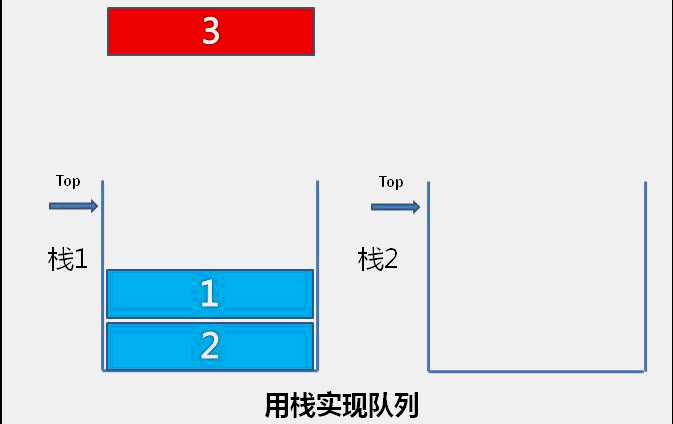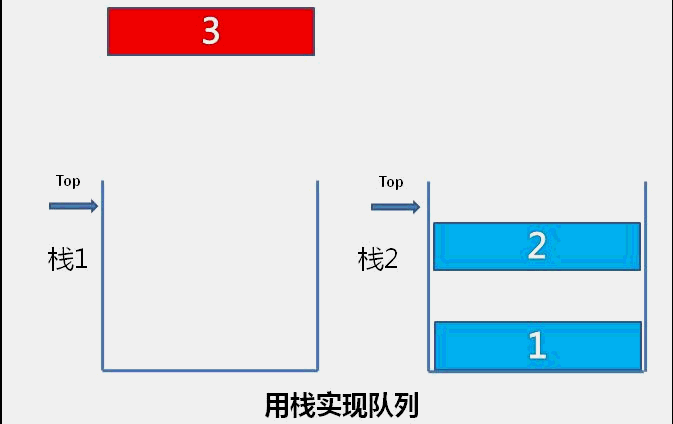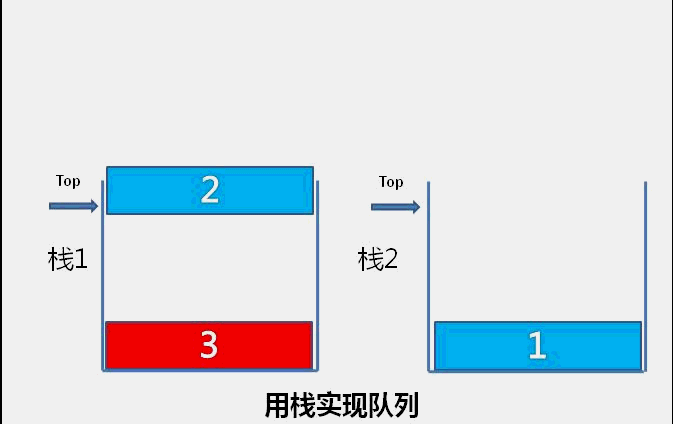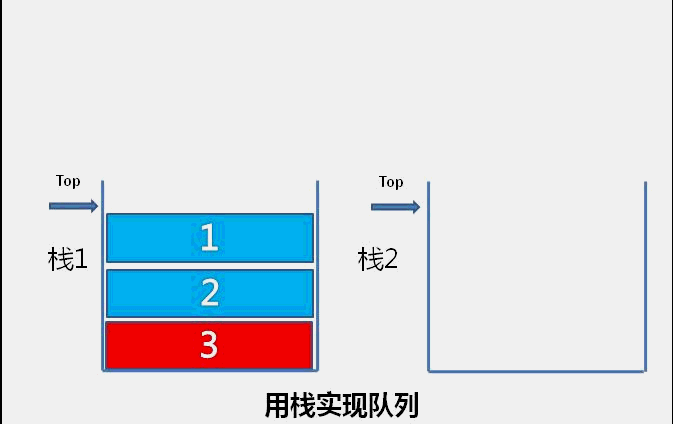
目录
[TOC]
2021/10/24
世界工业设计大会
- 数字设计、中低压电器、陶瓷行业、智能制造、生态设计五个领域
- 启动了“智能设计共享云平台”
碳达峰碳中和
- 快形成节约资源和保护环境的产业结构、生产方式、生活方式、空间格局
- 坚定不移走生态优先、绿色低碳的高质量发展道路,确保如期实现碳达峰、碳中和。
2021/10/23
世界物联网博览会
支付产业数字化
交通运输市场
加快建设统一开放的交通运输市场
网约车、共享单车、网络货运等
规范企业经营行为
2021/10/22
引导民营资本有序竞争
- 企业自我改革
- 全国工商联将继续关注相关行业企业发展状况,并协调相关部门和地方政府,切实帮助企业解决普遍遇到的创新难、融资难、维权难等突出问题。
2021/10/21
强化反垄断
绿色发展【中办|国办】
教师队伍建设
- 打造高水平专业化教师队伍,持续推进教师队伍建设综合改革
2021/10/20
煤炭领域
营造公平竞争税收环境
- 推出首批包括10项内容的税务行政处罚“首违不罚”清单
2021/10/19
反垄断
金融领域反垄断和反不正当竞争整治
数字技术
- 互联网
- 大数据
- 云计算
- 人工智能
- 区块链
- 发展数字经济,实施网络强国战略和国家大数据战略
要推动数字经济和实体经济融合发展
把握数字化、网络化、智能化方向,推动制造业、服务业、农业等产业数字化
2021/10/18
全过程民主
2021/10/17
生物多样性
- 本质上讲是同碳中和 碳达峰一样, 中国要实现数字化转型, 产能的形式也将转型
2021/10/16
数字化转型
2021/10/13
[经济]新能源汽车
新能源汽车充电难
充电桩不足
原因
- 充电模式不足
- 充电技术限制
- 新能源基础设施建设慢于新能源销售
- 峰值堵塞[国庆]
- 交流电充电速度慢于直流电
趋势
- 企业自建
- 政策要从“补车”向“补桩”转变
- 发展多种充电模式
- 互联网+充电桩+换电模式[共享电车电源]
2021/10/12
美原油期货价超80$
2021/10/11
中小企业
2021/10/08
电力煤炭
- 鼓励地方对小微企业和个体工商户用电实行阶段性优惠
- 大型风电、光伏基地建设
- 遏制“两高”项目
- 将市场交易电价上下浮动范围由分别不超过10%、15%,调整为原则上均不超过20%
2021/10/07
共同富裕
- 变优势资源为特色资产,让村民成为股东
- 集资众筹发展
2021/10/03
人才
2021/10/02
国家战略人才力量
[经济]限电
东北限电
原因
- 技术原因|生产少供应多
- 居民用电10%|工业用电|服务业用电
- 居民拉闸停电[责任事故]
- 煤炭价格上涨
趋势
- 短期煤炭价格上涨导致电的上游产能成本变大
- 煤的短缺导致上游产能降低
[经济]猪肉价格
猪肉价格腰斩

原因
趋势
- 未来四五月价格还会持续下跌
- 养殖亏损大概一头500
- 饲料价格上涨
- 八月全国亏损面打到52.5%
- 双节”春节|元旦”猪肉价格还是平稳或下跌
- 短期猪肉反弹存在, 但产能的的压力并不会影响上游生产
- 收储|保价
2021/9/26
央视融媒体产业投资基金
- 首个以媒体融合为主题的国家级产业投资基金
- 上海正式成立
- 总规模100亿元,首期规模37亿元
- 投向5G、超高清、人工智能、云计算、区块链
小微企业
工行、农行、交通银行以及多家股份制银行、城商
- 9月30日起
- 减免小微企业和个体工商户的银行账户开户手续费、转账汇款手续费、电子银行服务费等收费
中国银联
- 9月30日起三年内
- 小微企业卡、单位结算卡跨行转账汇款交易实行银联手续费减免
[经济]PPI|CPI
概念
CPI:下游产业「原材料」居民消费水平(消费端To:C)
PPI:生产端上游产业==>大宗商品的上涨(生产端To:B)
消费者物价指数(CPI)是反映与居民生活有关的消费品及服务价格水平的变动情况的重要宏观经济指标,也是宏观经济分析与决策以及国民经济核算的重要指标。
生产价格指数共调查9大类商品:①燃料、动力类;②有色金属类;③有色金属材料类;④化工原料类;⑤木材及纸浆类;⑥建材类:钢材、木材、水泥;⑦农副产品类;⑧纺织原料类。⑨工控产品
大宗商品
CPI|PPI剪刀差
- CPI:服务消费|食品–>疫情
- PPI:大宗商品的价格恢复需求关系–>影响中小企生产成本
- 帮扶中小企业
- 大宗商品包够稳价
2021/9/24
企业融资
- 缓解中小微企业融资难、融资贵问题
- 新兴产业、制造业高质量发展
2021/9/23
十七届深圳文博会
- 重点展示5G、大数据、云计算等技术
- 文博会官网和微信小程序“文博会+”同时搭建“云上文博会”
碳排放
- 碳监测评估试点
- 唐山、太原、上海等16个城市以及火电、钢铁、石油天然气开采等五个重点行业
- 温室气体试点监测、推进减污和降碳协同增效
国债
2021/9/22
生育率
碳中和
- 9月22日清华大学正式成立碳中和研究院
- 中优势资源加快突破碳中和领域关键核心技术
- 低碳发电与动力
- 新型电力系统
- 零碳交通
- 零碳建筑
- 工业深度减排
- 减污降碳协同增效
- CCUS与碳汇
- 气候变化与碳中和战略
基本认识
- 碳排放
人类生产经营活动过程中向外界排放温室气体(二氧化碳、甲烷、氧化亚氮、氢氟碳化物、全氟碳化物和六氟化硫等)的过程。
- 碳达峰
广义来说,碳达峰是指某一个时点,二氧化碳的排放不再增长达到峰值,之后逐步回落。根据世界资源研究所的介绍,碳达峰是一个过程,即碳排放首先进入平台期并可以在一定范围内波动,之后进入平稳下降阶段。
- 碳中和
碳中和是指企业、团体或个人测算在一定时间内直接或间接产生的温室气体排放总量,然后通过植树造林、节能减排等形式,抵消自身产生的二氧化碳排放量,实现二氧化碳“零排放”。
4.碳汇(Carbon Sink)
一般是指从空气中清除二氧化碳的过程、活动、机制。主要是指森林吸收并储存二氧化碳的多少,或者说是森林吸收并储存二氧化碳的能力。
- 碳捕集利用与封存(CCUS)
Carbon capture utilization storage
碳捕集利用与封存简称CCUS,是把生产过程中排放的二氧化碳进行捕获提纯,继而投入到新的生产过程中进行循环再利用或封存的一种技术。其中,碳捕集是指将大型发电厂、钢铁厂、水泥厂等排放源产生的二氧化碳收集起来,并用各种方法储存,以避免其排放到大气中。
- 碳排放权
碳排放权,即核证减排量(Certification Emission Reduction,CER)的由来。2005 年,伴随《京都议定书》生效,碳排放权成为国际商品。碳排放权交易的标的称为“核证减排量(CER)”。
碳排放权配置一级二级市场
一级市场:一般由各省发改委进行配额初始发放的市场,分为无偿分配和有偿分配。
有偿分配附带有竞价机制,遵循配额有偿、同权同价的原则,以封闭式竞价的方式进行。
**二级市场: **是控排企业或投资机构进行交易的市场。
- 碳交易
把二氧化碳排放权作为一种商品,买方通过向卖方支付一定金额从而获得一定数量的二氧化碳排放权,从而形成了二氧化碳排放权的交易。
碳交易市场是由政府通过对能耗企业的控制排放而人为制造的市场。通常情况下,政府确定一个碳排放总额,并根据一定规则将碳排放配额分配至企业。如果未来企业排放高于配额,需要到市场上购买配额。与此同时,部分企业通过采用节能减排技术,最终碳排放低于其获得的配额,则可以通过碳交易市场出售多余配额。双方一般通过碳排放交易所进行交易。
- 碳排放配额、自愿减排量(CCER)
按照碳交易的分类,目前我国碳交易市场有两类基础产品,一类为政府分配给企业的碳排放配额,另一类为核证自愿减排量(CCER)。
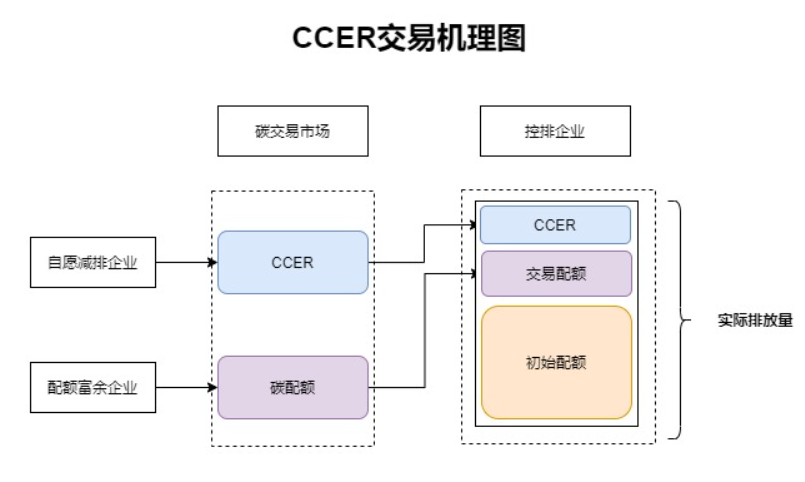
2020 年 12 月发布的《碳排放权交易管理办法(试行)》中指出,CCER 是指对我国境内可再生能源、林业碳汇、甲烷利用等项目的温室气体减排效果进行量化核证,并在国家温室气体自愿减排交易注册登记系统中登记的温室气体减排量。
第一类,配额交易,是政府为完成控排目标采用的一种政策手段,即在一定的空间和时间内,将该控排目标转化为碳排放配额并分配给下级政府和企业,若企业实际碳排放量小于政府分配的配额,则企业可以通过交易多余碳配额,来实现碳配额在不同企业的合理分配,最终以相对较低的成本实现控排目标。
第二类,作为补充,在配额市场之外引入自愿减排市场交易,即 CCER 交易。CCER 交易指控排企业向实施“碳抵消”活动的企业购买可用于抵消自身碳排的核证量。
“碳抵消”是指用于减少温室气体排放源或增加温室气体吸收汇,用来实现补偿或抵消其他排放源产生温室气体排放的活动,即控排企业的碳排放可用非控排企业使用清洁能源减少温室气体排放或增加碳汇来抵消。抵消信用由通过特定减排项目的实施得到减排量后进行签发,项目包括可再生能源项目、森林碳汇项目等。
碳市场按照 1:1 的比例给予 CCER 替代碳排放配额,即 1 个 CCER 等同于 1 个配额,可以抵消 1 吨二氧化碳当量的排放,《碳排放权交易管理办法(试行)》规定重点排放单位每年可以使用国家核证自愿减排量抵销碳排放配额的清缴,抵消比例不得超过应清缴碳排放配额的 5%。
新型农业
- 农旅结合
- 高标准农田建设,平整土地、整合田块,让农田更适合机械化作业
- 农业机械化、数字化
知识产权
- 2021—2035
- 2025年,知识产权强国建设取得明显成效,知识产权保护更加严格
- 2035年,我国知识产权综合竞争力跻身世界前列
2021/9/21
马克思主义
- 加强新时代马克思主义学院建设
- 马列毛-邓-三代表-科学发展观-习近平新时代
2021/9/18
经济趋势
- 9月18日银保监
- 保险资金投向碳中和、碳达峰和绿色发展相关产业资金规模超过9000亿元
- 交通、能源、环保、水利、市政
2021/9/16
十四五
经济趋势
- 高技术制造业增长14.9%
- 高技术服务业增长35.2%
经济调控
- 3.65万亿地方政府专项债券
- 3000亿元支小再贷款额度政策
- 实体经济发展
- 地方法人银行向小微企业和个体工商户发放贷款
2021/9/15
2021中关村论坛
新能源汽车
- 2021世界新能源汽车大会今天(9月15日)在海口开幕
- 新能源汽车在技术、产业、政策等方面的创新经验与发展趋势
塑料产业
- 2025年,塑料制品生产、流通、消费、回收利用、末端处置全链条治理成效更加显著,白色污染得到有效遏制的目标。
2021/9/14
中办|国办加强网络文明建设
- 中共中央办公厅|国务院办公厅
- 加强重点理论网站
- 深化公众账号、直播带货、知识问答等领域不文明问题治理
2021/9/12
大宗商品|天然气
价格
价格暴涨
- �大宗商品分为生产国和消费国
- 供需关系
- 天然气作为清洁能源==>碳中和大环境
- 疫情因素和天气自然环境的因素, 导致天然气的需求大于供给
价格背景
- 液化和管道运输, 所涉及的技术设备成本不一, 天然气并不想石油这类大宗商品, 其价格根据具体的形势具有一定的波动
- 天然气市场供需关系失衡的原因复杂
- 能源型大宗商品价格波动具有一定的时间特征
- 大宗商品的价格不仅受市场的影响更受政治经济的影响, 即其不仅拥有商品属性还包括国家战略
供需错配
- 中国能源使用天然气由去年的4%占比到8%未来随着碳中和的进一步要求, 天然气等新能源的投资比将持续攀升
- 2020年中国天然气消费同比增加6.9%对外依赖程度为43%
- 天然气价格适度市场化是趋势
中国政策
- 抓中间, 放两端|抓住设备运输主体, 放开上游供给和下游销售, 促进市场自由竞争, 激发市场活力
- 改革的红利和市场发展的红利
生态保护补偿制度
- 调动各方参与生态保护积极性
- 强化激励与硬化约束协
- 2025年与经济社会发展状况相适应的生态保护补偿制度基本完备
- 2035年适应新时代生态文明建设要求的生态保护补偿制度基本定型
推行企业活力
21届投洽会
- 第二十一届中国国际投资贸易洽谈会
- 福建厦门
- “一带一路”“碳中和”
- 项目512个,3920亿
2021/9/11
东盟博览会
中国—东盟中心是一个政府间国际组织,旨在促进中国和东盟在贸易、投资、旅游、教育和文化领域的合作。中心总部设在北京
- 广西南宁3000亿
- 涵盖电子信息、数字经济、节能环保
- 智慧农业规模60亿
2021/9/10
企业贷款
人民银行新增3000亿元支小再贷款额度
- 贷款平均利率在5.5%左右
- 小微企业和个体工商户贷款
2021/9/9
8月市场
- 消费价格同比上涨0.8%,涨幅比上月回落0.2个百分点
食品
- 份鲜菜和鸡蛋 上涨8.6%和8.4%
- 猪肉价格下降1.4%
生活服务
- 居住、生活用品及服务价格环比上涨0.1%
- 育文化娱乐、医疗保健价格均持平
- 交通通信、衣着价格环比下降
大宗商品
2021/9/6
香港澳门发展
2021/9/5
服贸会
2021/9/3
服贸会
北京证券交易所
强化金融服务功能,找准金融服务重点,以服务实体经济、服务人民生活为本。
供给侧结构性改革的着眼点是提升劳动力、土地和资本等生产要素的配置效率,着眼于科技创新及其产业化,通过金融结构的调整,通过金融产品和金融服务的创新,提高劳动力、土地和资本的配置效益,推进技术进步和体制机制创新,助力发挥市场在资源配置中的决定性作用,助力提升潜在增长率
以新三板精选层【以企业利润和影响为依据,将企业划分为基础层、创新层、精选层】为基础,推动完善中国特色的资本市场体系,在新三板前期改革探索的基础上,建设一个为创新型中小企业量身打造的交易所
新股上市首日将不设涨跌幅限制,自次日起涨跌幅限制为30%。设立北京证券交易所将形成北京证券交易所与沪深交易所、区域性股权市场错位发展和互联互通的格局,也有助于完善资本市场对中小企业的金融支持体系的建设。
2021/9/2
文娱领域治理
2021/9/1
国务院常务会
- 加大对市场主体特别是中小微企业纾困帮扶力度
- 强化国家助学贷款增加3000亿贷款
- 稳增长、保就业
- 农产品质量安全法
养老托育建设
- 2021年中央预算内投资70亿元支持养老托育服务体系建设
棉花收购
- 安排500亿元信贷资金用于支持2021—2022年度棉花收购
2021/9/2
文娱领域综合治理
- 流量至上|“饭圈”乱象|违法失德
- 反对唯流量论|抵制泛娱乐化
2021/9/3
服务贸易交易会
数字开启未来,服务促进发展
- 打造数字贸易示范区
- 支持中小企业创新发展
- 设立北京证券交易所
目前中国有五个证券交易所:
- 上海证券交易所
- 深圳证券交易所
- 香港交易所
- 台湾证券交易所
—————分割线—————
2021/7/8
医改
央视网消息(新闻联播):国务院新闻办公室今天(7月8日)举行国务院政策例行吹风会,介绍2021年深化医药卫生体制改革重点工作任务有关情况。进一步推广三明市医改经验,加快推进医疗、医保、医药联动改革。促进优质医疗资源均衡布局,完善分级诊疗体系。选择上海、江苏、浙江等11个省份为医改试点地区,统筹推进省域内各级各类公立医院探索高质量发展的实施路径和支撑体系,加快形成符合实际、可推广、可复制、可持续的经验和模式。
2021/7/11
新能源
<宁德时代–电池厂商>
li电池–>(新能源汽车)电动汽车
到2023年全球电动汽车对动力电池的需求达406GWH而动力电池供应预计为335GWH
缺口约18%
到2025年这一缺口将扩大到约40%
导致这一情况的主要原因是市场需求大于供给
- 新能源汽车供给多
- 电池厂商存在竞争
- 电池原材料不足(原材料价格上升)
- 固态电池大规模应用预计2030年
7月1日六氟磷酸锂的市场报价已达33万元/吨较6月30日5000元/吨今年以来涨幅约200%成为动力电池材料中的“涨价王”
今年1-6月全国新能源汽车累计销量达120.6万辆同比201.5%预计今年总销量将超过240万辆
2021/7/12
暑期托管
- 观望–>托管内容
- 不学习新课,学生自主学习
- 体育锻炼
- 假期托管和补习班分割开来,假期依然是假期,而不是第三学期
- 【目的】:降低占用暑期时间成本
羊肉价格降低
猪肉30->14==销量上升【肉类优先级:猪肉>羊牛】
羊肉50->40==销量减缓
山东德州【羊肉养殖】
鳗鱼出口量增多
【福建福清】
产能增加一倍15day->25day
内+50%, 外+35%
- 近5年我国年均出口烤鮼39000吨到42000吨
- 其中出口日本15000吨到18000吨
- 出口美国7000吨到8000吨
- 出口俄罗斯1000吨到3000吨
市场:东北:up:
3-6月采购 鱼苗目前无法人工繁育
2021/7/14
保障性租赁住房
公租房:国家投资建设用于,城市住房困难的低收入家庭
保障性租赁住房:市场建设,谁投资谁所有,保障新市民和青年人
保障性:
- 买不起商品房但有一定经济收入
- 青年团队(大学生、高学历人士)
- 通勤需要
- 企业用房/工业园区用房,土地性质不属于城市用房
2021/7/15
直播打赏
- 虚假打赏
- 直播PK
- 打赏产业链
- 互联网金融=属于工信部?=✖=>依然是具有金融属性的,依然归金融监管
- 服务交易or商品交易==交流or带货
- 加入互联网之后不再拥有金融属性?
直播打赏-肯蒙拐骗-线上好感-线下经济往来//-诱导消费【左手到右手】
经济机构参与直播活动
如何认定主播(MCN经济机构)的一个商业性质
- 直播不是一个个人[监管对个人起的作用微小]是一个法人实体而不是个人实体
- 要将直播账户(个人)对象看作一个法人实体
- 部分网络主播和平台利用“套路”诱导网民消费
- 追逐经济利益可以,但内容和输出的意识形态需要监管【利益驱动】
- 治乱象不能只靠行业自律要加大处罚力度
打赏模式问题不应该靠禁止解决,应该规范化
打赏并不是简单的你情我愿的交流互动,而是新形成的商业模式和消费文化,是一种具有一定规模和完整产业链的商业模式
基于优质内容的流量变现才是真正的可持续
【MCN】
MCN(Multi-Channel Network),即多频道网络 [3] ,一种多频道网络的产品形态,是一种新的网红经济运作模式。这种模式将不同类型和内容的PGC(专业生产内容)联合起来,在资本的有力支持下,保障内容的持续输出,从而最终实现商业的稳定变现。 [1]
MCN模式源于国外成熟的网红经济运作,其本质是一个多频道网络的产品形态,将PGC(专业内容生产)内容联合起来,在资本的有力支持下,保障内容的持续输出,从而最终实现商业的稳定变现
美国通胀,全球买单
【CPI】Consumer Price Index
是一个反映居民家庭一般所购买的消费品和服务项目价格水平变动情况的宏观经济指标。它是在特定时段内度量一组代表性消费商品及服务项目的价格水平随时间而变动的相对数,是用来反映居民家庭购买消费商品及服务的价格水平的变动情况,是一个月内商品和服务零售价变动系数。
居民消费价格统计调查的是社会产品和服务项目的最终价格,一方面同人民群众的生活密切相关,同时在整个国民经济价格体系中也具有重要的地位。它是进行经济分析和决策、价格总水平监测和调控及国民经济核算的重要指标。其变动率在一定程度上反映了通货膨胀或紧缩的程度。一般来讲,物价全面地、变化对比、持续地上涨就被认为发生了通货膨胀。
基本功能
1、度量通货膨胀(通货紧缩)。CPI是度量通货膨胀的一个重要指标。通货膨胀是物价水平普遍而持续的上升。CPI的高低可以在一定水平上说明通货膨胀的严重程度;
2、国民经济核算。在国民经济核算中,需要各种价格指数。如消费者价格指数(CPI)、生产者价格指数(PPI)以及GDP平减指数,对GDP进行核算,从而剔除价格因素的影响。
3、契约指数化调整。例如在薪资报酬谈判中,因为雇员希望薪资(名义)增长能相等或高于CPI,希望名义薪资会随CPI的升高自动调整等。其调整之时机通常于通货膨胀发生之后,幅度较实际通货膨胀率为低。
4、反映货币购买力变动 :货币购买力是指单位货币能够购买到的消费品和服务的数量。消费者物价指数上涨,货币购买力则下降;反之则上升。消费者物价指数的倒数就是货币购买力指数。
5、反映对职工实际工资的影响 :消费者物价指数的提高意味着实际工资的减少,消费者物价指数的下降意味着实际工资的提高。因此,可利用消费者物价指数将名义工资转化为实际工资。
6、CPI对股市的影响:一般情况下,物价上涨,股价上涨;物价下跌,股价也下跌。
CPI涨势最高:二手车市场
2021/7/17
暑假旅游市场
- 建党一百周年红色旅游
- 去年疫情旅游低迷
- 乡村旅游(农民旅游)
- 毕业旅游
- 自驾车游
文旅融合科技赋能扩大供给主客共享
2021/7/20
校园小卖铺
- 校内垄断
- 天价小卖部背后是市场的扭曲
- 垄断-定价权-偷税漏税
- 食品安全
2021/7/21
油价跌 股价跌
- 全球股市下跌
- 能源/航空/原油/工业/金融下跌厉害
直接原因:通货膨胀(美联储开放货币);疫情(导火索)
根本原因:石油
- 整体经济形式随着疫情逐渐上涨
- 原油生产自8月份开始增产
- 未来油价将持续变化
2021/7/22
人口发展决定
《决定》围绕“降低生育、养育、教育成本”指出,要严格落实产假、哺乳假等制度。
《决定》明确提倡适龄婚育、优生优育。取消社会抚养费,清理和废止相关处罚规定。
浦东新区
技术研发
2021/7/23
保障性租赁住房
实际出发加快发展保障性租赁住房,坚定不移全面落实房地产长效机制
2021/7/24
减轻作业负担和校外培训
- 实现作业全面减压
- 不得校外有偿补课
- 不得开展义务教育有关课程校外补习
- 不得超前教育
要全面压减作业总量和时长,减轻学生过重作业负担,建立作业校内公示制度,严禁给家长布置或变相布置作业,严禁要求家长检查、批改作业,杜绝重复性、惩罚性作业。
不得利用课后服务时间讲新课。依法依规严肃查处教师校外有偿补课行为,直至撤销教师资格。
各地不再审批新的面向义务教育阶段学生的学科类校外培训机构,现有学科类培训机构统一登记为非营利性机构。对原备案的线上学科类培训机构,改为审批制。依法依规严肃查处不具备相应资质条件、未经审批多址开展培训的校外培训机构。学科类培训机构一律不得上市融资,严禁资本化运作。已违规的,要进行清理整治。严禁超标超前培训,严禁非学科类培训机构从事学科类培训,严禁提供境外教育课程。严格控制资本过度涌入培训机构,聘请在境内的外籍人员要符合国家有关规定,严禁聘请在境外的外籍人员开展培训活动。
要大力提升教育教学质量,确保学生在校内学足学好,逐步提高优质普通高中招生指标分配到区域内初中的比例,规范普通高中招生秩序,杜绝违规招生、恶性竞争。
要强化配套治理,提升支撑保障能力,中央有关部门、地方各级党委和政府要加强校外培训广告管理,确保主流媒体、新媒体、公共场所、居民区各类广告牌和网络平台等不刊登、不播发校外培训广告。
要扎实做好试点探索,确保治理工作稳妥推进,精心组织实施,务求取得实效。
东京奥运会
- 门票费–>900亿日元==>10+亿日元
- 日本经济复苏–>沉迷
- 日本基建
2021/7/25
开放贸易
1.港口开放
青岛港今年新增的第13条外贸航线
青岛港,上海港、宁波舟山港、广州港新增航线超80条
海南自由贸易港法实施
浦东新区成为更高水平改革开放开路先锋
2.一带一路
5G
工业和信息化部负责人今天(7月25日)
- 2023年要实现5G在大型工业企业渗透率达到35%
- 每重点行业5G示范应用标杆数达到100个
- 5G物联网终端用户数年均增长率达到200%三大指标
拉美|墨西哥
拉美和加勒比国家共同体第21次外长会议24日在墨西哥首都墨西哥城召开。墨西哥总统洛佩斯在会前发表讲话,呼吁拉美国家团结起来与美国对话,反对干涉、制裁、排他主义和封锁,建立类似欧盟的全新地区合作和争议调停机制。
2021/7/27
十四五
- 增强中心城市和城市群等经济发展优势区域的经济和人口承载能力
人口老龄化
- 探索渐进式延迟退休年龄政策,科学开发低龄老年人力资源,挖掘老年人口红利。
- 降低生育、养育、教育成本,改变生育意愿下降趋势。
2021/7/28
就业
截至2020年末,在全国7.5亿就业人员中,第三产业就业人员占到47.7%
第一产业
是指农、林、牧、渔业(不含农、林、牧、渔服务业)
第二产业
是指采矿业(不含开采辅助活动),制造业(不含金属制品、机械和设备修理业),电力、热力、燃气及水生产和供应业,建筑业。
第三产业
服务业
交通运输、仓储和邮政业,信息传输、计算机服务和软件业,批发和零售业,住宿和餐饮业,金融业,房地产业,租赁和商务服务业,科学研究、技术服务和地质勘查业,水利、环境和公共设施管理业,居民服务和其他服务业,教育,卫生、社会保障和社会福利业,文化、体育和娱乐业,公共管理和社会组织,国际组织等行业。
加强科研
- 坚持创新的核心地位
- 破除不符合规律的经费管理规定
- 精简预算科目
- 加大科研人员激励
加强猪肉储备
为确保猪肉供应
稳定财政、金融、用地等长效性支持政策
建立生猪生产逆周期调控机制
5G
- 基站突破91万座
- 电气机械、计算机、通信电子设备制造业
- 江西|赣江首个5G产业园带动当地电子信息产业增长40%
规范人脸识别
- 宾馆、商场等经营场所滥用
- 物业服务企业不得强制将人脸识别作为出入小区唯一验证方式;
- 信息处理者处理未成年人人脸信息,必须征得监护人的单独同意;
- 应用程序不得强制索取非必要个人信息。
中|越|欧联程运输
- 衣服、背包等越南物品从广西凭祥火车站启程。中越–>中国–>中欧班前往比利时
- 比海运节约一周时间
- 中越–>中欧首次联程运输
上海集资
- 上海|60个项目|58.5亿美元
- 生物医药|集成电路|人工智能
外卖小哥权益
【灵活就业群体|劳务派遣制度】
市场性具有外部性,市场上的问题并不仅仅是市场上的问题,也不能仅仅靠着市场自我调节,需要一定的外部力量对市场进行不断的完善
属性:灵活就业,就业保障无法得到实现
时间约束:算法虽然服务了消费者的体验也对外卖员也有一种约束,但本质上还要进行人性化的改良,不能让用时算法成为评价外卖员的标准
- 放宽配送时间
- 平台社保
- 平台|外卖员|消费者
- 外卖员闯红灯|情绪崩溃本质上是建立在剥削关系上的劳动交易,是平台利用其优势地位对劳动者的压榨,问题的结果是外卖员的各种交通问题,但从本质上的根源必须整顿平台落实平台责任
- 平台将成本和风险转移给了劳动者
2021/7/29
促进扩大就业
2021/7/30
疫情防控|经济发展
并就统筹推进居民收入增长、帮助城镇困难群众脱困解困、精准帮扶中小微企业、加强绿色金融体系建设、完善国家未来人口发展战略、构建全民免疫屏障、一体化规划碳达峰碳中和、加强国家实验室建设统筹布局、提升东北振兴战略政策效能、推动海南自由贸易港建设等提出意见建议。
2021/7/31
国企改革【三年行动】
小微企业贷款
金融服务将围绕改善经济社会薄弱环节,不断改善小微企业金融服务
京津冀
让一批原本打算在北京新增的非首都功能设在了京外。20多所北京市属学校、医院向京郊转移,3000家一般制造业企业、1000个批发市场和物流中心向河北、天津等地疏解,北京经济结构得到调整优化,科技、信息、文化等高精尖产业新设市场主体占比从2013年的40%上升至2020年的60%。从今年起,将以在京部委所属高校、医院和央企总部为重点,分期分批推动相关非首都功能向雄安新区疏解。
保障租赁住房
- 国家开发银行、农发行、建行等银行也明确要加大信贷支持力度
- 今年10月底以前,各城市人民政府要确定“十四五”期间保障性租赁住房的建设目标和年度建设计划,并向社会公布
黑土地保护
“十四五”期间,将完成1亿亩黑土地保护利用任务。预计到“十四五”末,黑土地耕地质量明显提升,土壤有机质含量平均/提高10%以上
2021/8/1
高层民用建筑消防安全管理规定
明确禁止在高层民用建筑公共门厅、疏散走道、楼梯间、安全出口停放电动自行车或为电动自行车充电,违者拒不改正的将处以最高一万元的罚款。未及时修复外墙外保温系统等其他6类违规行为也将面临处罚。
上海|国际消费中心城市
2021/8/2
宅基地
加强农民宅基地合法权益保障。
禁止侵犯农民依法取得的宅基地权益
禁止违背农民意愿强制流转宅基地
禁止违法收回农民依法取得的宅基地
禁止以退出宅基地作为农民进城落户的条件
禁止强迫农民搬迁退出宅基地
规范集体经营性建设用地入市
耕地保护
强化对耕地的保护,针对耕地“非农化”、“非粮化“
落实最严格的耕地保护制度。严格控制耕地转为林地、草地、园地等其他农用地
娱乐圈
- 片面追逐商业利益
- 过度娱乐化炒作
- 传播畸形偶像文化
方式:加强网上涉明星信息规范、强化账号管理、完善黑产打击机制、进一步压实网络综艺节目制作和播出机构主体责任等方式
数字经济
2021/8/4
全民健身
各运动项目参与人数持续提升,经常参加体育锻炼人数比例达到38.5%,县(市、区)、乡镇(街道)、行政村(社区)三级公共健身设施和社区15分钟健身圈实现全覆盖,每千人拥有社会体育指导员2.16名,带动全国体育产业总规模达到5万亿元。
共建共享
浙江将基本建成学前教育、公共卫生、养老照料、体育健身等“15分钟公共服务圈”;人均预期寿命超过80岁,基本养老触手可及、优质养老全面推进,基本实现人的全生命周期公共服务优质共享。
国际贸易趋势
商务部今天(8月3日)公布的数据显示,上半年我国服务进出口总额23774.4亿元,同比增长6.7%;其中6月当月,我国服务进出口总额4392亿元,环比增长17.6%,同比增长22.5%,保持良好增长态势。
免费退票
中国国家铁路集团今天(8月3日)推出免费退票措施。自即时起,旅客在车站、12306网站等各渠道办理今天24时前已购各次列车有效车票退票时,均不收取退票手续费,购买的铁路乘意险可以一同办理。
2021/8/5
新能源需求
猪周期
- 2021上半年,猪肉价格持续下跌
- 7月触底反弹28->13
- 5G物联养殖,淘汰低产能(控制养殖成本6元以内)
分时电价
- 分时电价(按用电时区)
- 控制峰谷用电和低谷用电,峰值-低谷差3|4倍
- 放大差价,用价格引导削峰
- 【根本目的】发展清洁能源
低谷–新能源蓄能|高峰–新能源方能(4|5倍)
拉大差价–>将更多的资金转向新能源
疫情|旅游业
数字人民币
==|=>数字加密货币|支付及结算|互联互通
2021年开始实行
数字人民币生活化
央行推动|国家信用|法币性质
双网交易
区块链+监控
节省5/1000手续费
奶茶行业
2021/8/6
创新|中小企业
辽宁|优化产业|数字化
行业
- 停车场信息
- 鞍钢集团|炼钢
- 采矿|石化|冶金|建材
病毒溯源1-3
黑龙江|高校签约
2021/8/7
网红经济
- ����网红经济已经产业化
- 流量时代规范化
- 加大平台责任
- 加大优质内容视频短视频输出
本质上讲,由于目前社会压力和家庭压力这两座大山,导致大多数青年长期处于精神紧绷和劳累过度,这种事实导致了青年人不可能进行有效的长期阅读和思考,短视频|流量|低俗娱乐的冲击宛如精神鸦片成为了青年人消遣的手段,解决无底线的炒作,从本质上还需要解放青年人身上所背负的两座大山,只要这个最本质的现实压力没解决,流量时代的无底线炒作又会换一层外衣重来。
城镇供水
目的:破解城镇供水定价和调价的难题
- �三种供水阶梯「居民|非居民|特种」
- 对企业用水采用激励与约束并举
2021/8/8
全民健身
新农业
债券市场信用评级
2021/8/9
西部联合演习
集资炒房|信用评级
- 防止信贷资金流入房地产
- 房子不是金融, 应该限制其金融属性
- 将房子证券化
- 信托机构
- 金融贷款:为了辗转资金,让资金流进小微企业
- 银行金融贷流向房地产是集资炒房的最大助手
- 银行对贷款信用人信用的评级很大程度上以不动产作为信用评级依据
2021/8/10
改善农村人居环境
2021/8/11
扩大内需|创新
双减
东京奥运会
- 奥运目前仍然是一种高度线上化的商业模型
- 奥运是经济发展的催化剂并不是主导作用
金价回调
下跌原因
美国就业率下降(10%)–>经济复苏
经济好转–>黄金储备需求降低
韩国黄金交易所市场规模六年增长24倍
交易特点
- 黄金投资边缘化|未来还会持续下跌
- 黄金消费同比上涨70%恢复2020年水平
- 黄金价2008-2013下跌
- 实物供需对于金价价格作用甚微
- 消费属性和投资属性, 黄金的投资属性大于消费属性
- 黄金作为投资品, 具有避险属性
2021/8/12
十四五
- 互联网+人工智能+大数据==>实体经济融合
- 高新技术服务于实体经济
全面建成小康社会
网联汽车
2021/8/13
新能源汽车
前七个月我国新能源汽车销量超去年全年水平
今年1—7月,我国新能源汽车销量为147.8万辆,同比增长2倍,超过2020年全年水平,较2019年同期增长1倍。其中,7月当月,新能源汽车销量为27.1万辆,同比增长1.6倍。
四川盆地
位于四川盆地的中国石化西南石油局中江气田
2021/8/14
企查查-企业工商信息查询系统_查企业_查老板_查风险就上企查查!上海|浦东
2021/8/15
造船实业
- 中国船舶工业集团有限公司
- 2021/8/15股价18.300
- 环渤海、长江口再到珠江口,我国已经形成三大造船基地
- 我国新承接船舶订单量占全球总量的51%,月均接单量达到637万载重吨,是同期造船完工量的1.8倍。
2021/8/16
国务院常务会议
2021/8/17
共同富裕
关键信息基础设施安全保护
- 重点行业和领域重要网络设施、信息系统属于关键信息基础设施
国家发展改革委员会
- 下半年扩大投资
- 稳定制造业投资
- 绿色低碳行业
- 大宗商品保价稳价
- 我国分别投放了两批次国家储备铜铝锌,两轮储备投放基本实现了预期目标,缓解了部分行业企业的原材料成本压力
大宗商品
大宗商品:价格波动较大的商品, 一般实行垄断价格或计划价格
特点:
1、供需量大
2、原产地
3、原材料
4、国家统一限价
5、影响国计民生
6、国家具有一定储备
大宗商品(Commodities)是指可进入流通领域,但非零售环节,具有商品属性并用于工农业生产与消费使用的大批量买卖的物质商品。在金融投资市场,大宗商品指同质化、可交易、被广泛作为工业基础原材料的商品,如原油、有色金属、钢铁、农产品、铁矿石、煤炭等。包括3个类别,即能源商品、基础原材料和农副产品。
上海自贸区
今天(8月17日),上海自贸区临港新片区42个项目集中签约,涵盖集成电路、高端装备制造、新型国际贸易、跨境金融服务等领域,投资金额近280亿元。
2021/8/18
科研经费
新就业劳动保护
2021/8/19
科研经费
2021/8/20
主席令
- 免去陈宝国教育部部长
- 《个人信息保护法》
- 《检察官法》
- 《法律援助法》
- 《医师法》
- 《兵役法》
- 《人口与计划生育法》
农村快递体系
「农产品寄的出, 消费品进的去」
- 2025年,实现乡乡有网点、村村有服务,农产品运得出、消费品进得去,便民惠民寄递服务基本覆盖。
- 邮政体系作用、健全末端共同配送体系、优化协同发展体系、构建冷链寄递体系等4个体系建设
钢铁产业
今天(8月20日),鞍钢重组本钢正式启动。辽宁省国资委将所持本钢51%股权无偿划转给鞍钢,本钢成为鞍钢的控股子企业。重组后,鞍钢粗钢产能将达到6300万吨,营业收入将达到3000亿元,产能位居国内第二、世界第三。
卖房|房地产
问题
- 收房-样板房不对
- 消息不对称
原因
房子是商品, 不是投资品
解决
- 展示样板间->交付样板间[保留三月]
- 住房质量保证书|具有法律效益
2021/8/21
小巨人企业
超六成企业>>
- 核心基础零部件和元器件
- 先进基础工艺
- 关键基础材料
- 产业技术基础“四基”领域
九成集中在制造业领域
2021/8/22
深圳建设中国特色社会主义先行示范区
- 国家将外国高端人才确认函权限下放至深圳
- 数字经济产业{深圳电子信息制造业产值2.2万亿元,约占全国1/5}
- 宝安区[获批国家新型工业化产业示范基地],龙华区[获批广东省工业互联网示范基地]

重庆
内蒙古
- 优化投资结构
- 呼和浩特机场建设–>预计2023年竣工
双减政策落地
目的
- 首轮试点城市-北京
- 教育均等
- 教育责任归位
- 打压校外超前培训
- 教育资源流动
- 减轻学生负担|家长焦虑
经济影响
监管校外培训问题, 根本上应该从教育目的|学习目的入手, 将问题的结果当做问题本分分析解决不了问题
2021/8/23
数字经济
上海数字经济产业,促进经贸合作新生态
2021/8/24
振兴东北
RECP(区域全面经济伙伴)
区域全面经济伙伴关系(Regional Comprehensive Economic Partnership,RCEP),由东盟十国于2012年发起,邀请中国、日本、韩国、澳大利亚、新西兰、印度共同参加(“10+6”),通过削减关税及非关税壁垒,建立16国统一市场的自由贸易协定。
乡村振兴
中国人民银行加大支持乡村振兴力度,对存量扶贫再贷款进行展期,最长可展期至2025年,加大支农、支小再贷款力度,同时,重点做好粮食安全金融服务、支持新型农业经营主体发展等工作。
2021/8/25
2021(中国)亚欧商品贸易博览会开幕
首次采用线上方式举办,通过视频、VR等多种形式展示,
2021中国国际智能产业博览会
碳交易|碳排放
- 利用区块链实现碳排放可追溯交易化
- 重庆举办
- 人工智能|大数据项目成功落地
在此带动下,今年上半年,重庆市数字产业增加值超过1000亿元,增速达到35.4%
2021/8/26
两高项目|碳排放
“十四五”开局之年,也是碳中和碳达峰工作推进的开端
劳动法
人力资源社会保障部、最高人民法院今天(8月26日)联合发布十件超时加班劳动人事争议典型案例,包括超时加班的责任认定、加班发生工伤责任认定等方面,要求用人单位遵守国家工时制度,及时纠正违法行为,有效保障劳动者休息权及劳动报酬权。
2021/8/27
十四五就业促进规划
解决
- 就业结构性矛盾,是指人力资源供给与岗位需求之间的不匹配。
- 就业质量稳步提升
- 创业带动就业动能持续释放
- 风险应对能力显著增强
国际服务贸易交易会
“数字开启未来,服务促进发展”
清朗行动
大宗商品|铜铝锌
国家发展改革委、国家粮食和物资储备局今天(8月27日)宣布,投放第三批国家储备铜铝锌共计15万吨。本次投放将向中小企业倾斜,以切实缓解企业生产经营压力,引导市场价格回归合理区间。
2021/8/29
2021年服贸会
- 2021年中国电子商务大会
- 服务贸易开放发展新趋势高峰论坛
- 跨国公司视角下的服务贸易便利化高峰论坛
- 数字贸易发展趋势和前言高峰论坛
- 2021香山旅游峰会暨世界旅游合作与发展大会
主要交流内容
- 数字新生态
- 振兴世界旅游–>疫情
- 等开展交流,对全球服务贸易战略性、结构性问题进行深入研讨。
- 在物流采购、粮食供应链、生态环境等行业成立国际公共采购联盟、粮食供应链联盟、生态可持续发展联盟
2021/8/30
就业矛盾
结构性就业矛盾成为就业的主要矛盾|人力资源供给与岗位需求之间的不匹配。|
方法
- 优化就业创业环境
- 稳定重点群体就业
- 提高劳动报酬
- 改善就业服务
- 保障劳动权益
人口老龄化、人工智能技术应用等对劳动力供需产生较大影响的长期性趋势
未成年沉迷网络游戏
- 严格限制向未成年人提供网络游戏服务的时间
- 5.6.7-1h
- 实名注册
2021年服贸会
数字服务专区展
学校考试管理
提出大幅压减考试次数等要求
2021/8/31
2021世界5G大会在京开幕
今天(8月31日),以“5G深耕,共融共生”为主题的2021世界5G大会在北京开幕。1500余位业界专家、学者和企业家以线上或线下的方式参会。数据显示,截至7月底,我国已建设开通99.3万个5G基站,5G手机终端连接数超过3.92亿。