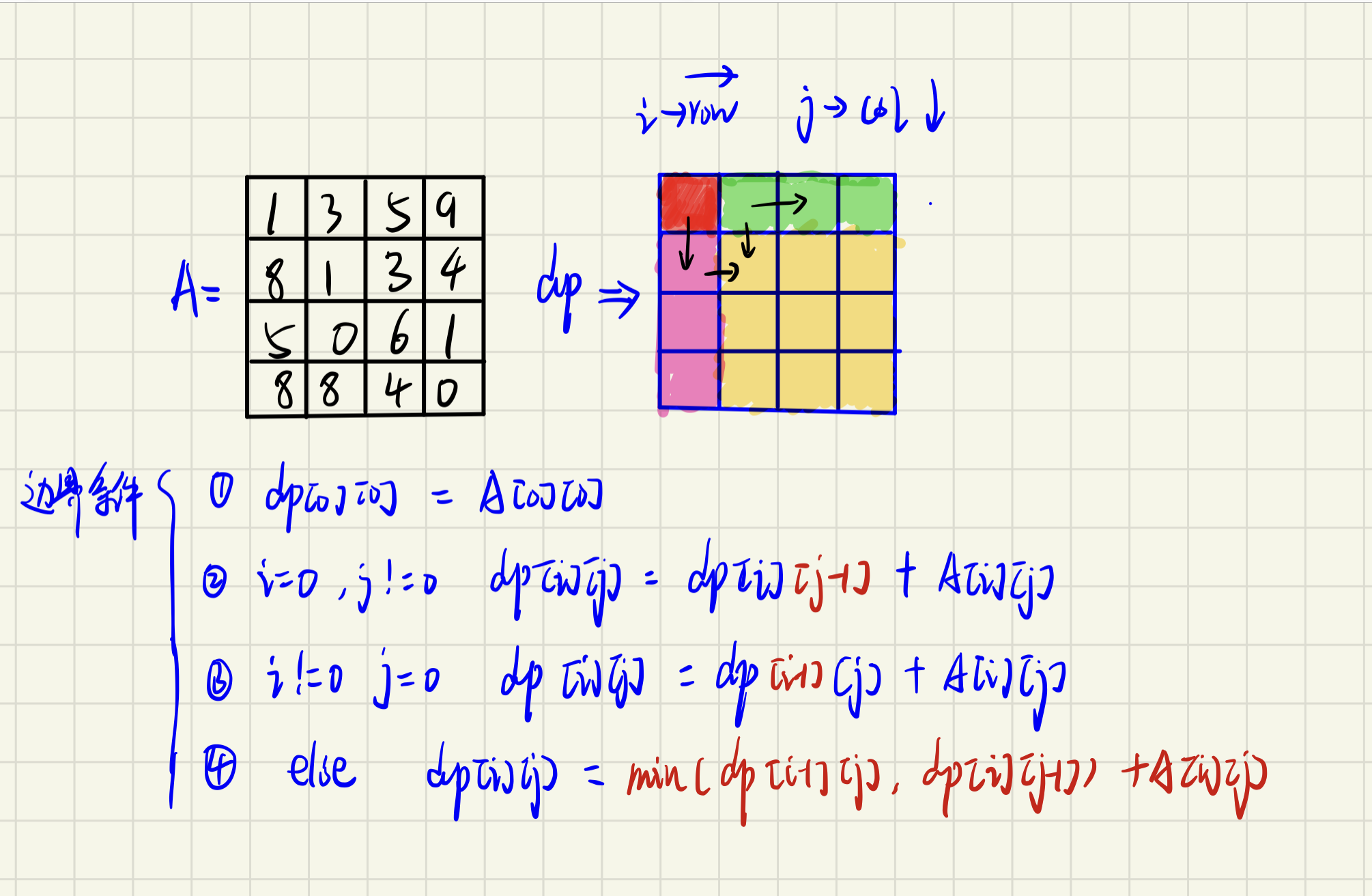
推荐阅读
第三方库
- xlrd
- Asyncio
- pandas
Target
- celery
- Mongoldb
- Nginx
- Kibana
- ElasticSearch
- Rabitmq
- redis
- git
- docker
- kafka
- tornado
Advance
- docker
Day41
str转dict
- 使用json转化
需要””才可以转化
1 | import json |
- 使用eval转化
对引号没有要求,但是具有一定的安全性问题
1 | user_info = "{'name' : 'john', 'gender' : 'male', 'age': 28}" |
安全性问题
1
2# 如果,当前目录中恰好有一个文件,名为data.py,则恶意用户变读取到了文件中的内容。
please input:open('data.py').read()
- 使用 literal_eval进行转换
综合了方法一和方法二的优点
1 | import ast |
Day40
bytes图片转jpg格式
1 | import urllib3 |
1 | import urllib3 |
Day39
merge特定提交
- 使用
git log或者git reflog查看提交信息 - 回到要
merge的分支 git cherry-pick <hash_version_num>
Day38
git 撤销commit
- 执行commit后,还没执行push时,想要撤销这次的commit
1 | soft撤销不会撤销add的文件, 同样也撤销不了merge后有conflict的文件 |
- 详细命令
1 | 如果想要连着add也撤销的话,–soft改为–hard(删除工作空间的改动代码) |
git stash指定文件
1 | git stash push <file1> <file2> <file3> [file4 ...] |
Day37
vim编辑tab
编辑vim tab空四个格
1 | 编辑文件 |
Day36
Datetime-String-Unix
datetime <–> string <–> unix 相互转化
1 | import datetime |
Day35
Linux修改文件名
文件重命名
单个文件命名
1 | sudo mv old_file_name new_file_name |
文件重命名[批量]
多个文件命名
匹配正则表达式
docker进阶
背景: 使用官方的docker-compose文档联系docker-compose
docker-compose: 可以理解为一个官方插件, 需要下载, 用于维护项目, 可以快速启动多个微服务, 需要docker-composeyml文件配置各个微服务间的依赖关系, 并使用docker-compose build docker-compose up启动服务
1 | curl -L https://get.daocloud.io/docker/compose/releases/download/1.25.5/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose |
过程如下:
- 根据yml文件目录(即项目目录名)创建一个默认的网络,
project-compose_default, 会将所涉及的所有微服务共同至于一个网络下, 这样可以使用域名而非ip进行访问 - 根据yml文件创建对应的container容器
- 启动服务, 开启项目
官网docker-compose
创建目录composetest, 所有的文件均创建在此目录下
- 创建应用(app.py)
1 | import time |
- 创建
Dockerfile构建imagse(打包服务和环境)
1 | FROM python:3.6-alpine |
- 创建
docer-compose.yml(启动项目, 构建各个微服务之间的依赖)
1 | version: "3" |
- 创建
requirements.txt(依赖环境)
1 | redis |
Review
- 在
docker-compose build出现error时, 需要执行docker rm $(docker ps -aq)删除所有存在且不可用容器
Day34
Dal[数据交换层]
DAL是[数据访问层]英文缩写,即为数据访问层(Data Access Layer)。其功能主要是负责数据库的访问。简单地说就是实现对数据表的Select(查询)、Insert(插入)、Update(更新)、Delete(删除)等操作。
Dal一般有自己的服务器IP, 可以进入查看相应的log, 如果Dal做了负载均衡, 最好的方式是通过script查看对数据的访问
Day33
asyncio[异步]
1 | async def main(): |
Day32
vim命令
1 | h Move left |
Day31
执行order
1 | 查看linux所有history order |
Day30
判断bool
1 | bool(var) |
Day29
服务器之间传递文件
两台Linux服务器之间传输文件的四种方法 - 知乎 (zhihu.com)
1 | 从本地复制到远程 |
- 如果没有权限使用root用户(默认通过ssh连接)
scp /Users/edy/PycharmProjects/TXM/component/tasks/order_tasks.py root@59.110.228.229:/root/
在容器内修改项目
- 砍掉上线这一步骤, 节约时间
- 在测试服进行debug
1 | 在宿主机与container中copy文件 |
1 | modify local file |
Day28
连接本地服务[wait]
Day27
For-loop
1 | tmp = [] |
集合取交集
用法: set().intersection(set_1, set_2|iterable)
- intersection()可以任何可迭代集合
- 返回的是set
intersection() 方法返回包含两个或更多集合之间相似性的集合。
含义:返回的集合仅包含两个集合中都存在的项目,或者如果使用两个以上的集合进行比较,则在所有集合中都存在。
1 | module_list = ['assistant', 'moments', 'friend-welcome', 'xxxx'] |
1 | x = {"a", "b", "c"} |
Day26
Shell[命令]
查看磁盘
1 | 1.命令格式: |
1 | 搜索执行的命令 |
mongodb模糊查询
1 | # / 是mongodb的通配符 |
Day25
环境
- DEV|自测
[Development environment]开发环境,外部用户无法访问,开发人员使用,版本变动很大。
- TEST
[Test environment]测试环境,外部用户无法访问,专门给测试人员使用的,版本相对稳定。
- SIT
[System Integration Test]系统集成测试,开发人员自己测试流程是否走通。
- UAT
[User Acceptance Test environment]用户验收测试环境,用于生产环境下的软件测试者测试使用。
- PRE
[preparatory environment]灰度环境,外部用户可以访问,但是服务器配置相对低,其它和生产一样,外部用户可以访问,版本发布初期,正式版本发布前。
- PRD|PRO
[Production environment]生产环境,面向外部用户的环境,正式环境,连接上互联网即可访问。
- FAT
[Feature Acceptance Test environment]功能验收测试环境,用于软件测试者测试使用
Day24
线上script
获取线上数据库时使用script, 其中需要登陆线上的服务器中的docker
写法:
1 | # 头文件 |
Day23
分支关联
本地分支与远程分支关联(隐式关联)
1 | git branch --set-upstream-to=origin/<branch> dev_lyh_private_send |
sheet_name[规范]
Excel工作表表名不能用下列字符:
冒号——:
斜杠——/
问号——?
反斜杠——
星号——*
方符号——[ 或 ]
构成工作表的表名字符个数不得超过31个。
Day22
Python字符串编码格式
unicode编码
Python中的编码格式
字符串的编码一开始是 ascii,只支持英文,由于多种语言的存在,出现万国码 unicode,但 unicode 不兼容 ascii,而且对存储空间造成浪费,所以出现 utf-8 编码,一种针对 unicode 的可变长度字符编码。
在 Python3 中共有两种字符序列。一种是 str 序列,默认对字符串编码;一种是 bytes 序列,操作二进制数据流,如代码段一中的 hi,通过在字符串前的 b,即表示 bytes 。这两种序列可通过 decode 和 encode 相互转换
在网络传输中,如 urllib、request 等获取数据的库,通常返回 bytes 序列,这时可通过 decode 指定相应的格式经行解码,获取中文字符。
1 | # 以b开头 --> bytes序列 |
方法一:使用unicode_escape 解码
1 | # |
方法二:使用encode()方法转换,再调用bytes.decode()转换为字符串形式
1 | s = r'\u4f60\u597d' |
方法三: 使用json.loads 解码(为json 格式)
1 | str = '\u4eac\u4e1c\u653e\u517b\u7684\u722c\u866b' |
方法四:使用eval(遇到Unicode是通过requests在网上爬取的时候)
1 | response = requests.get(url,headers=headers) |
Day21
调试API
- 本地调试http, 不用https
[1, 2]转化成[“1”, “2”]
使用map函数
描述
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
语法
map() 函数语法:
1 | map(function, iterable, ...) |
Day20
获取维度数据
operator中的itemgetter函数
from operator import itemgetter
该函数的作用是获取对象的某个/些维度的数据, 默认将对象的维度看为1维 该函数的使用方法:
- 定义一个itemgetter函数,并指定获取某个对象中哪些维度的值
- 用定义好的函数作用于对象
example
1 | from operator import itemgetter |
1 | from operator import itemgetter |
字典列表排序
1 | from operator import itemgetter |
python封装「,」
1 | # 联系使用多个变量并用,进行连接时 python会将其自动封装成tuple |
Day19
本地远程测试
- mac terminal
ifconfig找到en0>> inetip地址, 将localhost替换成inet地址即可远程连调
本地测试
开展本地测试首先在config中配置本地环境
http://127.0.0.1:9000/controllername/api_name
TXM上线
团小蜜测试服打完release-v_test_0.26.97tag后, 直接push到远程分支, 不用运行sh脚本直接可以上线
Git|删除Tag
git 删除本地标签:
1 | git tag -d 标签名 |
git 删除远程标签:
1 | git push origin :refs/tags/标签名 |
git 删除本地模块标签的操作
1 | git submodule foreach git tag -d 标签名 |
git 删除远程模块标签的操作
1 | git submodule foreach git push origin :refs/tags/标签名 |
Day18
mongo聚合查询
1 | # aggregation |
Day17
时间戳
time.time()
格林威治时间1970年01月01日00时00分00秒起至现在的总秒数
db.collection.findOne()._id.getTimestamp()
世界标准时间
ISODate时间ISODate(“2013-03-01T00:00:00Z”) + 你的时区
北京+8h
查看log
- 进入服务器
1 | ssh root@ip |
- 查看镜像
1 | docker ps |
- 根据kibana-index进入对应的镜像内
1 | 静态查询 |
查询技巧
- 显示所有log
1 | 显示某个指定容器log |
- 显示实时log
1 | docker logs -f [docker_id] or [docker_name] |
- 动态显示log尾部
1 | docker logs -f --tail 100 [docker_id] or [docker_name] |
- 使用grep过滤log
1 | 查找所有包含"error"的log |
- 根据时间进行log的查找
1 | docker logs --since 2021-08-25T12:01:46.452616Z [容器Id] or [容器name] |
- 组合查询
1 | docker logs -f --tail 100 容器id | grep info |
Day16
使用GIT进行版本控制
以Mac为例
- 查看git version
1 | git --version |
- 安装git
1 | sudo apt-get install git |
- 配置git
git跟踪谁修改了项目, git必须知道你的用户名, 但你可以使用一个虚假的emial
1 | git config --global user.name "username" |
- 创建项目|以下操作非必要说明均在
sub_dir中使用命令
1 | cd super_directory |
- 初始化仓库
git在对应的目录中初始化一个空的仓库, 仓库是指程序中被git主动追踪的一组文件. git用来管理仓库的文件都存储在.git/这个隐藏目录中, 包括index/ local git, .git存放着项目的所有历史记录
1 | git init |
- 检查状态
git中一个分支代表一个版本对应一般开发一个功能
1 | git status |
- 查看历史提交
每次提交时, git都会生成一个包含40字符的UID, 记录提交是谁执行的|提交的时间以及提交的指定信息
1 | git log |
- 撤销修改
git checkout命令用于切换分支或恢复工作树文件。git checkout是git最常用的命令之一,同时也是一个很危险的命令,因为这条命令会重写工作区。
放弃修改, 恢复到前一个可执行状态
将working的修改放弃, 回到最近一次commit代码, 如果已经通过add进入indexing则无法撤回
注意:在checkout时会影响到working code, 因此必须在checkout时先add -commit或者stash push
1 | 撤销当前working代码, 回到前一次commit |
- 回退分支
版本–分支–code
git rest --hard HEAD^:回退到上一版;git rest --hard HEAD^^:回退到倒数第二版;git rest --hard 3628164:回退到commit id为3628164的版本;
lunix
Apt: advanced packaging tool 高级封装工具
- 下载软件
1 | sudo apt-get install package_name |
- 更新软件
1 | sudo apt package_name |
- 删除软件
1 | sudo apt remove package_name |
- 更新所有可升级软件
1 | 列出所有可更新的软件清单命令:sudo apt update |
Day15
体系
- uid与wxid打通==>生态闭环
- 分销==>打通ERP
- 目前主打社群沉淀与私域流量维护
- to b和to c两种用户画像
- to b 注重流量维护|社群沉淀
- to c 注重营销
git常用命令
- 初始化仓库
git init repo_name
- 将远程仓库clone到本地
git clone https://gitee.com/cr_rui/drugstore.git
添加远程仓库到本地
git remote add origin https://gitee.com/cr_rui/drugstore.git本地分支连接远程分支
git branch -u origin/name
- 将当前分支推送到远程上的同名的方便方法
git push origin HEAD
- 删除远程分支
git push origin --delete 'branch_name'
- 删除本地分支
git branch -d 会在删除前检查merge状态(其与上游分支或者与head)。
git branch -D 是git branch –delete –force的简写,它会直接删除。
git branch -d|D 'branch_name'
都是删除本地分支的方法(与删除远程分支命令相独立,要想本地和远程都删除,必须得运行两个命令)
chain
1 | chain(*iterables) --> chain object |
1 | import itertools |
string:可迭代对象
1 | import itertools |
Day14
filter
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
**注意:** *Python2.7 返回列表,Python3.x 返回迭代器对象*
使用方法
1 | filter(function, iterable) |
example:
1 | a = [i for i in range(10)] |
Day13
Git|stash
在add之后进入index, 此时可以使用git stash save “info”将改动的code放在stash库中, 地址.git/refs/stash
stash库没有branch的限制, 可以在任意的branch将code拿出来, 切换到对应的branch
1 | push stash |
Day12
手机|API传视频参数
**手机端:**只需要response的值一样即可, 用户在手机端只需要点击视频即可, 不需要request
**API调用:**不仅需要传入的参数request一样, 而且也需要response的值一样
任务传播流程

在传递过程中, 尤其是API的调用存在参数的校验
对外的接口可以在一级传参中进行封装
1 | a = input('a=') |
回调
For a client-side API I could guess something like this:
- You make an API call to some url.
- You receive a response
- A callback function is called with the response as its arguments
illustration/·ai-lou-s·-·zhui·-·shen·/

thumb_url
缓存文件
Thumbs.db只是一个图片索引文件,可以加速你用缩略图方式查看图片,会随着文件夹的图片的增多也体积增大。
Day11
vim编辑器
1 | vim file # 查看文件不编辑 |
回调API设置
首先启动API, 新起一个API_test, 对照API开发文档将所需参数填入, 运行后查看response值
之后在database中查找对应的module_id
在源码中查看所有打出response的情况, 并在log中寻找
- 在log中查找关键词
调用客户info中打印
Day10
debug后的版本提交流程
「整体上分为三个部分」
- 进入项目目录查看当前修改的内容, 确认是否要将修改的文件推上测试服
- 对文件根据命名规则打上tag
- 进入docker修改指定项目的deploy-debug.sh
0.查看状态
1 | 对当前分支状态进行查看,使用的最频繁的命令 |
1.进入项目目录
1 | cd Priject_Debug |
2.查看目录状态
1 | git status |
3.暂存分支
1 | git stash # 暂存分支 |
保存当前的修改,但是想回到之前最后一次提交的干净的工作仓库时进行的操作git stash将本地的修改保存起来,并且将当前代码切换到HEAD提交上.
4.创建|切换分支
1 | 切换已经存在的分支 |
5.查看log
1 | git log |
6.查看改动|提交指定文件
1 | 查看xxx.py文件哪里出现了改动 |
7.打上tag|push tag
1 | 在阿里云服务中查看命名规则 |
8.将分支关联到远程分支
1 | origin 是默认的远程版本库名称 |
9.容器|上线测试服
使用到7中的tag版本
1 | ssh root@测试环境ip |
10.拉version-tag
1 | # 1.将远程代码clone到本地 |
script调试
在docker中对写死的脚本进行调试, 尽量加上所有的import, 如果出现“NoneType” object is not callable, 检查是否初始化了basemode父类
调用格式:
1 | BaseModel.init_model_dict() |
Day9
Python内置装饰器
@property|属性方法
1.@property的使用
@property是python的一种装饰器,用来修饰方法。
@property是把类内方法当成属性来使用,使用@property装饰器来创建只读属性
@property装饰器会将方法转换为相同名称的只读属性,必须要有返回值,相当于getter
2.@property
在类中使用, 对类中的方法进行装饰, 将方法装饰成只读属性, 在本质上相当于getter, 并且必须有返回值
@staticmethod
- 在类中声明一个静态的方法
- 这个方法不接收
cls和self参数 - 这个静态方法并不能访问类属性或者实例属性
- 可以使用
ClassName.MethodName()和object.MethodName()调用 - 它可以返回类的对象
1 | class Student: |
1 | Student.tostring() # 调用class的statcimethod |
The static method cannot access the class attributes or instance attributes. It will raise an error if try to do so.
1 | class Student: |
1 | Student.tostring() |
@calssmethod
0.用于预处理实例化对象时所接受的参数,并且返回一个初始化的类
1.作用
将类中的实例方法改为类方法, 必须接受一个cls参数, 并且返回一个初始化的类
- 在创建一个实例化对象时使用
- 不加装饰器的类中方法, 均是实例化方法, 只能对实例化对象进行操作, 无法对类进行操作
2.使用场景
在创建一个实例化对象时, 对接受的参数格式进行预先调整, 并将调整好的格式付给类, 相当于在创建实例化对象时, 现根据参数创建一个自适应的初始类
3.好处
- 将处理函数封装在类中, 代码更加简洁
- 使代码更加容易维护
4.缺点
- 在实例化时需要调用classmethod
1 | class A: |
Day8
API调用
⚠️:如果API在目录controller中不存在controller/api_controller,即不存在action_api_controller那么此api在ZidouBiz/api_controller里,并且命名规则为api_action[set|get|del]
action_api:可以被外界调用
api_action:内部api
使用apipost调用简单的api时[在api_controller中存在]
一般在apipost可以测试的都是action_api_name
端口需要在源文件中查询
http://127.0.0.1:8000|9000/class_name/api_name
1 | # 文件结构如下 |
⚠️:紫豆所有api调用request都是post请求,在测试调用API时使用使用pycharm中的本地文件进行调用
调用一次api需要获得sign
function:调用的api==>本地存住在api_controllert.py
action:增删改
⚠️:tokrn不是secret, secert的获取开通API接口
需要修改的参数有:
1 | phone<-->secret==>紫豆后台获取 |
Counter
计数器:返回一个实力化对象「dict」,对象本身iterable
可以使用list(Counter.items|keys(default)|value()) 查看对应的返回值
1 | from collections import Counter |
Day7
熟悉项目
- 通过script运行部分函数加深了解
紫豆助手
项目介绍
- 本项目是一个微信社群管理工具,可以通过微信机器人实现一些自动化操作,并统计微信群的各种信息。
- 本项目使用了类似MVC的设计模式,Model将MongoDB的数据封装为统一的model类以便使用,Controller接受前端的接口调用并实现所需功能。
- 本项目有两种方式处理外部信息,第一种是接受接口调用,url格式为 domin/controller_name/interface_name,Controller中可被外界调用的接口,函数名必须加上”action_”前缀, 接口返回值必须用make_response方法。第二种是处理Android_Server通过RabbitMQ发来的微信实时消息,消息于celery的celery_newmsg队列中,项目中处理消息的方法在component/msg_handler中。
目录结构
1 | ├── celery_app.py 初始化celery配置 |
环境配置
安装python 3.6.4以上, 运行pip install -r config/requirements.txt安装依赖包 安装Redis 如果想在服务器运行还需要: MongoDB, ElasticSearch, RabbitMQ, Nginx, Supervisor 如在生产环境运行,务必在主目录下创建名为”online_config”的文件,用来区分生产环境与正式环境,切记。
Docker
1 | ssh root@test_env_ip |
cls
一、cls含义
python中cls代表的是类的本身,相对应的self则是类的一个实例对象。
二、cls用法
cls可以在静态方法中使用,并通过cls()方法来实例化一个对象。
mongo
| mongodb聚合操作 | SQL 操作/函数 |
|---|---|
| $match | where |
| $group | group by |
| $match | having |
| $project | select |
| $sort | order by |
| $limit | limit |
| $sum | sum() |
| $sum | count() |
| $lookup (v3.2 新增) | join |
Day6
变量
类对象
指在对class进行实例化时所创建的对象object,在class中如果定义了一个_attribute,虽然在instance.attribute无法访问,但可以使用instance._attribute进行访问
1 | xx:公有变量 |
Day5
缺省
缺省=default
Head|Body
Head
head定义文档的头部,是所有头部元素的容器。
<head>中的元素可以引用脚本、文档的各种属性和信息,包括文档的标题、在web中的位置以及和其它文档的关系等。绝大多数文档头部包含的数据都不会真正作为内容显示给读者。
<title>、<meta>、<link>、<style>、<script>
应该把 <head> 标签放在文档的开始处,紧跟着<html> 后面,并处于 <body> 标签之前。
文档的头部经常会包含一些 <meta> 标签,用来告诉浏览器关于文档的附加信息。
Body
1 | 一个页面的信息,也就是浏览器呈现出来的,用户看到的页面效果。也就是说这里是网页的主体 |
DOM
文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。它是一种与平台和语言无关的应用程序接口(API),它可以动态地访问程序和脚本,更新其内容、结构和www文档的风格(目前,HTMl和XML文档是通过说明部分定义的)。文档可以进一步被处理,处理的结果可以加入到当前的页面。DOM是一种基于树的API文档,它要求在处理过程中整个文档都表示在存储器中。另外一种简单的API是基于事件的SAX,它可以用于处理很大的XML文档,由于大,所以不适合全部放在存储器中处理。
XHR
1、概念
xhr,全称为XMLHttpRequest,用于与服务器交互数据,是ajax功能实现所依赖的对象,jquery中的ajax就是对 xhr的封装。
2、xhr
XMLHttpRequest 对象提供了对 HTTP 协议的完全的访问,包括做出 POST 和 HEAD 请求以及普通的 GET 请求的能力。XMLHttpRequest 可以同步或异步地返回 Web 服务器的响应,并且能够以文本或者一个 DOM 文档的形式返回内容。
xhr 接口强制要求每个请求都具备严格的HTTP语义–应用提供数据和URL,浏览器格式化请求并管理每个连接的完整生命周期,所以XHR仅仅允许应用自定义一些HTTP首部,但更多的首部是不能自己设定的。
浏览器会拒绝绝对不安全的首部重写,以保证应用不能假扮用户代理、用户或请求来源,如Origin由浏览器自动设置,Access-Control-Allow-Origin由服务器设置,如果接受该请求,不包含该字段即可,浏览器发出的请求将作废。
如果想要启用cookie和HTTP认证,客户端必须在发送请求时通过XHR对象发送额外的属性(withCredentials),而服务器也需要以Access-Control-Allow-Credentials响应,表示允许应用发送隐私数据。同样,如果客户需要写入或读取自定义HTTP标头或想要使用“非简单的方法”的请求,那么它必须首先通过发出一个预备请求,以获取第三方服务器的许可!
AJAX
AJAX = 异步 JavaScript 和 XML。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
传统的网页(不使用 AJAX)如果需要更新内容,必需重载整个网页面。
Day4
API测试
1 | import requests |
Api请求
get|post区别
- 最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数
| get | post | |
|---|---|---|
| 回退 | 无害 | 再次提交 |
| 产生url被bookmark | 可以 | 不可以 |
| 主动被浏览器cache | 会 | 不会 |
| request编码 | url | 多种 |
| 请求参数在浏览器的历史 | 会 | 不会 |
| url传递的参数 | 长度受限 | 无限制 |
| 对参数的数据类型 | ascii | 无限制 |
| 安全性 | 参数暴露在url中 | 安全 |
| 参数传递方式 | url | request body |
Str.encode
Python encode() 方法以 encoding 指定的编码格式编码字符串。errors参数可以指定不同的错误处理方案。
| 参数 | 描述 |
|---|---|
| encoding | 可选。字符串。规定要使用的编码。默认是 UTF-8。 |
| errors | 可选。字符串。规定错误方法。合法值是: ‘backslashreplace’ - 使用反斜杠代替无法编码的字符 ‘ignore’ - 忽略无法编码的字符 ‘namereplace’ - 用解释字符的文本替换字符 ‘strict’ - 默认值,失败时引发错误 ‘replace’ - 用问号替换字符 ‘xmlcharrefreplace’ - 用 xml 字符替换字符 |
dict.update
1 | # 将dict中的key-value更新到supdict中,其中如果碰到key-conflict,则更新key-value |
json基本操作
一般是python对象「str|dict|tuple|dict」与json(可以理解为dict+)
json => {“key”: “value”} 双引号
dict =>{‘key’: ‘value’}|双引号|单引号都可以
- dumps
将python对象格式化成json字符
- loads
将字符串解码成python对象
- dump
将python对象写入json文件中
- load
加载json格式文件,返回python对象
1 | import json |
logging|查看log
什么是log?
记录某些软件运行时所发生事件的方法
日志的作用
- 了解软件|系统|应用运行情况
- 分析用户操作行为|类型
- 发现bug解决问题
日志的等级
通常只需要记录应用程序的异常信息、错误信息等,这样既可以减小服务器的I/O压力
- DEBUG
- INFO
- NOTICE
- WARNING
- ERROR
- CRITICAL
- ALERT
- EMERGENCY
日志的格式
一条日志信息对应的是一个事件的发生
- 事件发生时间
- 事件发生位置
- 事件的严重程度–日志级别
- 事件内容
日志的格式可以自定义
log的实现【logging】
标准库函数
logging模块默认定义了以下几个日志等级,它允许开发人员自定义其他日志级别,但是这是不被推荐的,尤其是在开发供别人使用的库时,因为这会导致日志级别的混乱。
| level | 描述 |
|---|---|
| DEBUG | 最详细的日志信息,典型应用场景是 问题诊断 |
| INFO | 信息详细程度仅次于DEBUG,通常只记录关键节点信息,用于确认一切都是按照我们预期的那样进行工作 |
| WARNING | 当某些不期望的事情发生时记录的信息(如,磁盘可用空间较低),但是此时应用程序还是正常运行的 |
| ERROR | 由于一个更严重的问题导致某些功能不能正常运行时记录的信息 |
| CRITICAL | 当发生严重错误,导致应用程序不能继续运行时记录的信息 |
- 开发时,使用debug或info来获取详细的日志信息,进行来发部署
- 上线时,使用warning|error|critical级别的日志来降低I/O提高效率
「上面列表中的日志等级是从上到下依次升高的,即:DEBUG < INFO < WARNING < ERROR < CRITICAL,而日志的信息量是依次减少的」
「当为一个应用程序指定log level时,只会记录大于等于次level的信息」
logging使用方法
- 使用logging提供的模块级别的函数
- 使用Logging日志系统的四大组件【module级别的封装】
| 函数 | 说明 |
|---|---|
| logging.debug(msg, *args, **kwargs) | 创建一条严重级别为DEBUG的日志记录 |
| logging.info(msg, *args, **kwargs) | 创建一条严重级别为INFO的日志记录 |
| logging.warning(msg, *args, **kwargs) | 创建一条严重级别为WARNING的日志记录 |
| logging.error(msg, *args, **kwargs) | 创建一条严重级别为ERROR的日志记录 |
| logging.critical(msg, *args, **kwargs) | 创建一条严重级别为CRITICAL的日志记录 |
| logging.log(level, *args, **kwargs) | 创建一条严重级别为level的日志记录 |
| logging.basicConfig(**kwargs) | 对root logger进行一次性配置 |
logging.basicConfig(**kwargs)函数用于指定“要记录的日志级别”、“日志格式”、“日志输出位置”、“日志文件的打开模式”等信息,其他几个都是用于记录各个级别日志的函数。
| 组件 | 说明 |
|---|---|
| loggers | 提供应用程序代码直接使用的接口 |
| handlers | 用于将日志记录发送到指定的目的位置 |
| filters | 提供更细粒度的日志过滤功能,用于决定哪些日志记录将会被输出(其它的日志记录将会被忽略) |
| formatters | 用于控制日志信息的最终输出格式 |
1 | import logging |
Q1为什么debug和info没有打印?
logging函数级别是WARNING
Q2打印的字段含义
日志级别:日志器名称:日志内容
因为logging的日志器格式basic_format为
1 | "%(levelname)s:%(name)s:(message)%s" |
hashlib.md5|hexdigest
用途简介
对二进制信息进行加密,形成一个长度固定32的数据块【摘要加密算法】,生成一个object,使用.hedigest()获取可读性信息
使用方法
1 | import hashlib |
参数
python中所有数据结构都是对象
位置参数
最基本的参数,按照位置一一对应「等同于其他语言基本参数」
def fun(para1, para2)
默认参数
等同于c++,在某些情况下提供方便
def fun(para1, para2=val)
⚠️默认参数必须在最右端
python解释器会将默认参数作为一个公共对象来对待,多次调用含有默认参数的函数,就会进行多次修改。 因此定义默认参数时一定要使用不可变对象(int、float、str、tuple)。使用可变对象语法上没错,但在逻辑上是不安全的,代码量非常大时,容易产生很难查找的bug。
可变参数
目的:「0|+输入参数个数未知时,方便函数调用,可变参数将以tuple的形式传递」
格式:*参数
Input:[]|()
关键字参数
目的:「0|+输入参数以dict的形式传递」
格式:**kw
命名关键字参数
目的:「在关键字参数前增加一个“*”」
区别:
| 关键字参数 | 命名关键字参数 | |
|---|---|---|
| 参数名字 | 任何名字都可以’key’ | 只能是*最后的key |
⚠️:如果在使用关键字参数前使用了可变参数,则关键字参数不在添加“*” ,分隔
数据流程节点
phone「client」–设备「bot」–服务器「As服务器(有八个容器)」【消息type–a_message】
Day3
CubicWeb
RabbitMP
kibana
查看日志log
release:线上端
debug:测试端
Docker
1 | # 查看正在运行的容器 |
Docker create|创建容器
我们可以从任何镜像创建容器,包括您创建的自定义镜像。
输入以下命令
1 | docker create -p 3000:80 --name exampleApp3000 yoyomooc/exampleapp |
说明:
- docker create命令用于创建一个新的镜像。
-p参数告诉 Docker 如何在容器中映射端口 80到主机操作系统。我指定容器内的端口80映射到主机操作系统中的端口3000。这与Docker中的EXPOSE命令相对应。--name参数为容器指定了一个名字,这样一来,一旦容器的已经创建了。本例中的名称是exampleApp3000,表示这个容器将响应于请求发送至主机操作系统中的端口3000。- 最后一个参数告诉Docker要使用哪个镜像作为新容器的模板。这个命令指定了
yoyomooc/exampleapp镜像,这是docker build中使用的名称。
Docker exec|进入交互
- **-d :**分离模式: 在后台运行
- **-i :**即使没有附加也保持STDIN(标准输入:client–>index) 打开
- **-t :**分配一个伪终端
docker -compose
1 | # 使用ssh链接到服务器 |
异步函数
- 同步:是指完成事务的逻辑,先执行第一个事务,如果阻塞了,会一直等待,直到这个事务完成,再执行第二个事务,顺序执行
- 异步:是和同步相对的,异步是指在处理调用这个事务的之后,不会等待这个事务的处理结果,直接处理第二个事务去了,通过状态、通知、回调来通知调用者处理结果
使用
1 | import asyncio |
DB|index|join
路由|api|token|om框架
web框架【io】
redis进行缓存
redis启动服务
1 | redis-server |
mongodb插入数据时进行校验
keyword 【await】
缺省参数|缺省
mongog封装如何实现?|语法的封装
vi 修改host|wrapper
python定时任务
信息的传递
企业微信:josn
微信:xml
python时间戳
签名算法
Day2
git基础
逻辑模式

【working】 – 【index】 – 【master|local repository】
工作区(本地dir)–add–index(缓存区)–commit – git repo|local repo【在.git文件夹里】–push–remot repo【github】
【创建|查看用户】
查看邮箱|名字
git config –global –list
【修改】
git config –global user.name “username”
git config –global user.email “email”
邮箱地址是本地git客户端的一个变量,不随git库而改变。而不同项目,设置的用户名和密码不同
git config user.name
git config user.password
git config user.email
git分为三个区,working directory–modify【add】–>index「缓存区」–commit–>改动的内容在local repository中生效,之后使用push到远程仓库中remote repository
添加文件/夹|撤销
【1.create new repository】
git init | git init new_repo[sub dir]
【2.create new file】
touch file_name
[使用git status发现此时的file_name并没有被追踪]:git status可以查看branch和提交信息以及dir中的文件是否被追踪
*【3.git add . | 】
`只用dir中touch了一个file,才可以使用git add file,将文件追踪以备commit`
使用git . | *进行commit时默认提交所有【修改】和【未被追踪】的文件,添加到git system的index区(缓存区)⚠️并不包括【删除文件】
命令选项:
-u
表示将已跟踪文件中的修改和删除的文件添加到暂存区,不包括新增加的文件,注意这些被删除的文件被加入到暂存区再被提交并推送到服务器的版本库之后这个文件就会从git系统中消失了。
-A
-A 表示将所有的已跟踪的文件的修改与删除和新增的未跟踪的文件都添加到暂存区。
*.html
添加某个文件类型到暂存区,比如所有的 .html 文件。
index/
添加整个文件夹到暂存区,比如根目录的 index 文件夹。
index/index.html
添加某个文件或者某个文件夹中的某个文件到暂存区 ,比如 index 下的 index.html 文件。
【一些自动生成的,比如日志文件,或者编译过程中创建的临时文件等,不需要纳入 Git 的管理,在这种情况下,我们可以创建一个名为 .gitignore 的文件,来跳过上传。】
【0取消|撤销文件】
git reset HEAD file_name
注意并不是在dir中del了file,而是将file从git库中删除,在working中依然存在,并且status变成了touch状态「untracked」
commit
【save changes(index) to the local repository [git **repository]**】
【1.git commit -m‘message’】
commit to local repository with message[annontation]
当我们修改了很多文件,而不想每一个都add,想commit自动来提交本地修改,我们可以使用-a标识
git commit -a -m‘changed some files’
git commit 命令的-a选项可将所有被修改或者已删除的且已经被git管理的文档提交到仓库中。
千万注意,-a不会造成新文件被提交,只能修改。
Project address
1 | git remote add origin + address |
新建repo使用git
Git global setup
1 | git config --global user.name "liuyuhao" |
Create a new repository
1 | git clone git@gitlab.zidouchat.com:liuyuhao/test.git |
Push an existing folder
1 | cd existing_folder |
Push an existing Git repository
1 | cd existing_repo |
Git push报错
【origin报错】
当使用Git进行代码push提交时,出现报错信息“fatal: 'origin' does not appear to be a git repository...”,
$ git push -u origin masterfatal: 'origin' does not appear to be a git repositoryfatal: Could not read from remote repository.
1 | 是因为远程不存在origin这个仓库名称,可以使用如下操作方法,查看远程仓库名称以及路径相关信息,可以删除错误的远程仓库名称,重新添加新的远程仓库; |
【! [rejected] master -> master (fetch first)】
报错原因:
remote repository与local repository在version方面不一样
解决方法:
【温柔型】
使用git pull将local与remote的version更新到一样
⚠️:local中的modify可能会被覆盖,最好使用git fetch(不会自动合并)
【暴力型】
git push -f
⚠️忽略版本不一致,将remote repo覆盖
1 | 同步remote的master |
【! [rejected] master -> master (pre-receive hook declined)】
【问题原因】
git push上不去的原因在于push的分支权限为protected,只用管理员或者项目的管理员指派具有权限的人才可以操作
【解决方法】
1.将所要push的内容所在的分支protected全县关闭
- 进入project的settings
- 点击protected branches,点击unprotected,将master分支权限关闭
2.新建其他分支,将project push到新的分支上,在进行merge
1 | # create new branch |
合并分支
分支指令
1 | # 查看已有的分支 |
DevOps
DevOps(Development OPerations) 是一组过程|方法|系统|的统称,用于促进开发(应用程序|软件工程)、技术运营和质量保障部门之间的沟通、协作与整合
Pip 报错
1 | “”“ |
Docker
简介
docker是一个开源的应用容器引擎,可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。
容器是完全使用沙箱机制,相互之间不会有任何接口(类似 iPhone 的 app),更重要的是容器性能开销极低。
Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。
Docker 容器通过 Docker 镜像来创建。
容器与镜像的关系类似于面向对象编程中的对象与类。
| Docker | 面向对象 |
|---|---|
| 容器 | 对象 |
| 镜像 | 类 |
常用命令
Flask框架
什么是Flask框架
Flask是一个用Python编写的Web应用程序框架。 它由 Armin Ronacher 开发,他领导一个名为Pocco的国际Python爱好者团队。 Flask基于Werkzeug WSGI工具包和Jinja2模板引擎。两者都是Pocco项目。
WSGI
Web Server Gateway Interface(Web服务器网关接口,WSGI)已被用作Python Web应用程序开发的标准。 WSGI是Web服务器和Web应用程序之间通用接口的规范。
Werkzeug
它是一个WSGI工具包,它实现了请求,响应对象和实用函数。 这使得能够在其上构建web框架。 Flask框架使用Werkzeug作为其基础之一。
jinja2
jinja2是Python的一个流行的模板引擎。Web模板系统将模板与特定数据源组合以呈现动态网页。
Flask通常被称为微框架。 它旨在保持应用程序的核心简单且可扩展。Flask没有用于数据库处理的内置抽象层,也没有形成验证支持。相反,Flask支持扩展以向应用程序添加此类功能。一些受欢迎的Flask扩展将在本教程后续章节进行讨论。
Day1
框架
紫豆助手|团小蜜
1 | flask |
venv
安装module
1 | # 此命令需要管理员权限,在linux或macos |
设置venv
1 | python -m venv my_venv_name |
激活venv
1 | cd + myvenv/bin |
退出venv
1 | deactivate |
ssh
查看ssh
进入ssh路径cd ~/.ssh
generate ssh
ssh-keygen -t rsa -C'email@email.com'
查看是否链接成功
ssh -T git@email@email.com
什么是ssh?
·SSH是一种网络协议,用于计算机之间的加密登录
·SSH的默认端口是22,也就是说,你的登录请求会送进远程主机的22端口。使用p参数,可以修改这个端口。
ssh配置完成后有一下文件
1 | Id_rsa: private key |
【什么是know_hosts】
ssh登陆远程服务器
1 | # 默认端口进入(22) |
git
任务阅读
什么是git?
Git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
Git init:初始化git
修改host
terminal中输入sudo vi /etc/hosts
1.输入本机密码后,打开hosts文件,键盘输入 i (插入),修改hosts文件后,按 esc 键退出,再按shift+:键,再输入w和q,保存退出
2.不保存退出,则按q和!键
mongohub【数据库】
参见阅读
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
homebrew【包insatll】
参见阅读Homebrew介绍和使用
Homebrew是一款Mac OS平台下的软件包管理工具,拥有安装、卸载、更新、查看、搜索等很多实用的功能。简单的一条指令,就可以实现包管理,而不用你关心各种依赖和文件路径的情况,十分方便快捷。
redis【数据库】
参见阅读Redis中文教程
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构
1 | 字符串(strings) 散列(hashes)列表(lists) 集合(sets)有序集合(sorted sets) |
新拉的项目没有环境
新拉的project没有对应的环境,也没有对应的terminal
1.首先先在setting中配置虚拟环境,增加新的环境venv
2.在全局路径中寻找requirements.txt文件,查看需要安装的包
3.在terminal中输入
pip install -r requirements.txt
安装文件的使用
如果requirements.txt不再dir里
使用:
1 | pip install -r config/requirements.txt |