[Class魔法]
–iter–
–str/repr/format–
string/represent
其实这正是反应了两者的区别,如果简单理解,这两个函数都是将一个实例转成字符串。但是不同的是,两者的使用场景不同,其中__str__更加侧重展示。所以当我们print输出给用户或者使用str函数进行类型转化的时候,Python都会默认优先调用__str__函数。而__repr__更侧重于这个实例的报告,除了实例当中的内容之外,我们往往还会附上它的类相关的信息,因为这些内容是给开发者看的。所以当我们在交互式窗口输出的时候,它会优先调用__repr__。
1 | def __str__(self): |
到这里还没有结束,在有些场景当中,对于同一个对象我们可能有多种输出的格式。比如点,在有些场景下我们可能希望输出(x, y),有时候我们又希望输出x: 3, y: 4,可能还有些场景当中,我们希望输出<x, y>。
我们针对这么多场景,如果各自实现不同的接口会非常麻烦。这个时候利用__format__当中的这个参数,就可以大大简化这个过程,我们来看代码:
.format()配合__format__使用,减少api的设置,同时可是设置不同的输出格式
__str__:侧重展示
__repr__:侧重报告,可以展示类的相关信息给开发者
1 | # dictionary |
–contains–
1 | Class A: |
[查看信息]
加密Class属性
使用__getattribute__进行加密
为了避免从实列中使用dir()或者__dict__access属性,可以使用__getattribute__:
1 | class Student: |
- 使用
__getattr__只能对private attribute 和不存在的属性有效,当访问私有属性和不存在的属性时,return__getattr__里的内容
使用__getitem_ _进行单个key加密
access attributes use [key'string']
instance[‘attr_1’]
1 | class Student: |
访问Class属性
访问属性的方法常见的有四种
1 | __getattribute__() # default 优先级最高 |
查看class属性
1 | class Student: |
–len–
Python对象含有的xxxx__这样定义的属性和方法,都有特殊用途,比如__len()。
在Python中,如果你调用len()函数试图获取一个对象的长度,实际上,在len()函数内部,它自动去调用该对象的__len__()方法。
–dict–
1 | instance.__dict__() |
1 | __dict__ <==difference==> dic() |
__dict__与dir()的区别:
- dir()是一个函数,返回的是list;
__dict__是一个字典,键为属性名,值为属性值;- dir()用来寻找一个对象的所有属性,包括
__dict__中的属性,__dict__是dir()的子集; - 并不是所有对象都拥有
__dict__属性。许多内建类型就[没有__dict__属性,如list,此时就需要用dir()来列出对象的所有属性。
__dict__是用来存储对象属性的一个字典,其键为属性名,值为属性的值。
注意:
实例的
__dict__仅存储与该实例相关的实例属性,正是因为实例的
__dict__属性,每个实例的实例属性才会互不影响。类的
__dict__存储所有实例共享的变量和函数(类属性,方法等),类的__dict__并不包含其父类的属性。
结论:
dir()函数会自动寻找一个对象的所有属性,包括__dict__中的属性。
__dict__是dir()的子集,dir()包含__dict__中的属性。
dir()是Python提供的一个API函数,dir()函数会自动寻找一个对象的所有属性(包括从父类中继承的属性)。
一个实例的__dict__属性仅仅是那个实例的实例属性的集合,并不包含该实例的所有有效属性。所以如果想获取一个对象所有有效属性,应使用dir()。
dir()
dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法dir(),该方法将被调用。如果参数不包含dir(),该方法将最大限度地收集参数信息。
Get与Attr
如果在类中定义了getitem()方法,那么他的实例对象(假设为P)就可以这样P[key]取值。当实例对象做P[key]运算时,就会调用类中的getitem()方法。
1 | __getitem__(self,key):返回键对应的值。 |
python的一切数据都是对象,包括函数、基本数据类型、自定义数据类型等等,这其中最复杂的就是对象内部存储的数据结构(引用),包括类属性、数据描述符、实例属性及非数据描述符,不仅它们的优先级不一样,而且它们的回调函数也存在很大的差异,这也是本文需要阐述的地方。
如果以前有过Javascript的编程经验,初上Python肯定会对“.”运算符与“[]”之间的差异难以理解,它们不仅不能替换,而且完全不相关,如下:
1 | mem = {'username': 'yiifaa'} |
1. 为实例添加“[]”运算符支持
这也是“_ getattribute_”与“_ getitem_”的最大差异,示例如下:
“_ getattribute_”只适用于所有的“.”运算符;
“_ getitem_”只适用于所有的“[]”运算符;
1 | class Employee(object): |
通过实现“_ getitem_”回调接口,现在Employee可以支持“[]”运算符。
- 避免语法错误错误
在对象属性的调用中,如果没有调用了不存在的属性,则Python解释器会报错,如下:
1 | Traceback (most recent call last): |
通过覆盖实现“_ getattr_”回调接口可以解决此问题,如下:
1 | # 直接返回空对象,将此方法添加到类Employee的声明中 |
那“_ getattribute_”与“_ getattr_”的最大差异在于:
- 无论调用对象的什么属性,包括不存在的属性,都会首先调用“_ getattribute_”方法;
- 只有找不到对象的属性时,才会调用“_ getattr_”方法;
3. 将对象作为数据描述符
这就是“_ get_”的作用了,将整个对象都作为数据描述符,但是请记住,要想_ get_作为数据描述符,那么此对象只能作为类属性,作为实例属性则无效,如下:
1 | class Dept(object): |
4. 获取对象属性数据的三种方法
对象的所有属性都存储在“_ dict_”中(启用了“_ slots_”除外),所以访问对象的属性数据有如下三种方法:
1 | print yiifaa.name |
结论
每个以“__ get”为前缀的方法都是获取对象内部数据的钩子,但名称不一样,用途也存在较大的差异,只有在实践中理解它们,才能真正掌握它们的用法。
1 | class Examp(object): |
总结:
“__getattribute__”与“__getattr__”的最大差异在于:
1.无论调用对象的什么属性,包括不存在的属性,都会首先调用“__getattribute__”方法;
2.只有找不到对象的属性时,才会调用“__getattr__”方法;
仅希望以某种特殊的方式使用少数属性,而其他属性则按照普通属性操作。这些普通属性不会触发任何特殊代码,也不会因为遍历方法代码而浪费时间。在这些情况下,您可以对属性使用描述符
每次访问descriptor(即实现了__get__的类),都会先经过__get__函数。
需要注意的是,当使用类访问不存在的变量是,不会经过__getattr__函数。而descriptor不存在此问题,只是把instance标识为none而已
[快捷操作]
sorted/sort
- sort排序,可以对iteration属性的数据结构进行操作
- list\dict等时最常见的操作形式
- .sort(key=lambda var: expression)是常见的组合形式
对列表进行排序
1 | a = [1, 5, 3, 6, 2] |
对list中的iteration进行排序,以tuple为例[list nested tuple]
假如a是一个由元组构成的列表,我们需要用到参数key,也就是关键词,同时使用lambda;
在下实例中x表示列表中的一个元素(tuple),在这里,表示一个元组,x只是临时起的一个名字,你可以使用任意的名字;
x[0]表示元组里的第一个元素,当然第二个元素就是x[1];所以这句命令的意思就是按照列表中第一个元素排序
1 | # sort the element in the list based on the first element(tuple_0, tuple_1) |
1 | # 以tuple中的第二个元素进行排序 |
可以使用sort进行倒序排序sorted()相当于[::-1]
1 | a = [1, 5, 3, 6, 2] |
map()【映射】
–【函数,参数值】
接受迭代函数和迭代对象(list,tuple,dictionary)
返回迭代对象(return 物理地址)
可以根据输入的迭代参数对return的值进行可视化展示譬如:
1 | x = list(range(1, 11)) |
通俗的讲是接受函数和对应的参数(可迭代的),并返回最小参数长度所对应的函数的运算值的物理存储地址
1 | map(function, iterable, ...) |
它需要两个必须的参数:
function- 针对每一个迭代调用的函数iterable- 支持迭代的一个或者多个对象。在 Python 中大部分内建对象,例如 lists, dictionaries, 和 tuples 都是可迭代的。
在 Python 3 中,map()返回一个与传入可迭代对象大小一样的 map 对象。在 Python 2中,这个函数返回一个列表 list。
其中function可以使用lambda关键词替换
你可以将任意多的可迭代对象传递给map()函数。回调函数接受的必填输入参数的数量,必须和可迭代对象的数量一致。
下面的例子显示如何在两个列表上执行元素级别的操作:
1 | def multiply(x, y): |
同样的代码,使用 lambda 函数,会像这样:
1 | a = [1, 4, 6] |
当提供多个可迭代对象时,返回对象的数量大小和最短的迭代对象的数量一致。
让我们看看一个例子,当可迭代对象的长度不一致时:
1 | a = [1, 4, 6] |
超过的元素 (7 和 8 )被忽略了。
1 | [2, 12, 30] |
三、总结
Python 的 map()函数作用于一个可迭代对象,使用一个函数,并且将函数应用于这个可迭代对象的每一个元素。
lambda【匿名函数】
–【变量:表达式】
本质上讲为匿名函数,接受变量和表达式
使用语法:
1 | lambda argument_list:expersion |
- argument_list:变量列表
- expression:表达式
lambda 常常和map()函数结合使用
get()
字典中的get操作
return: 返回字典中key对应value值,如果没有就return None, 而get函数可以将没有的key进行操作
dict.get(key, default=None)
- key – 字典中要查找的键。
- default – 如果指定键的值不存在时,返回该默认值。
返回指定键的值,如果键不在字典中返回默认值 None 或者设置的默认值。
split()
return list
Python split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
string.split(sep=’’, maxsplit=num)
- sep–>分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等默认情况下不显示sep,直接输入需要splitstr即可。
- maxsplit– >分割次数。默认为 -1, 即分隔所有。
1 | temp = input().split(sep='**', maxsplit=-1) |
print()
print(objectes, sep=’’, end=’\n’, flush=False, file=sys.stdout)
- objects:需要输出的对象
- sep:以什么间隔default:space
- end:以什么结尾default:\n
- file:是要写入的对象,其中sys.stdout为python的标准输出
- flush:输出是否被缓存通常决定于 file,但如果 flush 关键字参数为 True,流会被强制刷新
1 | import time |
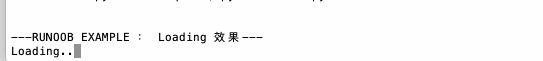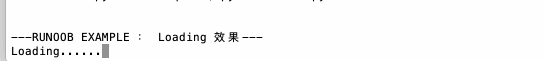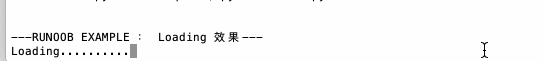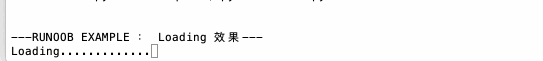
ljust/center
对于需要填充的字符串一种快捷操作
ljust(width, char)–>左对齐–>右填充
rjust(width, char)–>右对齐–>左tianchong
center(width, char)–>中间对齐–>两边填充
1
2
3
4
5
6
7
8
9
10str = ' 123 '
print(len(str))
print(str.ljust(10, '*'))
print(str.rjust(10, '*'))
print(str.center(10, '*'))
>>
7
123 ***
*** 123
* 123 **
‘’.join()
将list中的element转化成string,其中”char”中的符号为间隔填充符,但是如果list中只有数字,将不能直接转化,需要遍历列表,将列表中的内容转化成字符串:
1 | alist = [1, 2, 3] |
int()
int()可以快速的实现进制的转换
int(num, base)
1 | print(int(num, base=n)) |
eval()
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
以下是 eval() 方法的语法:
1 | eval(expression[, globals[, locals]]) |
参数
- expression – 表达式。
- globals – 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals – 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
返回值
返回表达式计算结果。
1 | >>>x = 7 |
bin()
bin() 返回一个整数 int 或者长整数 long int 的二进制表示。
1 | print(bin(10)) |
.format()
Python2.6 开始,新增了一种格式化字符串的函数 **str.format()**,它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
1 | >>>"{} {}".format("hello", "world") |
[sys]
.stdin.readline()
.stdin.read()
1 | line = sys.stdin.readline() # 读取一行(包括换行符) |
Python中常用到的两种标准化输入方式:分别sys.stdin和input,两者使用方式大致相同,但是总的来说sys.stdin使用方式更加多样化一些,下面就例子说明两者之间的使用差别。
- python3中使用sys.stdin.readline()可以实现标准输入,其中默认输入的格式是字符串,如果是int,float类型则需要强制转换。
[特殊方法]
.isxxx()[string]
is判断函数为一种判断函数,根据规定字符串判断是否符合结果返回True或者False
主要判断如下:
1 | isdecimal():判断给定字符串是否全为数字 |
count()
可以统计在list\tuple\string中某个element\string出现的次数
- list.count(element)
- string.count(string, strat, end)
| 参数 | 描述 |
|---|---|
| value | 必需。字符串。要检索的字符串。 |
| start | 可选。整数。开始检索的位置。默认是 0。 |
| end | 可选。整数。结束检索的位置。默认是字符串的结尾。 |
strip()
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
1 | str1 = "00000003210Runoob01230000000"; |
一、默认用法:去除空格
- str.strip() : 去除字符串两边的空格
- str.lstrip() : 去除字符串左边的空格
- str.rstrip() : 去除字符串右边的空格
注:此处的空格包含’\n’, ‘\r’, ‘\t’, ‘ ‘
1 | a=' abc de a 1' |
二、去除指定字符
- str.strip(‘do’) :去除字符串两端指定的字符
- str.lstrip(‘do’) :用于去除左边指定的字符
- str.rstrip(‘do’) :用于去除右边指定的字符
三个函数都可以传入一个参数(这里以’do’为例),指定要去除的首尾字符,编译器会去除两端所有相应的字符,直到没有匹配的字符。
指定的字符表示的一种组合,例如'do'表示'dd','do','od','oo','ddd','ooo'等
1 | dodo = "say hello say boy saaayaaas" |
处理异常
1 | try: |
该格式中,[] 括起来的部分可以使用,也可以省略。其中各部分的含义如下:
- (Error1, Error2,…) 、(Error3, Error4,…):其中,Error1、Error2、Error3 和 Error4 都是具体的异常类型。显然,一个 except 块可以同时处理多种异常。
- [as e]:作为可选参数,表示给异常类型起一个别名 e,这样做的好处是方便在 except 块中调用异常类型(后续会用到)。
- [Exception]:作为可选参数,可以代指程序可能发生的所有异常情况,其通常用在最后一个 except 块。
try except 语句的执行流程如下:
- 首先执行 try 中的代码块,如果执行过程中出现异常,系统会自动生成一个异常类型,并将该异常提交给 Python 解释器,此过程称为捕获异常。
- 当 Python 解释器收到异常对象时,会寻找能处理该异常对象的 except 块,如果找到合适的 except 块,则把该异常对象交给该 except 块处理,这个过程被称为处理异常。如果 Python 解释器找不到处理异常的 except 块,则程序运行终止,Python 解释器也将退出。
通过前面的学习,我们已经可以捕获程序中可能发生的异常,并对其进行处理。但是,由于一个 except 可以同时处理多个异常,那么我们如何知道当前处理的到底是哪种异常呢?
其实,每种异常类型都提供了如下几个属性和方法,通过调用它们,就可以获取当前处理异常类型的相关信息:
- args:返回异常的错误编号和描述字符串;
- str(e):返回异常信息,但不包括异常信息的类型;
- repr(e):返回较全的异常信息,包括异常信息的类型。
举个例子:
1 | try: |
输出结果为:
(‘division by zero’,)
division by zero
ZeroDivisionError(‘division by zero’,)
isdigit()
str.isdigit()
- 不需要任何参数
- 返回True False
- 检测字符串是否只有数字组成
ord()–chr()
ord():返回对应的ASCII值
1 | print(ord('A')) |
chr():返回对应的 Unicode 数值
1 | print(chr(65)) |
slots
1 | __slots__ |
- 节省memory。在上面的例子里,如果我们看看
bar和slotted_bar就看到,slotted_bar并没有__dict__而bar却含有__dict__。__slots__正是通过避免定义动态的数据结构__dict__来实现对memory的节省,大约能节省30%的memory - .access attributes更快。事实上,在CPython的实现里,
__slots__是一个静态数据结构(static),里面存的是value references,比__dict__更快
此处要注意一点,正因为__slots__是static的,定义了__slots__之后,你将不能创造新的attribute
如果你想获得__slots__的好处并且可以创造新的attribute,你可以将__dict__作为__slots__中的一个element(见下面code):
什么情况下该使用__slots__?
当你事先知道class的attributes的时候,建议使用slots来节省memory以及获得更快的attribute access。
注意不应当把防止创造__slots__之外的新属性作为使用__slots__的原因,可以使用decorators以及getters,setters来实现attributes control。
使用__slots__的特殊注意事项
- 当inherit from a slotted class,那么子类自动变成slotted并且获得parent class的slots;子类可以定义新的elements加入到inherited slots里。slots里面的每一个element,只能在inheritance里面定义一次(否则就是redundant)
- 在multiple inheritance(比如mixedins)里,如果两个parents定义了不同的nonempty __slots__,那么python会报错。这个时候,就进一步factor out 母类的slots。
if–name–==’–main–’:
1 | if __name__ == '__main__': |
当你在写 .py 的时候
一般是以两种方式存在的
- 1、作为脚本直接运行

- 2、作为模块给别人导入
的代码在被执行的时候,Python 解释器会先去读取你的 Python 代码然后定义一些全局的内置变量,而我们常常写的这个 –name–就是其中的变量之一,如果判断出 –name– 的值是 –main–就说明这里是程序入口,而非被别的 py 文件 import
所以你的 .py 可以作为自己的脚本运行,在 –main– 中做一些测试,或者本身程序的运行,当然你也可以使用你的 .py 作为模块给别人使用,给别人提供一些便利,为了不让别人一导入你的模块就直接运行整个脚本那么使用 **if –name– == ‘–main–’**其中的代码就不会在被 import 时被执行。
yield<==>send==>next
首先,如果你还没有对yield有个初步分认识,那么你先把yield看做“return”,这个是直观的,它首先是个return,普通的return是什么意思,就是在程序中返回某个值,返回之后程序就不再往下运行了。看做return之后再把它看做一个是生成器(generator)的一部分(带yield的函数才是真正的迭代器),好了,如果你对这些不明白的话,那先把yield看做return,然后直接看下面的程序,你就会明白yield的全部意思了:
1 | def foo(): |
我直接解释代码运行顺序,相当于代码单步调试:
程序开始执行以后,因为foo函数中有yield关键字,所以foo函数并不会真的执行,而是先得到一个生成器g(相当于一个对象)
直到调用next方法,foo函数正式开始执行,先执行foo函数中的print方法,然后进入while循环
程序遇到yield关键字,然后把yield想想成return,return了一个4之后,程序停止,并没有执行赋值给res操作,此时next(g)语句执行完成,所以输出的前两行(第一个是while上面的print的结果,第二个是return出的结果)是执行print(next(g))的结果,
程序执行print(“*”20),输出20个
又开始执行下面的print(next(g)),这个时候和上面那个差不多,不过不同的是,这个时候是从刚才那个next程序停止的地方开始执行的,也就是要执行res的赋值操作,这时候要注意,这个时候赋值操作的右边是没有值的(因为刚才那个是return出去了,并没有给赋值操作的左边传参数),所以这个时候res赋值是None,所以接着下面的输出就是res:None,
程序会继续在while里执行,又一次碰到yield,这个时候同样return 出4,然后程序停止,print函数输出的4就是这次return出的4.
到这里你可能就明白yield和return的关系和区别了,带yield的函数是一个生成器,而不是一个函数了,这个生成器有一个函数就是next函数,next就相当于“下一步”生成哪个数,这一次的next开始的地方是接着上一次的next停止的地方执行的,所以调用next的时候,生成器并不会从foo函数的开始执行,只是接着上一步停止的地方开始,然后遇到yield后,return出要生成的数,此步就结束。
1 | def foo(): |
先大致说一下send函数的概念:此时你应该注意到上面那个的紫色的字,还有上面那个res的值为什么是None,这个变成了7,到底为什么,这是因为,send是发送一个参数给res的,因为上面讲到,return的时候,并没有把4赋值给res,下次执行的时候只好继续执行赋值操作,只好赋值为None了,而如果用send的话,开始执行的时候,先接着上一次(return 4之后)执行,先把7赋值给了res,然后执行next的作用,遇见下一回的yield,return出结果后结束。
程序执行g.send(7),程序会从yield关键字那一行继续向下运行,send会把7这个值赋值给res变量
由于send方法中包含next()方法,所以程序会继续向下运行执行print方法,然后再次进入while循环
程序执行再次遇到yield关键字,yield会返回后面的值后,程序再次暂停,直到再次调用next方法或send方法。
简要理解:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后开始。
[关键字]
not
not用于bool值的运算,常见的用法如下:
- not与逻辑判断句if连用。
- 判断元素是否在列表或者字典中
特殊的:
1 | for i, v in enumerate(result): |
【:star:】:对于习惯于使用if not x这种写法的pythoner,必须清楚x等于None, False, 空字符串””, 0, 空列表[], 空字典{}, 空元组()时对你的判断没有影响才行。 而对于if x is not None和if not x is None写法,很明显前者更清晰,而后者有可能使读者误解为if (not x) is None,因此推荐前者,同时这也是谷歌推荐的风格 结论: if x is not None是最好的写法,清晰,不会出现错误,以后坚持使用这种写法。
【:star:】 使用if not x这种写法的前提是:必须清楚x等于None, False, 空字符串””, 0, 空列表[], 空字典{}, 空元组()时对你的判断没有影响才行。
在python中 None, False, 空字符串"", 0, 空列表[], 空字典{}, 空元组()都相当于False
global
Python变量的作用域一共有4种,分别是:
- L (Local) 局部作用域
- E (Enclosing) 闭包函数外的函数中
- G (Global) 全局作用域
- B (Built-in) 内建作用域 以 L –> E –> G –>B 的规则查找,即:在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内建中找。
1 | # instance 1 |
1 | # instance 2 |
1 | # instance 3 |
1 | # instance 4 |
结论:
实例一: 即使变量同名,优先引用的是局部变量。
实例二 & 实例三: 闭包的情况,如果内部函数没有局部变量,则会优先引用闭包的环境变量。
实例四: 引用全局变量。
对于全局变量来说,既然能函数体内直接引用,并且程序没有报错,那为什么还要用 global 关键字?
现在在重新声明一个 func_c 函数,并且对这个 x 进行加 1 的操作。你觉得会打印什么结果?
1 | # instance 5 |
可以看到已经报错了 ,UnboundLocalError,错误代码第 9 行 x = x+1。
在这个例子中设置的 x=5 属于全局变量,而在函数内部中没有对 x 的定义。
根据 Python 访问局部变量和全局变量的规则:当搜索一个变量的时候,Python 先从局部作用域开始搜索,如果在局部作用域没有找到那个变量,那样 Python 就会像上面的案例中介绍的作用域范围逐层寻找。
最终在全局变量中找这个变量,如果找不到则抛出 UnboundLocalError 异常。
但你会想,明明已经在全局变量中找到同名变量了,怎么还是报错?
因为内部函数有引用外部函数的同名变量或者全局变量,并且对这个变量有修改的时候,此时 Python 会认为它是一个局部变量,而函数中并没有 x 的定义和赋值,所以报错。
global 关键字为解决此问题而生,在函数 func_c中,显示地告诉解释器 x 为全局变量,然后会在函数外面寻找 x 的定义,执行完 x = x + 1 后,x 依然是全局变量。
1 | # instance 6 |
yield
简要理解:yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后开始
- 它首先是个
return:在程序中返回某个值,返回之后程序就不再往下运行了。 - 之后是生成器(generator)的一部分(带yield的函数才是真正的迭代器)
1 | def foo(): |
1.程序开始执行以后,因为foo函数中有yield关键字,所以foo函数并不会真的执行,而是先得到一个生成器g(相当于一个对象)
2.直到调用next方法,foo函数正式开始执行,进入while循环
3.程序遇到yield关键字,然后把yield想想成return,return了一个4之后,程序停止,并没有执行赋值给res操作,此时next(g)语句执行完成,所以输出4(return出的结果)是执行print(next(g))的结果(–|1|)
4.程序执行print(“*”20),输出20个
5.又开始执行下面的print(next(g)),这个时候和上面那个差不多,不过不同的是,这个时候是从刚才那个next程序停止的地方开始执行的,也就是要执行res的赋值操作,这时候要注意,这个时候赋值操作的右边是没有值的(因为刚才那个是return出去了,并没有给赋值操作的左边传参数),所以这个时候res赋值是None,所以接着下面的输出就是res:None
6.程序会继续在while里执行,又一次碰到yield,这个时候同样return 出4,然后程序停止,print函数输出的4就是这次return出的4.
带yield的函数是一个生成器,而不是一个函数了这个生成器有一个函数就是next函数,next就相当于“下一步”生成哪个数,这一次的next开始的地方是接着上一次的next停止的地方执行的,所以调用next的时候,生成器并不会从foo函数的开始执行,只是接着上一步停止的地方开始,然后遇到yield后,return出要生成的数,此步就结束。
1 | def foo(): |
raise
raise 关键字用于引发异常。
您可以定义要引发的错误类型以及要向用户打印的文本。
1 | x = "hello" |