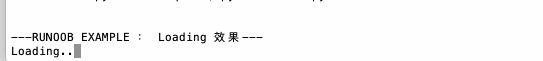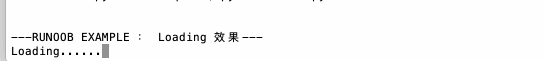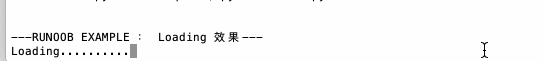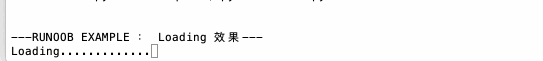import sys whileTrue: line = sys.stdin.readline() ifnot line: break n = int(line) d = {} for i inrange(n): d[int(sys.stdin.readline())]=1 l = list(d.keys()) l.sort() for i in l: print(i)
deffactor(n): flag = True for i inrange(2, int(n**0.5+1)): if n % i == 0: print(i, end=" ") flag = False factor(int(n/i)) break if flag: print(n, end=" ") factor(int(input()))
num = int(input()) # 共输入几组key-val dic = {} for i inrange(num): line = input().split() key = int(line[0]) value = int(line[1]) dic[key] = dic.get(key,0) + value for key insorted(dic): print(key, dic.get(key))
9M提取不重复的整数
数组/位运算/哈希
描述
输入一个int型整数,按照从右向左的阅读顺序,返回一个不含重复数字的新的整数。
保证输入的整数最后一位不是0。
输入描述:
输入一个int型整数
输出描述:
按照从右向左的阅读顺序,返回一个不含重复数字的新的整数
1 2 3 4 5 6 7 8
temp = input() ans = list(temp)[::-1] anss = [] for item in ans: if item notin anss: anss.append(item) print(''.join('%s' %i for i in anss))
:m:’’.join()将list中的元素转化成string,如果list中有number,则需要使用格式''.join('%s' %i for i in list)
words = [] num = int(input()) for i inrange(num): word = input() words.append(word) words.sort() # 不能直接遍历words.sort(),否则返回None for item in words: print(item)
whileTrue: try: line = input() a = 0 b = 0 c = 0 d = 0 flag = True for i in line: if i.isdigit(): a = 1 elif i.islower(): b = 1 elif i.isupper(): c = 1 else: d = 1 for j inrange(len(line) - 3): if line.count(line[j:j + 3]) > 1: flag = False iflen(line) > 8and (a + b + c + d) >= 3and flag: print("OK") else: print("NG") except: break
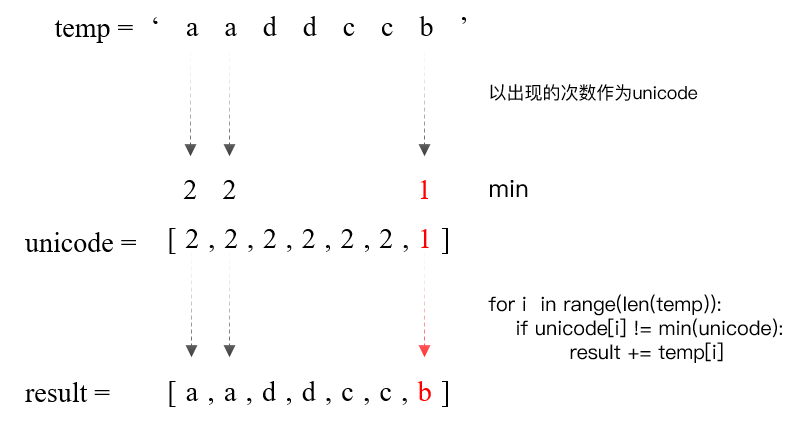
# method1 whileTrue: try: temp = input() unicode = [] result = '' for i inrange(len(temp)): unicode.append(temp.count(temp[i])) for i inrange(len(temp)): ifmin(unicode) != unicode[i]: result += temp[i] print(result) except: break
方法二:使用hash table来存贮每个ele出现的次数
1 2
a = min(dict.values) returndict中最小的value
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
whileTrue: try: temp = input() unicode = {} for char in temp: unicode[char] = unicode.get(char, 0) + 1
min_val = min(unicode.values())
i = 0 for key in unicode: if unicode[key] == min_val: i += 1 temp = temp.replace(key, '') print(temp.strip()) except: break
try: whileTrue: l1=input().split()[1:] l2=list(map(int,input().split()))[1:] l2=list(set(l2)) l2.sort() res=[] l2=list(map(str,l2)) for i inrange(len(l2)): ans =[] for j inrange(len(l1)): if l2[i] in l1[j]: ans.append(str(j)) ans.append(l1[j]) if ans: res.append(l2[i]) res.append(str(len(ans)//2)) res +=ans ss = str(len(res))+' '+' '.join(res) print(ss) except: pass
defsolution1(alist, target): iflen(alist) == 0: return [] for index, val inenumerate(alist): for i inrange(index+1, len(alist)): if alist[i] + val == target: return [index, i] time = 3340ms memory = 14.9MB
defsolution2(alist, target): hashmap = {} for index, val inenumerate(alist): if target - val in hashmap: return hashmap[target-val], index hashmap[val] = index time = 40ms memory = 15.8MB
chars = "acbcd" b = set() length = len(chars) for j inrange(length): for i inrange(length): if i+j < length: b.add(chars[i:i+j]) print(b)
temp = [] for ele in b: if ele == ele[::-1] and ele != '': temp.append(ele) print(temp) >> {'', 'b', 'cb', 'cbc', 'acbc', 'a', 'c', 'acb', 'bc', 'ac'} ['b', 'cbc', 'a', 'c']
def__format__(self, code): # use dictionary[key].format(message==>/dictionary_varable/attribuate) return formats[code].format(p=self) p = point(3, 4) # call-->{:key}.format(instance) print('the point is {:normal}'.format(p)) print('the point is {:point}'.format(p)) print('the point is {:prot}'.format(p)) >> the point is x: 3, y: 4 the point is (3, 4) the point is <3, 4>
–contains–
1 2 3 4 5 6 7 8 9 10 11 12 13
Class A: def__init__(self): self.item = 10 def__contains__(self, item): if item is self.item: returnTrue else: returnFalse a = A() print(a.__contains__(5)) >> False
def__getitem__(self, key): if key in ['__name', '__score', 'age']: return'the class has the attributes.' else: return'no access' temp = Student() print(temp['age']) print(temp['ee']) >> the classhastheattribute. noaccess
a = [1, 5, 3, 6, 2] print(sorted(a)) >> [1, 2, 3, 5, 6] sorted(iteration) --> return a new iteration iteration.sort() --> return None --> operation on old original data
# sort the element in the list based on the first element(tuple_0, tuple_1) # 以tuple中的第一个元素进行排序 a = [('b', 4), ('a', 0), ('c', 2), ('d', 3)] print(sorted(a, key=lambda x: x[0]))
当inherit from a slotted class,那么子类自动变成slotted并且获得parent class的slots;子类可以定义新的elements加入到inherited slots里。slots里面的每一个element,只能在inheritance里面定义一次(否则就是redundant)
在multiple inheritance(比如mixedins)里,如果两个parents定义了不同的nonempty __slots__,那么python会报错。这个时候,就进一步factor out 母类的slots。
for i, v inenumerate(result): ifnot v: result[i] = temp[0] temp.pop(0) return''.join(result)
【:star:】:对于习惯于使用if not x这种写法的pythoner,必须清楚x等于None, False, 空字符串””, 0, 空列表[], 空字典{}, 空元组()时对你的判断没有影响才行。 而对于if x is not None和if not x is None写法,很明显前者更清晰,而后者有可能使读者误解为if (not x) is None,因此推荐前者,同时这也是谷歌推荐的风格 结论: if x is not None是最好的写法,清晰,不会出现错误,以后坚持使用这种写法。
【:star:】 使用if not x这种写法的前提是:必须清楚x等于None, False, 空字符串””, 0, 空列表[], 空字典{}, 空元组()时对你的判断没有影响才行。
W = 50 w = [10, 30, 20] p = [60, 100, 120] value = 0 result = [0] * len(w)
v = [] for i inrange(len(w)): v.append(p[i]/w[i])
for j inrange(len(w)): for i inrange(j+1, len(w)): if v[j] < v[i]: v[j], v[i] = v[i], v[j] w[j], w[i] = w[i], w[j] p[j], p[i] = p[i], p[j]
i = 0 while W > 0: temp = min(W, w[i]) result[i] = temp / w[i] i += 1 W -= temp
for i inrange(len(result)): if result[i] == 1: print('weight:%f, total value:%f-->100%%' % (w[i], p[i])) value += p[i] elif result[i] == 0: print('weight:%f, total value:%f-->0%%' % (w[i], p[i])) else: print('weight:%f, total value:%f-->%f' % (w[i], p[i], result[i]*100)) value += p[i]*result[i]
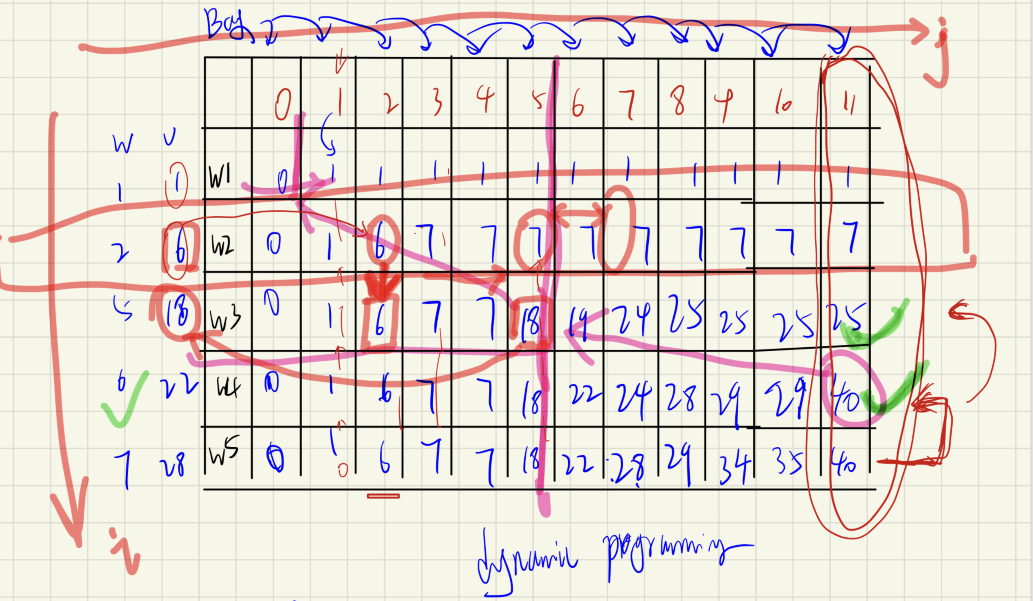
N = 5# 设定商品的种类 W = 11# 设定背包的最大载重量 w = [0, 1, 2, 5, 6, 7] # 商品的载重,不使用 w[0] v = [0, 1, 6, 18, 22, 28] # 商品的价值,不使用 v[0] # 二维列表,记录统计数据 result = [[0]*(W+1) for _ inrange(len(w))] # 动态规划算法解决01背包问题
# 逐个遍历每个商品 for i inrange(1, N+1): # 求出从 1 到 W 各个载重对应的最大收益 for j inrange(1, W+1): # 如果背包载重小于商品总重量,则该商品无法放入背包,收益不变 if j < w[i]: result[i][j] = result[i-1][j] else: # 比较装入该商品和不装该商品,哪种情况获得的收益更大,记录最大收益值 result[i][j] = max(result[i-1][j], v[i]+result[i-1][j-w[i]]) print(result) print("背包可容纳重量为 %d,最大收益为 %d" % (W, result[N][W]))
# 追溯选中的商品 n = N bagw = W # 逐个商品进行判断 print("所选商品为:") while n > 0: # 如果在指定载重量下,该商品对应的收益和上一个商品对应的收益相同,则表明未选中 if result[n][bagw] == result[n-1][bagw]: n = n - 1 else: # 输出被选用商品的重量和价值 print("(%d,%d) " % (w[n], v[n])) # 删除被选用商品的载重量,以便继续遍历 bagw = bagw - w[n] n = n - 1
N = 5 W = 11 w = [0, 1, 2, 5, 6, 7] v = [0, 1, 6, 18, 22, 28]
result = [[0]*(W+1) for _ inrange(N+1)]
for i inrange(1, N+1): for j inrange(1, W+1): if j < w[i]: result[i][j] = result[i-1][j] else: result[i][j] = max(result[i-1][j], v[i]+result[i-1][j-w[i]])
print('bag`s weight:%d, total value:%d' % (W, result[N][W]))
print('The selected products are:') n = N bagw = W while n > 0: if result[n][bagw] == result[n-1][bagw]: n -= 1 else: print('({}, {})'.format(w[n], v[n])) bagw -= w[n] n -= 1
>>> L = [x * x for x inrange(10)] >>> L [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> g = (x * x for x inrange(10)) >>> g <generator object <genexpr> at 0x1022ef630>
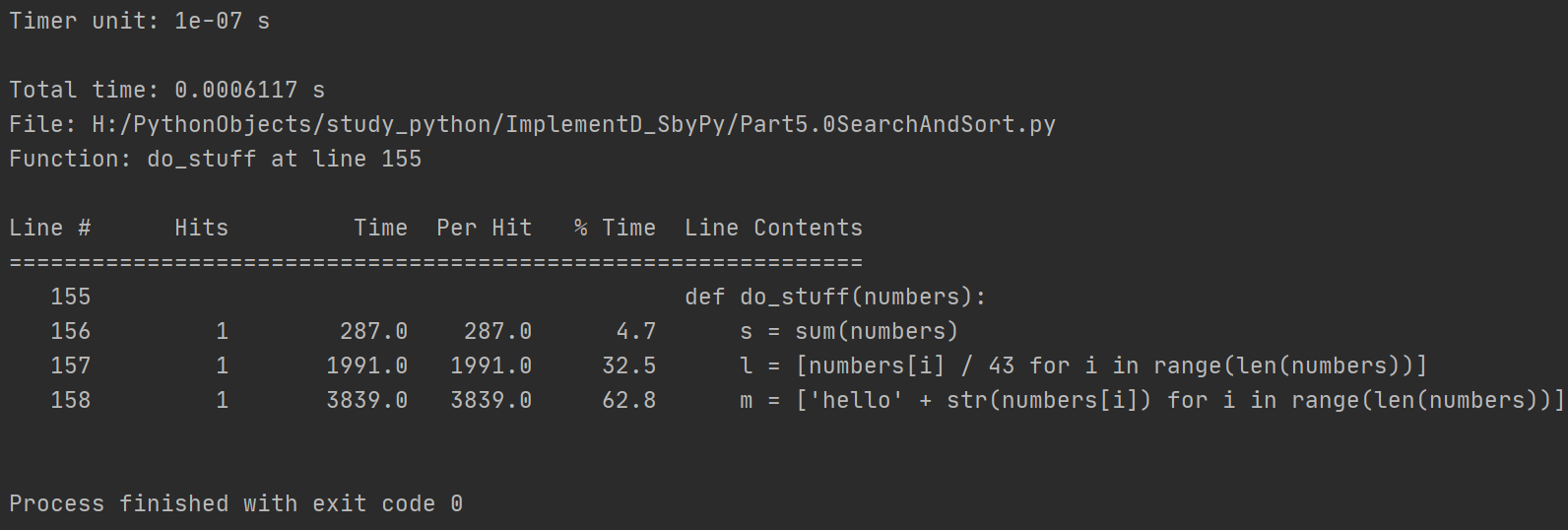
defdo_stuff(numbers): s = sum(numbers) l = [numbers[i] / 43for i inrange(len(numbers))] m = ['hello' + str(numbers[i]) for i inrange(len(numbers))] numbers = [i for i inrange(1000)]
and exec not assert finally or break for pass class from print continue global raise def if return del import try elif in while else is with except lambda yield